Rabbitmq-Peer Discovery on AWS (EC2)
AWS上的对等发现(EC2)
aws(ec2)特定发现机制可以通过插件获得,它为节点提供了两种发现其对等点的方法:
1.使用ec2实例标记
2.使用aws自动标度组成员
这两种方法都依赖于aws特定的API,因此无法在其他IaaS环境中工作。
一旦检索到集群成员实例列表,最终节点名称使用实例主机名或IP地址计算。
使用AWS对等发现机制时,节点将延迟启动以获取随机选择的值,以降低初始群集形成期间竞争条件的可能性。
1.创建角色和Accesskey
在aws平台创建一个角色绑定一个用户,具体步骤不演示,角色权限如下图:
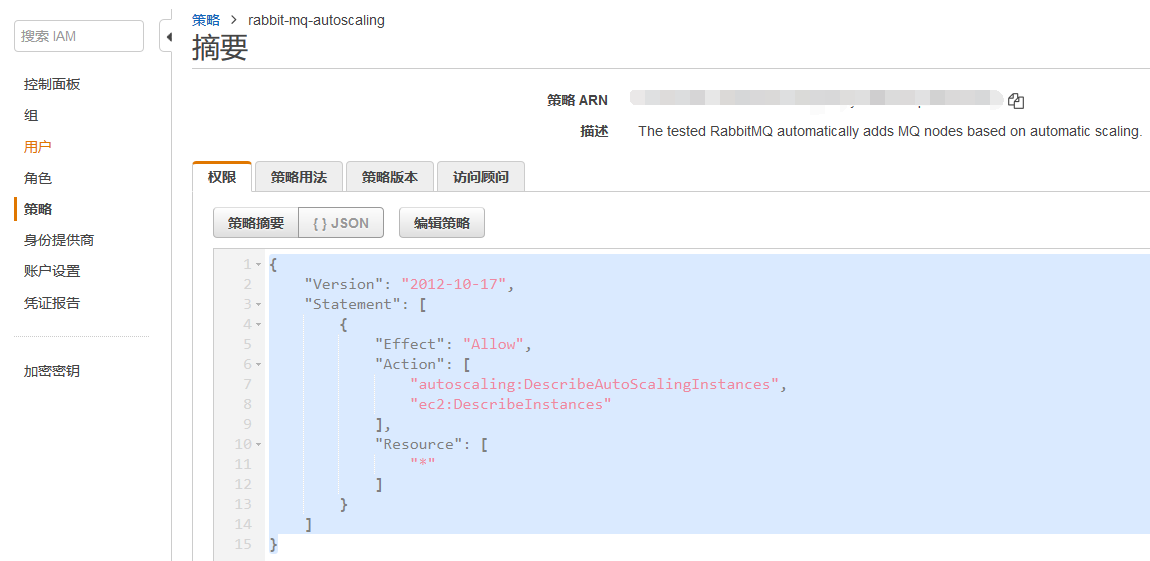
内容:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"autoscaling:DescribeAutoScalingInstances",
"ec2:DescribeInstances"
],
"Resource": [
"*"
]
}
]
}
为上述角色绑定的用户创建访问密钥:

请妥善保管密钥下面将使用密钥等信息
2.Rabbitmq部署
准备搭建Rabbitmq的镜像和机器,因为此对等发现只针对AWS-EC2,所以选用AWS的镜像
启动实例选择镜像:
3.配置AWS CLI
对等发现机制及aws内部服务调用很多都是通过aws cli去调用API执行的,此步很重要。
aws configure
根据提示输入:
AWS Access Key ID、密码、可用区、输出格式,这里的access key 信息就是之前在用户界面创建的。
4.安装Erlang
vim /etc/yum.repos.d/rabbitmq-erlang.repo [rabbitmq-erlang] name=rabbitmq-erlang baseurl=https://dl.bintray.com/rabbitmq/rpm/erlang/20/el/7 gpgcheck=1 gpgkey=https://www.rabbitmq.com/rabbitmq-release-signing-key.asc repo_gpgcheck=0 enabled=1 yum install erlang -y
5.安装Rabbitmq-server
wget https://dl.bintray.com/rabbitmq/all/rabbitmq-server/3.7.6/rabbitmq-server-3.7.6-1.el7.noarch.rpm rpm --import https://dl.bintray.com/rabbitmq/Keys/rabbitmq-release-signing-key.asc yum install rabbitmq-server-3.7.6-1.el7.noarch.rpm -y
6.启动插件并设计Rabbitmq开机启动
rabbitmq-plugins --offline enable rabbitmq_peer_discovery_aws #aws对等发现插件(一定在启动rabbitmq之前启动) rabbitmq-plugins enable rabbitmq_management (管理插件) systemctl enable rabbitmq-server
7.修改Rabbitmq可用guest登录方式
vim /usr/lib/rabbitmq/lib/rabbitmq_server-3.7.6/ebin/rabbit.app
#修改39行把[]里的内容去掉,修改后的结果如下:
{loopback_users, []},
8.优化系统限制
运行生产工作负载的RabbitMQ安装可能需要系统限制和内核参数调整,以便处理更多的并发连接和队列。需要调整的主要设置是打开文件的最大数量,ulimit -n
