第一次写博客
首先了解一下关于这些:
Paramiko 模块:
知道Paramiko之前应先学习一下在linux下的文件传输 ,利用scp 命令
例如有两个地址192.168.60.128,192.168.60.129
在128中可以登录129,通过 ssh 用户名@地址 -p端口号 例如:ssh root@192.168.60.128 -p22 便可以登陆到这个地址的这个账户上去,利用Ifconfig命令可以查看
当前的地址到底是哪一个
scp -rp -P端口号 文件名 用户名@地址 例如:scp -rp -P22 file.txt root@192.168.60.129:/tmp/ (这样就实现了将文件传到129的tmp下)
在python中 利用 Paramiko模块实现了 利用ssh发送命令,利用ftp 上传和下载文件 实现了简单交互
ssh:
import paramiko #创建一个ssh对象 ssh=paramiko.SSHClient() #连接服务器 ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy()) # 连接服务器 ssh.connect(hostname='', port=22, username='mark', password='') #执行命令 stdin,stdout,stderr=ssh.exec_command("df") res,err=stdout.read(),stderr.read() result=res if res else err print(result.decode()) ssh.close()
ftp:
import paramiko transport=paramiko.Transport((" ",22)) transport.connect(username="mark",password=" ") sftp=paramiko.SFTPClient.from_transport(transport) """实现了将aa这个文件上传到linux的/tmp/下""" #sftp.put('aa','/tmp/test_from_win') """实现了将av这个文件从Linux下载下来""" #注意上传,与下载来的文件的路径默认都在代码所在的文件夹中 sftp.get("/tmp/av","from_linux") transport.close()
上面的实现其实都是通过了密码认证,其实这种认证很不安全,所以我们有一种方式不通过密码可以直接认证登陆以及传输文件,这种方法就是RSA- 非对称密钥验证
原理:我们有一个公钥(pubic key) ,还有一个私钥(private key)。实现的方式就是将自己的公钥传输给另一个人,放在某人的目录下,就可以访问对应的目录内容,(切记私钥是自己的,不能轻易传给别人)
流程(首先我们在linux演示下这种方法):
1.cd .ssh/ #切换到ssh目录下
2.ssh -keygen 生成私钥和公钥
3.ssh -copy -id "-p22 root@192.168.60.129" #这样我们就实现了将公钥传给129的root,获取了登陆129的权限
4.ssh root@192.168.60.129 -p22 #检测登陆是否还需要密码
在Python中 :
我们通过paramiko模块也可以实现这样的功能
import paramiko #这个是发送文件的用户的私钥,文件的下载在linux下掉用 sz ~/.ssh/id_rsa 实现了下载 之后把他放在与代码同一文件夹下即可使用 private_key = paramiko.RSAKey.from_private_key_file('id_rsa.txt') # 创建SSH对象 ssh = paramiko.SSHClient() # 允许连接不在know_hosts文件中的主机 ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy()) # 连接服务器 ssh.connect(hostname=', port=22, username='root', pkey=private_key) # 执行命令 stdin, stdout, stderr = ssh.exec_command('df') result = stdout.read() print(result.decode()) # 关闭连接 ssh.close()
进程的定义:
程序并不能单独运行,只有将程序装载到内存中,系统为它分配资源才能运行,而这种执行的程序就称之为进程。程序和进程的区别就在于:程序是指令的集合,它是进程运行的静态描述文本;进程是程序的一次执行活动,属于动态概念。
在多道编程中,我们允许多个程序同时加载到内存中,在操作系统的调度下,可以实现并发地执行。这是这样的设计,大大提高了CPU的利用率。进程的出现让每个用户感觉到自己独享CPU,因此,进程就是为了在CPU上实现多道编程而提出的
有了进程为什么还要线程?
进程有很多优点,它提供了多道编程,让我们感觉我们每个人都拥有自己的CPU和其他资源,可以提高计算机的利用率。很多人就不理解了,既然进程这么优秀,为什么还要线程呢?其实,仔细观察就会发现进程还是有很多缺陷的,主要体现在两点上:
-
进程只能在一个时间干一件事,如果想同时干两件事或多件事,进程就无能为力了。
-
进程在执行的过程中如果阻塞,例如等待输入,整个进程就会挂起,即使进程中有些工作不依赖于输入的数据,也将无法执行。
例如,我们在使用qq聊天, qq做为一个独立进程如果同一时间只能干一件事,那他如何实现在同一时刻 即能监听键盘输入、又能监听其它人给你发的消息、同时还能把别人发的消息显示在屏幕上呢?你会说,操作系统不是有分时么?但我的亲,分时是指在不同进程间的分时呀, 即操作系统处理一会你的qq任务,又切换到word文档任务上了,每个cpu时间片分给你的qq程序时,你的qq还是只能同时干一件事呀。
再直白一点, 一个操作系统就像是一个工厂,工厂里面有很多个生产车间,不同的车间生产不同的产品,每个车间就相当于一个进程,且你的工厂又穷,供电不足,同一时间只能给一个车间供电,为了能让所有车间都能同时生产,你的工厂的电工只能给不同的车间分时供电,但是轮到你的qq车间时,发现只有一个干活的工人,结果生产效率极低,为了解决这个问题,应该怎么办呢?。。。。没错,你肯定想到了,就是多加几个工人,让几个人工人并行工作,这每个工人,就是线程!
