from http://blog.csdn.net/q408384053/article/details/8070627
因为最近在弄一个获取课表的程序,课表的内容来自教务系统网站,所以需要解析html。然后我就在网上搜索”c++解析html“,然后就找到了htmlcxx这个开源库,下载下来,发现不会使用它,然后又在网站上搜索相关资料。最后找到一个博客(http://www.cnblogs.com/zhanglanyun/),然后用email联系了他,解决了问题,很感谢他!
接着说如何使用(作为参考,可能在别人的电脑上和我这有些区别):
1.下载htmlcxx库,我下的是tar.gz格式的,然后用解压软件将它解压出来。
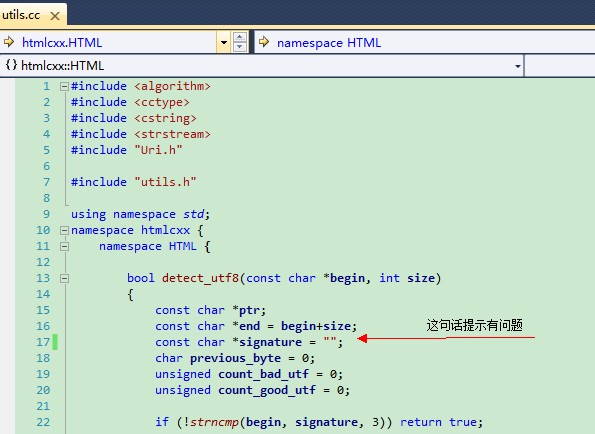
2.找到一个vs的工程文件htmlcxx.vcproj(旧版本的vs工程),打开打,直接编译可能会提示有一个错误(因为在我电脑里出现了),错误指向了一个常字符指针(const char *),如下图,然后只需要把后面的引号删掉,重新打一次,再编译,就可以成功编译了。
3.编译完成之后,工程生成了一个lib静态库文件。
4.但是这个库下载下来是不支持中文的,也就是说比如html中标签里含有中文,就会出错(这是我在获取源代码时,因为获取不完全,导致程序出错,才发现的)。如果出现了这个问题,可以查看以下两个博客,里面有解决方法。
http://my.oschina.net/leeeryan/blog/9914
http://blog.csdn.net/schoolers/article/details/6891061
5.然后在你的工程里面设置vc的包含目录和库目录,把htmlcxx文件夹包含,然后库目录包含刚才生成的lib的文件夹。另外,也可以将刚生成的lib拷贝到你的工程目录下,用#pragma (lib, "xxxx.lib")加载静态链接库。
6.接着,在 工程属性->c/c++->代码生成 里面将运行库设置为/MTd。
这就可以使用了。
如何使用呢?
以控制台为例
1.#include <htmlcxx/html/ParserDom.h>
2. #include <htmlcxx/html/utils.h>
3.使用命名空间,using namespace htmlcxx
4.
- HTML::ParserDom parser ; //可以用来将html代码转换成dom树
- tree<HTML::Node> dom ; //用来储存html各个节点
- tree<HTML::Node>::iterator iterator ; //树的迭代器
- iterator = dom.begin () ; //得到dom的第一个节点
- iterator->tagName () ; //获得节点的标签名
- iterator->parserAttributes () ; //附上节点属性
- iterator->Attribute ("href").second ; //此行执行需要上行,这相当于获取标签的href属性,之所以有second,因为Attribute ("attributeName")返回了一个pair
HTML::ParserDom parser ; //可以用来将html代码转换成dom树
tree<HTML::Node> dom ; //用来储存html各个节点
tree<HTML::Node>::iterator iterator ; //树的迭代器
iterator = dom.begin () ; //得到dom的第一个节点
iterator->tagName () ; //获得节点的标签名
iterator->parserAttributes () ; //附上节点属性
iterator->Attribute ("href").second ; //此行执行需要上行,这相当于获取标签的href属性,之所以有second,因为Attribute ("attributeName")返回了一个pair
在博客记录一下,方便以后使用。若有说的不对的地方,欢迎指出。