许多操作系统上的默认值太低(例如,在几个Linux发行版上为1024),个人建议在生产环境中为用户rabbitmq至少允许65536个文件描述符。
有两个限制操作系统内核允许的最大打开文件数(fs.file-max)和每个用户限制(ulimit -n),前者必须高于后者
fs.file-max设置
echo 'fs.file-max = 65535' >> /etc/sysctl.conf
解除 Linux 系统的最大进程数和最大文件打开数限制
cat /etc/security/limits.conf root soft nofile 65535 root hard nofile 65535 * soft nofile 65535 * hard nofile 65535 ##以上4行在文档末尾添加 ===================================== #为了避免重启失效,加入rc.local echo 'ulimit -SHn 65535' > /etc/rc.local
rabbitmq-server配置
sed -i '11a LimitNOFILE=20000' /etc/systemd/system/multi-user.target.wants/rabbitmq-server.service 在[Service]模块中添加LimitNOFILE=20000 (具体参数根据需求调整)
systemctl daemon-reload 修改完Rabbitmq服务需要重新加载服务
9.修改.erlang.cookie 权限
cd /var/lib/rabbitmq/ && chown rabbitmq.rabbitmq .erlang.cookie
默认安装完服务属主属组都是root,在启动rabbitmq时会报错,所以在启动前先修改一下,另外对等发现注册依赖于.erlang.cookie 所以注册节点必须和主节点的 cookie值必须一致,
我们制作成镜像应用autoscaling自行扩展所以就不会存在cooke不一致的问题了。
10.Rabbitmq配置文件
vim /etc/rabbitmq/rabbitmq.conf #1.这部分设置了access_key等相关信息和告诉Rabbitmq后端的对等发现模式是 autoscaling_grou cluster_formation.peer_discovery_backend = rabbit_peer_discovery_aws cluster_formation.aws.region = us-east-1 cluster_formation.aws.access_key_id = AKIAIMYGK********* cluster_formation.aws.secret_key = d9O6apD/Vyc9t********************* cluster_formation.aws.use_autoscaling_group = true #2.这部分设置了rabbitmq的一些基本优化 listeners.tcp.default = 5672 #要侦听AMQP连接的端口或主机名 vm_memory_high_watermark.relative = 0.8 #触发流控制的内存阈值。可以是绝对的,也可以是相对于操作系统可用的RAM数量 cluster_partition_handling = pause_minority #如何处理网络分区,默认值为ignore loopback_users = none #允许默认来宾用户远程连接 需要修改为none 默认值为localhost heartbeat = 60 #表示服务器在connection.tune帧中发送的心跳延迟(以秒为单位)的值。如果设置为0,则禁用心跳,禁用心跳可能会在具有大量连接的情况下提高性能,但可能会导致在存在关闭非活动连接的网络设备时连接中断。 