使用Keras构建神经网络的基本工作流程主要可以分为 4个部分。(而这个用法和思路,很像是在使用Scikit-learn中的机器学习方法)
Model definition → Model compilation → Training → Evaluation and Prediction
以下为实践的步骤:
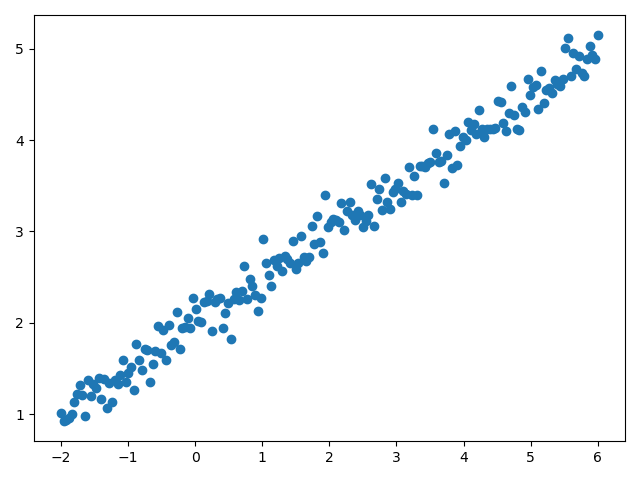
首先 人为地造一组由 y=0.5x+2 加上一些噪声而生成的数据,数据量一共有200个,其中160作为train set ,后40作为test set
# # 首先 人为地造一组由 y=0.5x+2 加上一些噪声而生成的数据,数据量一共有200个,其中160作为train set ,后40作为test set
import numpy as np
import matplotlib.pyplot as plt X = np.linspace(-2,6,200) np.random.shuffle(X) Y = 0.5 * X +2+0.15*np.random.randn(200,) # plot data plt.scatter(X,Y) plt.show() X_train, Y_train = X[:160], Y[:160] #train first 160 data points X_test, Y_test = X[160:], Y[160:] # test remaining 40 data points
绘制出的数据的分布情况如下:
1、首先执行构建模型的第一步,即 Model Definition:
这一步的作用就是定义NN中的层次结构。为此要引入两个重要的类,Sequential和Dense。
from keras.models import Sequential
from keras.layers import Dense
(1)Sequential是Keras中构建NN最常用的一种Model(也是最简单的一种),一个Sequential的Model 就是 a linear stack of layers,也就是说,你只要按顺序(使用add()方法)一层一层地顺序地添加神经网络层就可以了。
(2)Dense表示全连接层,此时它需要接收两个参数,即输入的节点数及输出的节点数,特别地,在一层一层地构建NN时,Keras还可以根据上一层的输出来推断下一次的输入,所以有些全连接层参数可以省略。
在这个简单的例子中,我们的全连接层只有一层,而且输入的节点数和输出的节点数都为1,所以有:
model = Sequential()
model.add(Dense(output_dim = 1, input_dim = 1))
2、接下来执行构建模型的第二步,即Model compilation:
这一步是要指定模型中的loss function(在这例子中使用的是最小二乘误差 ‘mse’ ),优化器以及metrics等内容。优化器你可以使用系统提供的默认优化器,例如你可以像下面这样用 'sgd' 表示随机梯度下降。
model.compile(loss='mse', optimizer='sgd')
也可以像下面这样自定义优化器中的参数:
from keras.optimizers import SGD
model.compile(loss='mse', optimizer=SGD(lr=0.01, momentum=0.9, nesterov=True))
3、接下来执行构建模型的第三步,即 Training:
有两个选择:
(1)第一种直接使用 fit,和Scikit-learn特别像!你只要在 fit 方法的参数列表中指定训练数据(特征向量和label)、训练的次数和用来做梯度下降的 batch size 就可以了。
model.fit(X_train, Y_train, epochs=100, batch_size=64)
(2)另外一个选择是你也可以采用下面的语法来 feed batches to your model manually:
model.train_on_batch(x_batch, y_batch) # 运行一批样品的单次梯度更新。
例如在本例中你可以把训练部分写成下面这种形式,其中每20步,我们会输出一次cost。
print('Training -----------')
for step in range(100):
cost = model.train_on_batch(X_train, Y_train)
if step % 20 == 0:
print('train cost: ', cost)
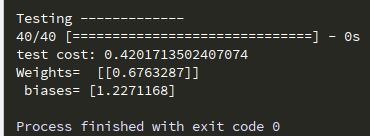
程序输出结果如下(注意由于存在各种随机性,每次的输出未必完全一致):

4、最后进入第四步:Evaluation and Prediction的部分。对于之前预留的测试集来说,你可以使用:
cost = model.evaluate(X_test, Y_test, batch_size=40)
具体来说针对上面这个例子则有:
print(' Testing -------------') loss_and_metrics =model.evaluate(X_test,Y_test,batch_size=40) print('test cost:',loss_and_metrics) W,b = model.layers[0].get_weights() print('Weights= ',W, ' biases=',b)
