SSD模型训练起来较为简单,所以最近用的也比较多
现在做一个完整的SSD模型解析,包括训练过程中遇到的各种坑的解决办法
先放一个被用烂了的图
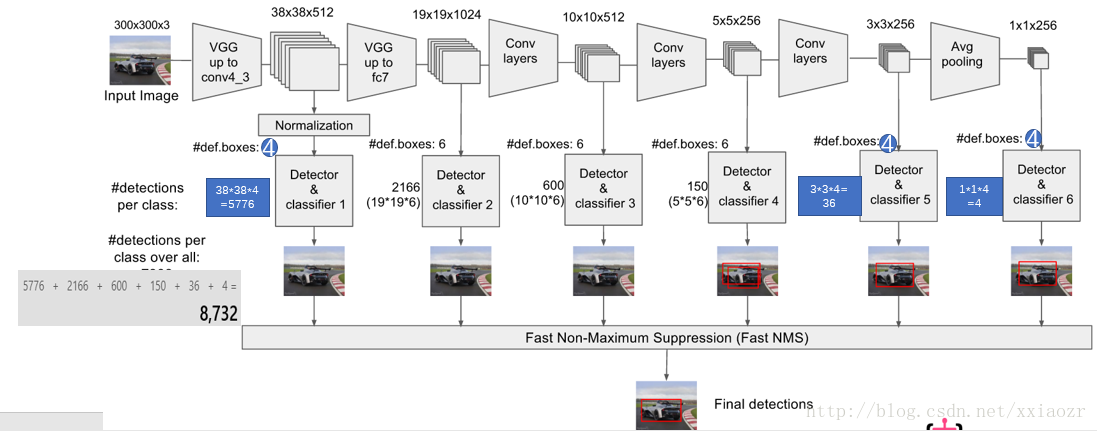
模型说明
图片通过vgg16的conv4_3layer得到一个feature_map_1
对feature_map_1进行卷积,使用3*3的卷积核,再使用1*1的卷积核,使用multi_task方法(在使用3*3卷积核之后,分别经过两个不同的1*1卷积核)
获得result_sigmoid(h*w*1)和result_softmax(h*w*m)
result_sigmoid对应的是这个区域的archer_box是否包含正样本
result_softmax对应的是这个区域那一个archer_box为字母框的概率最大
对feature_map_1通过3*3卷积核卷积之后的结果进行max_pooling获取feature_map_2
对feature_map_2进行卷积,使用3*3的卷积核,再使用1*1的卷积核,使用multi_task方法(在使用3*3卷积核之后,分别经过两个不同的1*1卷积核)
获得result_sigmoid_2(hh*ww*1)和result_softmax_2(hh*ww*m)
result_sigmoid_1对应的是这个区域的archer_box是否包含正样本
result_softmax_2对应的是这个区域那一个archer_box为字母框的概率最大
以此类推
关于archer_box:
先放个图

一般来说,CNN的不同层有着不同的感受野。然而,在SSD结构中,default box不需要和每一层的感受野相对应,特定的特征图负责处理图像中特定尺度的物体。在每个特征图上,default box的尺度计算如下:
计算feature_map_k的感受野 receptive_field
其中,smin = 0.2 × receptive_field,smax = 0.9 × receptive_field
default box的aspect ratios 有:
一般来说,设置6个radio即可(m=6)
每一个default box,宽度、高度、中心点计算如下:
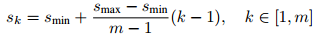
对于每一个Sk 我们有
a = {1, 2, 3,1/2,1/3},对于 aspect ratio = 1,额外增加一个default box,该box的尺度为
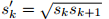
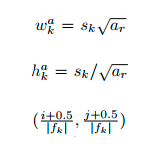
训练过程:
训练和解析是很不一样的
因为ssd模型的输出是一个feature map嘛,我开始就拿输入为一张图和输出为n张feature map去做反向传播
结果效果非常差,,,feature_map 全部趋于0
之后重新读了一遍论文,又读了一些博客,找到了正确训练的方法
我们已有的数据为带标记的图片数据
数据生成:
将图片输入vgg_16的conv5_3获取feature_map(h*w*c)
使用3*3的滑动窗口,stride为1 ,padding = same 将feature_map 取成h*w个3*3*c的小窗口
计算这个3*3滑动窗口的感受野
通过感受野,每个滑动窗口生成35个default box
遍历所有的标记,找到对这35个default_box最大的IOU
若iou<0.3则记为负样本,若iou>0.7则记为正样本
对于IOU>0.7的,找到对于iou最大的default box 相当于一个softmax 分类
因为我们ssd是多层的,feature_map是可以替换的,所以每一个feature map按照以上规则生成数据即可
网络训练
我们的输入是3*3*c的一个feature map
输出有两个
一个是一维的值,表示是否是正负样本
另一个是35维的向量,表示哪一个default box为iou最大的那个
网络结构就是卷积加全连接嘛,这个也比较简单
但要注意,最后一个卷积要使用(3*3) 的卷积核,输出为1*c
就是把每一个通道变成一个
网络封装
封装之后的网络输入为h*w*3的bgr图像
输出为3-5个map_1(h*w) , map_2(h*w*35)
第一个map 表示正负样本 第二个map表示哪一个default box iou最大
但是我们有全连接,,,全连接使用1*1卷积核代替即可
卷积没什么好说的
全连接用1*1卷积核代替即可