多线程:
多线程有很多的优点,最主要的是他支持多并发,就是几个任务的同时执行,提高了任务的执行效率
下面为多线程的使用例子:
import threading #设置一个函数 def run(n): print("task ",n ) for i in range(50): #循环50次,实际上是50个任务同时并发执行,注意args的元组类型 t = threading.Thread(target=run,args=("t-%s" %i ,)) t.start() print("----------all threads has finished...")
主线程与子线程:
在上面的例子中我们可以把整个整体,当作一个线程,print的那部分我们称之为主线程,在循环中我们设置的线程我们称作子线程(我们可以在某一段打印一下threading.current_thread 来测试一下 这个部分是子线程还是主线程)
通过下面的这一段代码深入理解一下主线程与子线程的关系,通过执行这段代码你会发现,主线程未等子线程全部执行完之后便执行自身的内容后再继续执行子线程
如果我们将run中的sleep去掉的话,也会出现顺序紊乱的情况,所以我理解两个线程的运行的过程中并未有什么关系,我们可以通过 for i in t_list: i.join() 这段代码
实现线程等待,循环的去等待第一个每一子个线程的结束后,我们在执行主线程来实现一种顺序关系
import threading import time def run(n): print("task:%s"%n,threading.current_thread()) time.sleep(2) print("task done :%s"%n,threading.current_thread()) start_time=time.time() t_list=[] for i in range (20): t=threading.Thread(target=run,args=("a1 %i"%i,)) t.start() t_list.append(t) #for i in t_list: # i.join() print("ok".center(50,"-")) print("it costs time %s"%(time.time()-start_time),threading.current_thread())
守护线程:
守护线程拥有一个性质,一旦主线程结束后,只要没有非守护线程直接会结束程序。
例子:
import threading import time def run(n): print("task ",n ) time.sleep(2) print("task done",n,threadin start_time = time.time() t_objs = [] #存线程实例 for i in range(50): t = threading.Thread(target=run,args=("t-%s" %i ,)) t.setDaemon(True) #把当前线程设置为守护线程 t.start() t_objs.append(t) #为了不阻塞后面线程的启动,不在这里join,先放到一个列表里 print("----------all threads has finished...",threading.current_thread(),threading.active_count())
通过这段代码我们会发现,sleep后的print并没有执行,这就是守护线程的性质(并发执行后执行到主线程后面的守护线程无论有没有都不会执行了)
注意,setDaemon这个代码必须放在线程实例化与start之间,否则会报错!!!!!
Python GIL(Global Interpreter Lock):
全局解释器锁,这可以说的上是Python的一个缺陷,在Python中,无论你有多少个线程,多少个CPU在同一时刻,只能支持一个线程运行,而且所在的CPU也是随机的
但是说GIL是Python的一个缺陷是不准确的,实际上GIL是CPython的一个缺陷,类似如JPython中就无此特点。
线程锁(互斥锁Mutex):
我们知道一个进程下可以执行多个线程,根据多线程的性质,多个线程实际共享同一块内存空间,那么问题来了,如果多个线程要修改同一组数据,那么我们要怎么办呢?我们首先要理解发生这个问题的原理:
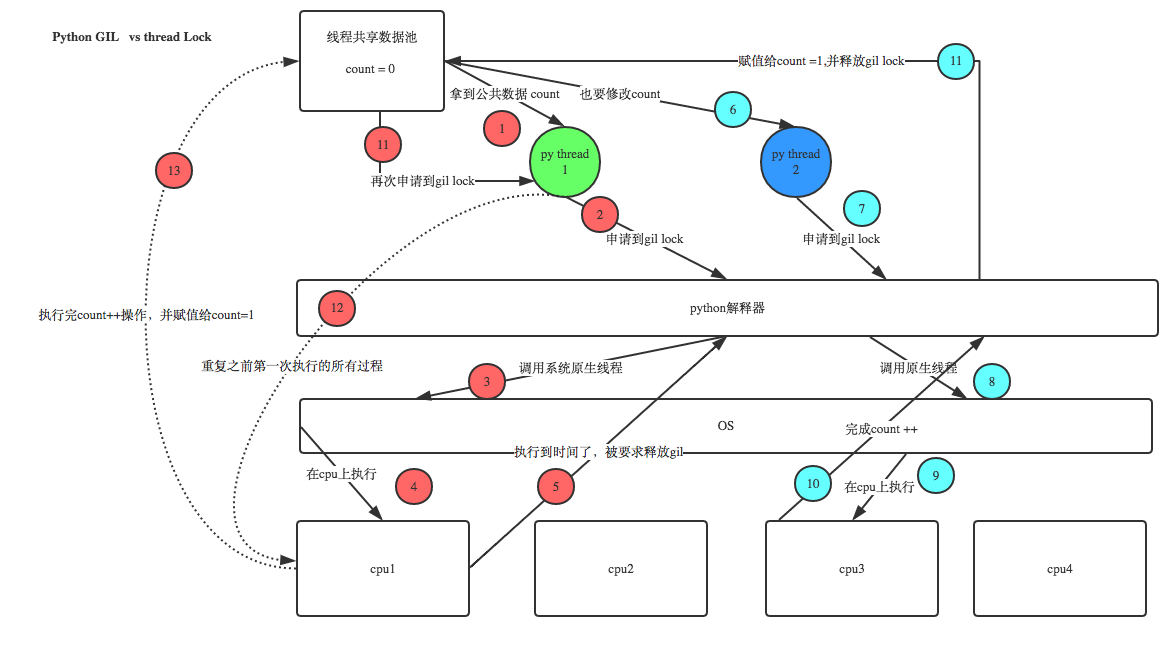
这个锁有效的解决了数据重叠问题,它规定了线程的执行顺序,如果此线程未执行完,就不会有下一个线程进行。注意一问题,就是锁住之后执行命令后立即释放锁,否则我们将会将并行变为串行,引来一堆不不必要的问题!!!