程序输出结果如下:
那么对一些新的数据进行预测的话,可以使用 predict,而且它的使用也与Scikit-learn中的用法及其相似, 最终我们预测test set 中的每个的点,并绘制预测的模型。
Y_pred =model.predict(X_test)
plt.scatter(X_test,Y_test)
plt.plot(X_test,Y_test)
plt.show()

5、最后附上完整的代码文件:
import numpy as np import theano.tensor as T import keras from keras import backend as K from keras import initializations # from keras import initializers ###### In Keras 2.0, initializations was renamed (mirror) as initializers. from keras.models import Sequential, Model, load_model, save_model from keras.layers.core import Dense, Lambda, Activation from keras.layers import Embedding, Input, Dense, merge, Reshape, Merge, Flatten from keras.optimizers import Adagrad, Adam, SGD, RMSprop from keras.regularizers import l2 from Dataset import Dataset from evaluate import evaluate_model from time import time import multiprocessing as mp import sys import math import argparse print(keras.__version__) # 使用的默认的Backend:TensorFlow #修改 # # 首先 人为地造一组由 y=0.5x+2 加上一些噪声而生成的数据,数据量一共有200个,其中160作为train set ,后40作为test set import numpy as np import matplotlib.pyplot as plt X = np.linspace(-2,6,200) np.random.shuffle(X) Y = 0.5 * X +2+0.15*np.random.randn(200,) # # plot data # plt.scatter(X,Y) # plt.show() X_train, Y_train = X[:160], Y[:160] #train first 160 data points X_test, Y_test = X[160:], Y[160:] # test remaining 40 data points # 第一步,即 Model Definition: from keras.models import Sequential from keras.layers import Dense model = Sequential() model.add(Dense(output_dim=1, input_dim=1)) # 第二步,即Model compilation: model.compile(loss='mse',optimizer='sgd') # 第三步,即 Training: # model.fit(X_train,Y_train,epochs=100,batch_size=64) # epochs=100会报错是怎么回事 # 或者: print('Training ----------------') for step in range(100): cost = model.train_on_batch(X_train,Y_train) if step %20 ==0: print('train cost: ',cost) # 第四步:Evaluation and Prediction的部分 # cost=model.evaluate(X_test,Y_test,batch_size=40) # 具体来说针对我们现在这个例子则有: print(' Testing -------------') loss_and_metrics =model.evaluate(X_test,Y_test,batch_size=40) print('test cost:',loss_and_metrics) W,b = model.layers[0].get_weights() print('Weights= ',W, ' biases=',b) # 那么对一些新的数据进行预测的话,可以使用 predict,而且它的使用也与Scikit-learn中的用法及其相似, # 最终我们预测test set 中的每个的点,并绘制预测的模型。 Y_pred =model.predict(X_test) plt.scatter(X_test,Y_test) plt.plot(X_test,Y_test) plt.show()
【Reference】
1、https://blog.csdn.net/baimafujinji/article/details/78384792