TopN的问题分为两种:一种是建是唯一的,还有是建非唯一。我们这边做的就是建是唯一的。
这里的建指得是:下面数据的第一列。
有一堆数据,想根据第一列找出里面的Top10.
如下:
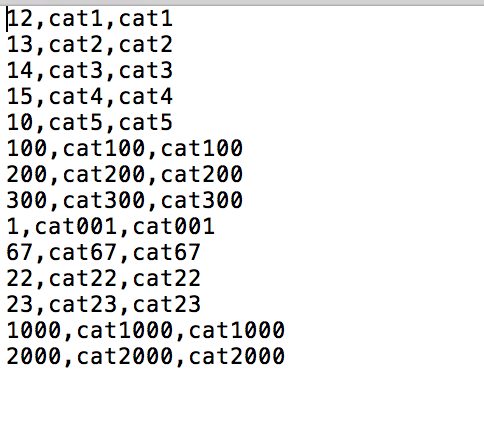
关键:在map和reduce阶段都使用了TreeMap这个数据结构,他有从小到大的排序功能,所以排第一的最小,依次增大。限定大小为10 ,只要超过十,就把排在第一个的值给删除。
代码如下:
package com.book.topn; import java.io.IOException; import java.util.Iterator; import java.util.Set; import java.util.SortedMap; import java.util.TreeMap; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class TopN { static class Mapper1 extends Mapper<LongWritable, Text, NullWritable, Text> { public SortedMap<Double, Text> top10cats = new TreeMap<Double, Text>(); public int N = 10; @Override protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, NullWritable, Text>.Context context) throws IOException, InterruptedException { String[] lines = value.toString().split(","); Double weight = Double.parseDouble(lines[0]); // 一行读完,然后把数据 top10cats.put(weight, new Text(value)); // 如果Map if (top10cats.size() > N) { top10cats.remove(top10cats.firstKey()); } } // 待执行完map的读取比较操作后,就把TreeMap里面的数据打印出来。 @Override protected void cleanup(Mapper<LongWritable, Text, NullWritable, Text>.Context context) throws IOException, InterruptedException { Set<Double> set = top10cats.keySet(); Iterator<Double> iterator = set.iterator(); while (iterator.hasNext()) { context.write(NullWritable.get(), top10cats.get(iterator.next())); } } } static class reduce1 extends Reducer<NullWritable, Text, NullWritable, Text> { SortedMap<Double, Text> finalTop = new TreeMap<Double, Text>(); private int N = 10; @Override protected void reduce(NullWritable arg0, Iterable<Text> values, Reducer<NullWritable, Text, NullWritable, Text>.Context context) throws IOException, InterruptedException { for (Text value : values) { String[] finalresult = value.toString().split(","); finalTop.put(Double.parseDouble(finalresult[0]), new Text(value)); if (finalTop.size() > N) { finalTop.remove(finalTop.firstKey()); } ; } Set<Double> set = finalTop.keySet(); Iterator<Double> iterator = set.iterator(); // 依次写入到文件中 while (iterator.hasNext()) { context.write(NullWritable.get(), finalTop.get(iterator.next())); } } } public static void main(String[] args) throws Exception, IOException { Configuration conf = new Configuration(); Job job = Job.getInstance(conf); job.setJarByClass(TopN.class); job.setMapperClass(Mapper1.class); job.setReducerClass(reduce1.class); job.setMapOutputKeyClass(NullWritable.class); job.setMapOutputValueClass(Text.class); job.setOutputValueClass(NullWritable.class); job.setOutputKeyClass(Text.class); // 指定输入的数据的目录 FileInputFormat.setInputPaths(job, new Path("/Users/mac/Desktop/TopN.txt")); FileOutputFormat.setOutputPath(job, new Path("/Users/mac/Desktop/flowresort")); boolean result = job.waitForCompletion(true); System.exit(result ? 0 : 1); } }
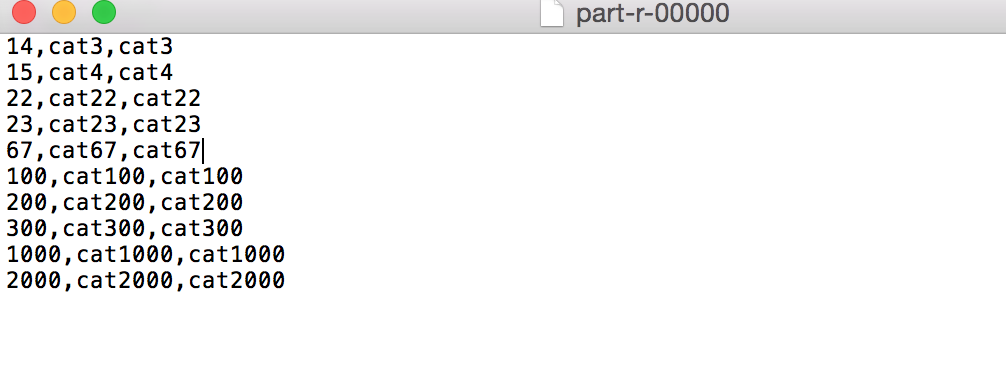
结果:
注意点:
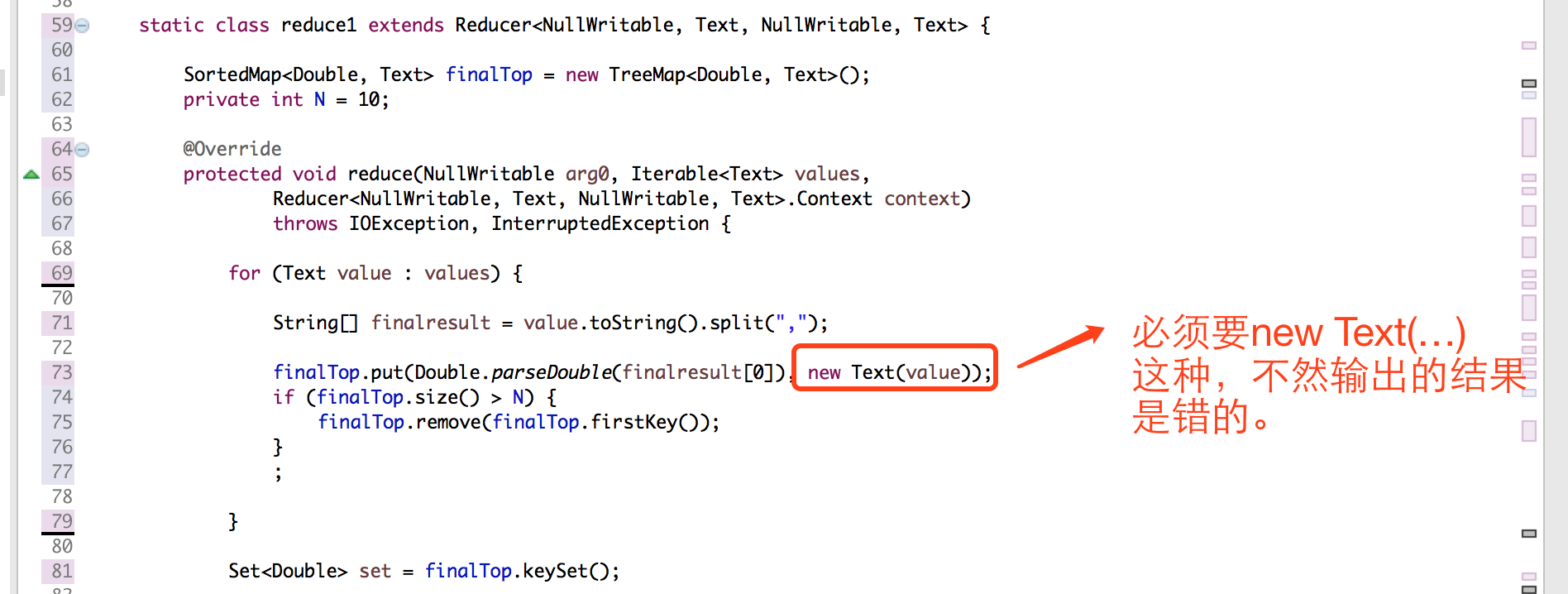
上面的注意点一定要切记。