【论文标题】AutoRec: Autoencoders Meet Collaborative Filtering (WWW'15)
【论文作者】Suvash Sedhain †∗ , Aditya Krishna Menon †∗ , Scott Sanner †∗ , Lexing Xie ∗†
【论文链接】Paper (2-pages // Double column)
<札记非FY>
====================首先,AutoEncoder 是什么?[ref-1]====================

 。本质上AE是学习到了一个原始输入的一个向量表达。
。本质上AE是学习到了一个原始输入的一个向量表达。=======================关于论文内容==============================
【概要简介】- [ref-2]

m:用户数


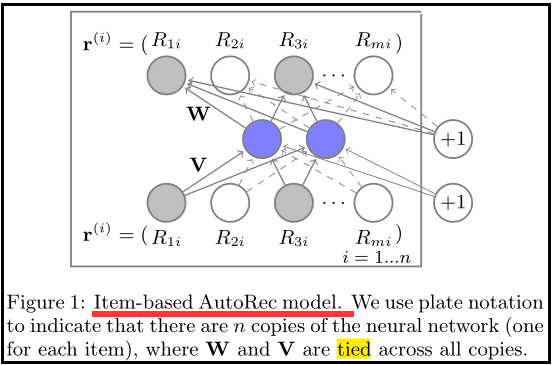
3、AutoRec 模型
AutoRec 在传统 AutoEncoder的基础上做了如下的变化:
- 损失函数只和观察到的元素有关
- 加上正则化项


对比实验,基线:RBM-CF
AutoRec和RBM-CF的区别:
- RBM是生成模型,AutoRec是判别模型
- RBM通过极大化对数似然来估计参数,AR直接用极小化RMSE
- 训练中,RBM需要用对比散度,AR直接用梯度下降
- RBM只能预测离散分数
- 参数量:RBM-CF:nkr(or mkr)AutoRec:nk(or mk)
实验结果:

通过对比各个模型的实验结果:
(1)item-based AutoRec胜出user-based AutoRec,比传统的FM类方法都要更好。(这可能是由于每个项目评分的平均数量是高于每个用户的输入评分数;用户评分数量的高方差导致基于用户的方法的预测不可靠)。
(2)sigmoid好于RELU。
(3)随着hidden 层节点数增加,RMSE越来越小。
【Reference】
1、https://blog.csdn.net/studyless/article/details/70880829
2、https://www.jianshu.com/p/4aadd0bdc901
3、https://blog.csdn.net/qq_40006058/article/details/87936043