vm_memory_high_watermark_paging_ratio = 0.75 #队列开始将消息分页到磁盘以释放内存的高水位限制的分数 disk_free_limit.absolute = 2GB #RabbitMQ存储数据的分区的磁盘可用空间限制。当可用磁盘空间低于此限制时,将触发流量控制。该值可以相对于RAM总量设置,也可以设置为绝对值(以字节为单位),或者以信息单位(例如“50MB”或“5GB”)设置 collect_statistics = coarse #统计收集模式。主要与管理插件相关 这里选择粗略统计 collect_statistics_interval = 2500 #统计信息收集间隔(毫秒)。主要与管理插件相关。单位:毫秒 queue_master_locator = random #队列master策略,默认值:client-local 这里选择随机 cluster_keepalive_interval = 2500 #节点应该多长时间向其他节点发送keepalive消息(以毫秒为单位)。请注意,这与net_ticktime不同;错过的keepalive消息不会导致节点被视为关闭。 hipe_compile = true #设置为true以使用HiPE预编译RabbitMQ的部分,HiPE是Erlang的即时编译器。这将以增加启动时间为代价来增加服务器吞吐量。您可能会在启动时延迟几分钟后看到20-50%的性能提升。这些数字与工作负载和硬件有很大关系。 #3.管理插件的一些优化参数 management.sample_retention_policies.global.minute = 5 management.sample_retention_policies.global.hour = 60 management.sample_retention_policies.global.day = 1200 management.sample_retention_policies.basic.minute = 5 management.sample_retention_policies.basic.hour = 60 management.sample_retention_policies.detailed.10 = 5
11.启动Rabbitmq-server
systemctl start rabbitmq-server
12.封装镜像
在安装rabbitmq的创建AMI镜像,通过此镜像创建启动配置,创建auto scaling组验证结果
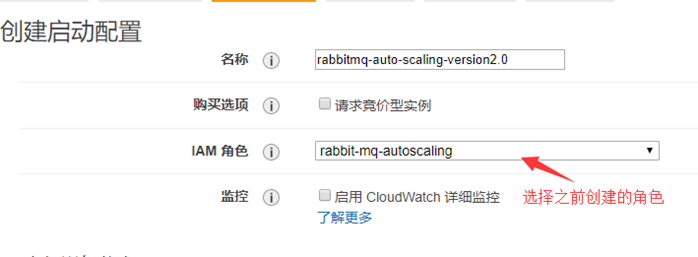
13.创建启动配置和Auto Scaling组
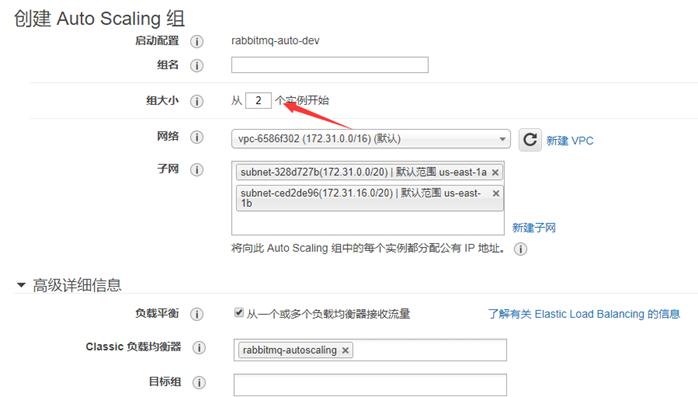
注意创建Auto Scaling组的安全组的时候,相关端口要设置允许,否则影响对等发现
组大小设置为2,为了验证Auto Scaling创建的2个实例是否可以完成自动发现,自动注册并形成集群
登录机器验证:
[root@ip-172-31-11-83 ~]# rabbitmqctl cluster_status
Cluster status of node rabbit@ip-172-31-11-83 ...
[{nodes,[{disc,['rabbit@ip-172-31-11-83','rabbit@ip-172-31-25-160']}]},
{running_nodes,['rabbit@ip-172-31-25-160','rabbit@ip-172-31-11-83']},
{cluster_name,<<"rabbit@ip-172-31-11-83.ec2.internal">>},
{partitions,[]},
{alarms,[{'rabbit@ip-172-31-25-160',[]},{'rabbit@ip-172-31-11-83',[]}]}]
经过查看通过AutoScaling创建的2个主机自动注册发现实验成功,这样后续配合监控等相关信息,可以基于封装好AMI自动扩容,缩容了。