Selenium文档
Selenium是一个Web的自动化测试工具,最初是为网站自动化测试而开发的,类型像我们玩游戏用的按键精灵,可以按指定的命令自动操作,不同是Selenium 可以直接运行在浏览器上,它支持所有主流的浏览器(包括PhantomJS这些无界面的浏览器)。
Selenium 可以根据我们的指令,让浏览器自动加载页面,获取需要的数据,甚至页面截屏,或者判断网站上某些动作是否发生。
Selenium 自己不带浏览器,不支持浏览器的功能,它需要与第三方浏览器结合在一起才能使用。但是我们有时候需要让它内嵌在代码中运行,所以我们可以用一个叫 PhantomJS 的工具代替真实的浏览器。
PhantomJS
PhantomJS 是一个基于Webkit的“无界面”(headless)浏览器,它会把网站加载到内存并执行页面上的 JavaScript,因为不会展示图形界面,所以运行起来比完整的浏览器要高效。
如果我们把 Selenium 和 PhantomJS 结合在一起,就可以运行一个非常强大的网络爬虫了,这个爬虫可以处理 JavaScrip、Cookie、headers,以及任何我们真实用户需要做的事情。
PhantomJS已经弃用,chrome用chromedriver代替
chromedriver下载地址
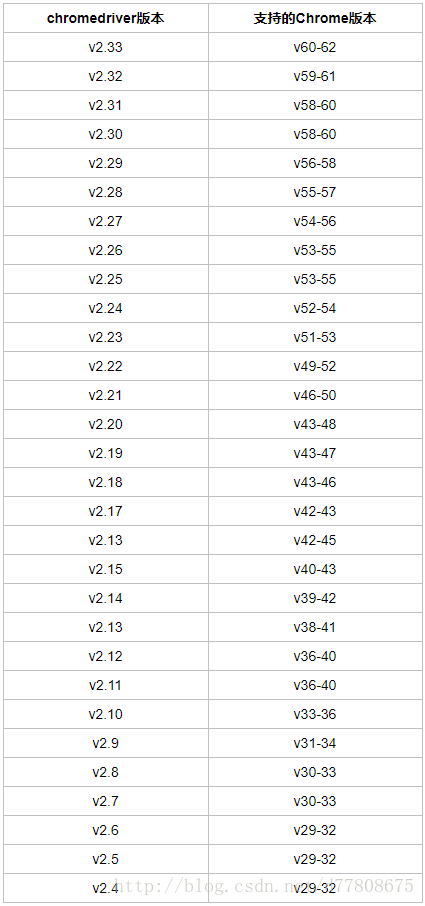
注意 :chromedriver的版本要与你使用的chrome版本对应,对应关系如下:
下载完成后:
windows 下,新建一个命名为chromedriver文件夹,将解压的chromedriver.exe放进文件夹,再配置进path环境变量
Linux下,把下载好的文件放在 /usr/bin 目录下就可以了。
分享一个selenium中经常会有人遇到的坑
selenium.common.exceptions.StaleElementReferenceException: Message: stale element reference: element is not attached to the page document
问:“我循环去点击一列链接,但是只能点到第一个,第二个就失败了,为什么?”。
原因就在这里:你点击第二个时已经是新页面,当然找不到之前页面的元素。
问:“可是明明元素就在那里,没有变,甚至我是回退回来的,页面都没有变,怎么会说是新页面?”。
这个就需要你明白页面长得一样不代表就是同一张页面,就像两个人长得一样不一定是同一个人,他们的身份证号不同。
页面,甚至页面上的元素都是有自己的身份证号(id)的。
解决办法:
目前只能sleep一下,让爬虫先把当前页面的内容爬完,再去跳转下一页吧。实则有效。
Selenium 库里有个叫 WebDriver 的 API。WebDriver 有点儿像可以加载网站的浏览器,但是它也可以像 BeautifulSoup 或者其他 Selector 对象一样用来查找页面元素,与页面上的元素进行交互 (发送文本、点击等),以及执行其他动作来运行网络爬虫。
案例一:斗鱼直播房间数据统计
源码下载,将源码仍进PyCharm直接运行即可
源码分析
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import unittest
from selenium import webdriver
from bs4 import BeautifulSoup as bs
from selenium.webdriver.chrome.options import Options
import time
class douyu(unittest.TestCase):
# 初始化方法,必须是setUp()
def setUp(self):
# 配置自动化浏览器
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
chrome_options.add_argument('--shm-size=1g')
self.driver = webdriver.Chrome(chrome_options=chrome_options)
# self.driver = webdriver.Chrome()
self.num = 0
self.count = 0
# 测试方法必须有test字样开头
def testDouyu(self):
self.driver.get("https://www.douyu.com/directory/all")
while True:
soup = bs(self.driver.page_source, "lxml")
# 房间名, 返回列表
names = soup.find_all("h3", {"class" : "ellipsis"})
# 观众人数, 返回列表
numbers = soup.find_all("span", {"class" :"dy-num fr"})
