IO----文件操作,读操作
1、open('文件名','打开方式',mode[buff]);------------->第一个参数是文件路径,第二个参数是打开方式(如果不写,默认是只读),第三个(可选)参数是设置读写文件的一个缓冲的大小 2、with open('文件名','打开方式') as f----------------------------->第一种不需要记,只需要记住这种用法就行 f.read([size]);------------------->使用read()方法读取,其中size参数是设置读写的字节大小,超过的不读取,。默认不设置就全部读取 f.readline([size]);----------------------->使用readline()方法读取,意思是只读取一行,其中size参数是设置读写的字节大小,超过的不读取。。默认不设置就全部读取
f.readlines([size(8192字节,IO下的buffer默认大小)]);[不推荐,若文件很大,会占用很大的内存空间]------------------------>使用readlines()方法读取,意思是读取文件中的每一行,并最终将每一行存入数组中返回,这样访问文件内容就可以像访问数组一样使用。 3、使用迭代器iter对文件内容进行读取【推荐】(好处:迭代器不是将内容导入内存中,而是每次在next时,自动读取下一条数据,这样可以不消耗内存的前提下对)
f=open('文件名');
liter=iter(f);-------->将文件转换成迭代器
lines=0;-------------->用来记录行数
for lines in liter:
lines+=1;----------->遍历文件,每次行数+1;
以上两种方式的结果是一样的(都是读出该文档中的所有内容为一个str对象),只不过第一种没有关闭(f.close()操作),第二种默认会有(f.close()操作),一般都用第二种方法
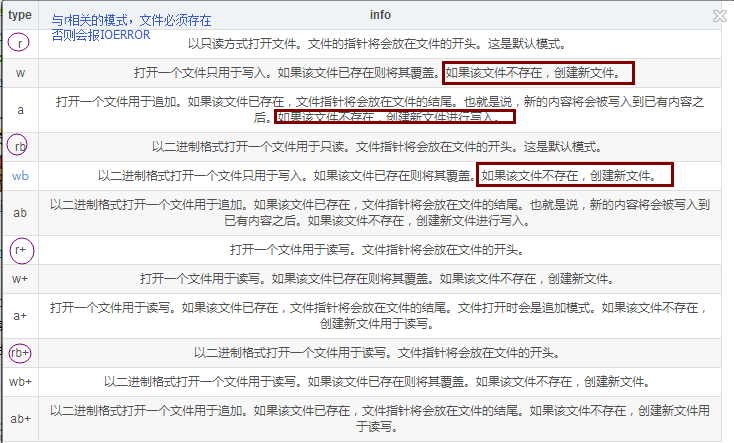
3、w模式下(只写),f.write('哈哈'),、f.writeline('的分对付对付对付')可以是列表元祖字符串[但必须是字符串所组成的序列]--------------------->这个是覆盖原内容,添加,w模式下,没有read()方法
4、a模式下(只写,追加),f.write('你好')----------------------->这个是在原内容下,在末尾增加,a模式下,没有read()方法
5、r模式下(只读),read();-------------------------------->这个是读取所有内容,以字符串输出
6、r+模式下(读写),read(),write()------------------------->最常用哒,这个写入是在原内容下,在头部添加
7、w+模式(读写),read(),write()---------------------------->这个写入跟w模式一样,都是覆盖原内容添加
8、与r相关的模式,文件必须存在,否则会报错:IOERROR
9、与w相关的模式,文件可以不存在,如果不存在,直接创建
10、与b相关的模式,都是以二进制进行读、写、读写(用途:读取一张图片)
遇到的问题:
①、SyntaxError: Non-UTF-8 code starting with 'xce' :这个是编码问题,在代码的最顶部加上【# -*- coding: utf-8 -*-】即可
②、文档中内容为【大家好】,但是使用read()打印出来是【锘垮ぇ瀹跺ソ】
检查1:目前python 的文件编码方式是【utf-8】,txt文档的编码格式也是【utf-8】,此时运行会出现②中的乱码问题
检查2:在代码中加入打开的格式,open(r'D:Users4399-3046Desktop est.txt', 'r',encoding='utf-8'),此时运行仍会报③中的错误
检查3:若把txt文档的编码格式改为其他,如【unicall】,此时运行仍会报③中的错误
检查4:修改项目的编码格式:setting---Editor-----File Encoding------都设置为【UTF-8】,此时运行仍会出现②中乱码问题
检查5:修改项目的读取方式,改为w---再改为r,就正常了,原因未知
③、UnicodeEncodeError: 'gbk' codec can't encode character 'ufeff' in position 0: illegal multibyte sequence-------从代码中可以看出肯定GBK是编码的问题
④、UnicodeDecodeError: 'gbk' codec can't decode byte 0xa1 in position 22: illegal multibyte sequence------从代码中可以看出肯定也是GBK编码的问题
尝试1:在代码中加入,忽略异常,open中加入(error='ignore')---结果不会再报上面的错误,但是会出现中文乱码,如问题②中一样-----这是解决以上办法最简单粗暴的方式

尝试2:在以上基础上,open中加入(encoding='utf8')或encoding='utf-8'后正常,展示正常
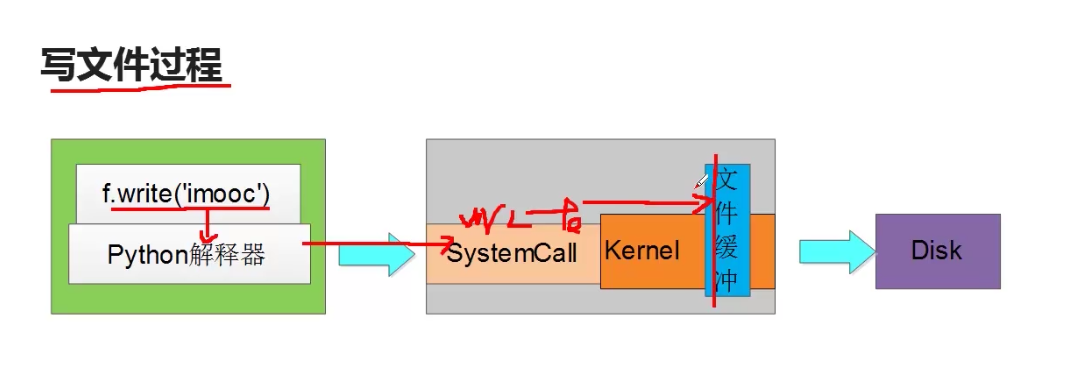
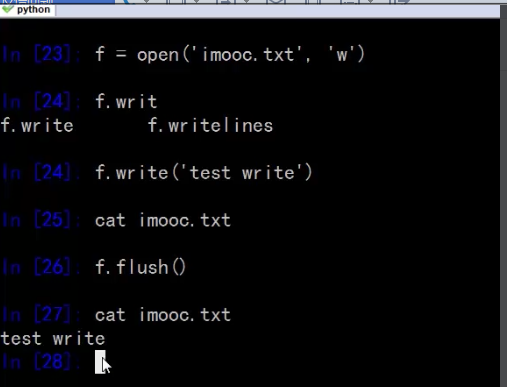
⑤、文件最后为什么一定要关闭close操作:原因一:是为了将写的内容同步到磁盘,原因二:是因为window操作系统打开的文件进程个数是有限的,原因三:如果打开的文件数达到上限,那么再次打开另一个文件是会失败的
文件文件,缓存问题
①、调用close()方法
②、