import threading import time def run(n): lock.acquire() global num num +=1 lock.release() #先构建一个实例 lock = threading.Lock() num = 0 t_objs = [] #存线程实例 for i in range(50): t = threading.Thread(target=run,args=("t-%s" %i ,)) t.start() t_objs.append(t) #为了不阻塞后面线程的启动,不在这里join,先放到一个列表里 for t in t_objs: #循环线程实例列表,等待所有线程执行完毕 t.join() print("----------all threads has finished...",threading.current_thread(),threading.active_count()) print("num:",num)
但是现在我们又有了一个问题就是如果有多个锁的话,我们会出现锁死的情况,我们怎么才会不让他锁死
import threading, time def run1(): print("grab the first part data") lock.acquire() global num num += 1 lock.release() return num def run2(): print("grab the second part data") lock.acquire() global num2 num2 += 1 lock.release() return num2 def run3(): lock.acquire() res = run1() print('--------between run1 and run2-----') res2 = run2() lock.release() print(res, res2) num, num2 = 0, 0 lock = threading.RLock() for i in range(1): t = threading.Thread(target=run3) t.start() while threading.active_count() != 1: print(threading.active_count()) else: print('----all threads done---') print(num, num2)
我们引入一个新的概念叫递归锁,lock = threading.RLock() ,这种锁的实质就想把所有的锁放进一个字典中,所需要哪把锁,就去把对应的锁拿出来
线程之信号量:
上文提到了线程锁,我们限定在一个线程未执行得到结果时不执行下一个线程,如果我们要将每隔多个线程用锁去锁住要怎么办?那么这时候我们就用到了信号量
import threading, time def run(n):
#实际跟线程锁类似,写法只在Main函数那里略有区别,区别就是限定了量的执行 semaphore.acquire() time.sleep(1) print("run the thread: %s " % n) semaphore.release() if __name__ == '__main__': semaphore = threading.BoundedSemaphore(5) # 最多允许5个线程同时运行 for i in range(22): t = threading.Thread(target=run, args=(i,)) t.start() while threading.active_count() != 1: #这个是判断主线程与子线程,threading.active_count==1为主线程,!=1时则为子线程 pass # print threading.active_count() else: print('----all threads done---') #print(num)
线程之Event:
随着深入学习,如果我们要将两个多线程之间存在着一种关系怎么办,所以我们用到了Event来解决这个问题
以红绿灯与车的例子:
#event.set 设置了一个标志位 , event.clear 会将标志位清空,而event.wait就是用来等待set出现才会继续执行
import time import threading event = threading.Event() def lighter(): count = 0 event.set() #先设置绿灯 while True: if count >5 and count < 10: #改成红灯 event.clear() #把标志位清了 print("�33[41;1mred light is on....�33[0m") elif count >10: event.set() #变绿灯 count = 0 else: print("�33[42;1mgreen light is on....�33[0m") time.sleep(1) count +=1 def car(name): while True: if event.is_set(): #代表绿灯 print("[%s] running..."% name ) time.sleep(1) else: print("[%s] sees red light , waiting...." %name) event.wait() print("�33[34;1m[%s] green light is on, start going...�33[0m" %name) light = threading.Thread(target=lighter,) light.start() car1 = threading.Thread(target=car,args=("Tesla",)) car1.start()
线程之队列:
值得注意的一点就是,get的顺序是按照 put的序号 执行,put 以是以元组类型放进去
import queue q = queue.PriorityQueue() q.put((-1,"a")) q.put((3,"b")) q.put((10,"c")) q.put((6,"d")) print(q.get()) print(q.get()) print(q.get()) print(q.get())