# zip(names, numbers) 将name和number这两个列表合并为一个元组 : [(1, 2), (3, 4)...]
for name, number in zip(names, numbers):
print (u"观众人数: -" + number.get_text().strip() + u"- 房间名: " + name.get_text().strip() )
self.num += 1
#self.count += int(number.get_text().strip())
time.sleep(0.2)
# 如果在页面源码里找到"下一页"为隐藏的标签,就退出循环
if self.driver.page_source.find("shark-pager-disable-next") != -1:
break
# 一直点击下一页
self.driver.find_element_by_class_name("shark-pager-next").click()
# 测试结束执行的方法
def tearDown(self):
# 退出PhantomJS()浏览器
print ("当前网站直播人数" + str(self.num) )
print ("当前网站观众人数" + str(self.count) )
self.driver.quit()
if __name__ == "__main__":
# 启动测试模块
unittest.main()
案例二:煎蛋妹子图爬取
由于煎蛋的妹子图实在太多人爬取,所以网站做了一点反爬虫处理,所以要爬取不能想爬百度贴吧那么简单,必须使用Selenium与chromedriver的方式来爬取
源码下载,将源码仍进PyCharm直接运行即可
源码分析
# -*- coding:utf-8 -*-
# Author:shifu204
import urllib.request
import urllib.parse
from lxml import etree
from selenium import webdriver
from bs4 import BeautifulSoup
import requests
from selenium.webdriver.chrome.options import Options
def loadPage(url):
"""
作用:根据url发送请求,获取服务器响应文件
url: 需要爬取的url地址
"""
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
chrome_options.add_argument('--shm-size=1g')
driver = webdriver.Chrome(chrome_options=chrome_options)
driver.get(url)
img_url = []
path = "G:/mm/" # 保存图片的路径
data = driver.page_source
soup = BeautifulSoup(data, "lxml")
images = soup.select("a.view_img_link")
print(images)
for image in images:
dynamic = image.get('href')
# if str('gif') in str(dynamic): # 去除gif
# pass
# else:
http_url = "http:" + dynamic
img_url.append(http_url)
# print("http:%s" % dynamic)
for j in img_url:
r = requests.get(j)
print('正在下载 %s' % j)
with open(path + j[-15:], 'wb')as jpg:
jpg.write(r.content)
def tiebaSpider(url, beginPage, endPage):
"""
beginPage : 起始页
endPage : 结束页
"""
for page in range(beginPage, endPage + 1):
#filename = "第" + str(page) + "页.html"
fullurl = url + "/page-" + str(page) + "#comments"
# print (fullurl)
loadPage(fullurl)
#print (html)
print("谢谢使用")
if __name__ == "__main__":
kw = input("请输入需要爬取的内容: 1-搞笑,2-美女 :")
if kw == '1':
k = 'pic'
else:
k = 'ooxx'
beginPage = int(input("请输入起始页:"))
endPage = int(input("请输入结束页:"))
# url = "http://jandan.net/pic/page-230#comments"
url = "http://jandan.net/"
fullurl = url + k
# print(fullurl)
tiebaSpider(fullurl, beginPage, endPage)
案例三:优酷羽毛球教学视频链接批量爬取
这个纯粹个人爱好,优酷某些带版权的视频不能在客户端下载,然后,你懂的~~
将你关注频道的链接复制下来,例如下面这个

源码下载,将源码仍进PyCharm直接运行即可
源码分析
# -*- coding:utf-8 -*-
# Author:shifu204
import urllib.request
import urllib.parse
from lxml import etree
from selenium import webdriver
from bs4 import BeautifulSoup
import requests
from selenium.webdriver.chrome.options import Options
def loadPage(url):
"""
作用:根据url发送请求,获取服务器响应文件
url: 需要爬取的url地址
"""
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
chrome_options.add_argument('--shm-size=1g')
driver = webdriver.Chrome(chrome_options=chrome_options)
driver.get(url)
# 点击视频链接
# divs = driver.find_elements_by_class_name("v-link")
# for links in divs:
# links.click()
data = driver.page_source
soup = BeautifulSoup(data, "lxml")
video_urls = soup.select("div.v-link > a")
for video_url in video_urls:
# video_url.click()
dynamic = video_url.get('href')
http_url = "https:" + dynamic
# img_url.append(http_url)
print(http_url)
def tiebaSpider(url, beginPage, endPage):
"""
beginPage : 起始页
endPage : 结束页
"""
for page in range(beginPage, endPage + 1):
fullurl = url + str(page) + ''
# print (fullurl)
loadPage(fullurl)
#print (html)
print("谢谢使用")
if __name__ == "__main__":
beginPage = int(input("请输入起始页:"))
endPage = int(input("请输入结束页:"))
# 关注频道页面的url黏贴到这里
fullurl = "http://i.youku.com/i/UNDIyMzkyNDMy/videos?spm=a2hzp.8253869.0.0&order=1&page="
# print(fullurl)
tiebaSpider(fullurl, beginPage, endPage)