一、Web框架本质
web框架本质就是socket通信与HTTP协议的结合,socket保证服务端与客户端之间的请求与响应,HTTP协议保证了之间的标准,比如服务端接收到的客户端的请求报文;而客户端接收到的是服务端的响应报文。这些在socket通信中都应该提现出来。
- 响应本质
响应是服务器给客户端的响应,响应的是响应报文。
import socket def handle_request(conn): #接收客户端的请求 request = conn.recv(1024) print(request.decode()) #对客户端的响应 conn.send(b'HTTP/1.1 200 ok ') if __name__ == '__main__': sock = socket.socket(socket.AF_INET,socket.SOCK_STREAM) #绑定主机、ip sock.bind(('localhost',8000)) #监听主机、ip,等来连接 sock.listen(5) while True: conn,addr = sock.accept() #处理客户端请求 handle_request(conn) #处理完毕后关闭连接 conn.close()
- 请求本质
import socket sock = socket.socket(socket.AF_INET,socket.SOCK_STREAM) #连接服务端 sock.connect(('localhost',8000)) #发送GET请求, sock.send(b'GET / HTTP/1.0 Host:localhost ') #发送POST请求 # sock.send(b'POST / HTTP/1.0 Host:localhost username=admin&password=123456') #等着服务器响应,recv阻塞函数,I/O阻塞 sock.recv(1024) #关闭连接 sock.close()
上面请求的本质是基于I/O阻塞模型,也可以使其成为非阻塞I/O模型,详情查看:https://www.cnblogs.com/shenjianping/p/11618647.html


import socket sock = socket.socket(socket.AF_INET,socket.SOCK_STREAM) #连接不会阻塞 sock.setblocking(False) try: #连接服务端成功 sock.connect(('localhost',8000)) except BlockingIOError as e: print(e) #发送GET请求 sock.send(b'GET / HTTP/1.0 Host:localhost ') #发送POST请求 # sock.send(b'POST / HTTP/1.0 Host:localhost username=admin&password=123456') #等着服务器响应,recv阻塞函数,I/O阻塞 sock.recv(1024) #关闭连接 sock.close()
二、WSGI
在web开发中,一般分为服务器和应用程序,服务器就是对socket服务端进行封装,用于处理客户端发来的请求,应用程序就是用于处理各种业务逻辑,为了方便应用程序的开发,出现了各种框架,比如Django、Flask以及Tornado等,但是应用程序必须和服务器进行配合,那么不同的框架对应不同的服务器。这时候需要制定一个标准,只要服务器和框架都支持这个标准,那么它们就可以配合使用。
WSGI(Web Server Gateway Interface)是一种规范,它定义了使用python编写的web app与web server之间接口格式,实现web app与web server间的解耦。
python标准库提供的独立WSGI服务器称为wsgiref,我们可以使用wsgiref简单实现WSGI Server与WSGI Application。
from wsgiref.simple_server import make_server def RunServer(environ, start_response): start_response('200 OK', [('Content-Type', 'text/html')]) return [bytes('<h1>Hello, web!</h1>', encoding='utf-8'), ] if __name__ == '__main__': httpd = make_server('', 8000, RunServer) print("Serving HTTP on port 8000...") httpd.serve_forever()
上面可以通过127.0.0.0:8000进行访问,内部是怎么实现呢?
wsgiref.simple_server实现了一个简单的HTTP服务器(基于http.server),该服务器为WSGI应用程序提供服务。每个服务器实例在给定的主机和端口上服务单个WSGI应用程序。
在上面的代码中先执行:
httpd = make_server('', 8000, RunServer)
1、wsgiref.simple_server.make_server(host,port,app,server_class = WSGIServer,handler_class = WSGIRequestHandler )
创建一个监听主机和端口的WSGI服务器,接受app的连接。返回值是提供的server_class的实例,并将使用指定的handler_class处理请求。 app必须是WSGI应用程序对象。
- app必须是WSGI应用程序对象
(1)应用程序必须是一个可调用的对象,因此,应用程序可以是一个函数,一个类,或者一个重载了__call__的类的实例。
(2)应用程序必须接受两个参数并且要按照位置顺序,分别是environ(环境变量),以及start_response函数(负责将响应的status code,headers写进缓冲区但不返回给客户端)。
(3)应用程序返回的结果必须是一个可迭代的对象。
上面RunServer就是一个可调用对象(函数),返回的是一个列表(可迭代对象)。
def make_server( host, port, app, server_class=WSGIServer, handler_class=WSGIRequestHandler ): """Create a new WSGI server listening on `host` and `port` for `app`""" server = server_class((host, port), handler_class) server.set_app(app) return server
- make_server函数返回的就是一个WSGIServer类的对象
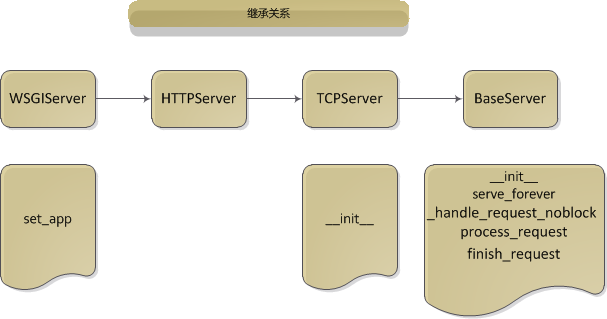
(1)WSGIServer类的初始化
可以看到上面类的继承关系,所以会执行TCPServer中的__init__方法:
def __init__(self, server_address, RequestHandlerClass, bind_and_activate=True): """Constructor. May be extended, do not override.""" #在BaseServer中self.server_address = server_address.self.RequestHandlerClass = RequestHandlerClass #RequestHandlerClass = WSGIRequestHandler BaseServer.__init__(self, server_address, RequestHandlerClass) self.RequestHandlerClass = RequestHandlerClass self.socket = socket.socket(self.address_family, self.socket_type) if bind_and_activate: try: self.server_bind() #self.socket.bind(self.server_address) 绑定主机和端口 self.server_activate() #elf.socket.listen(self.request_queue_size) 监听 except: self.server_close() raise
这里主要是赋值初始化操作和创建socket对象,绑定主机、端口并且监听。
(2)set_app方法
调用WSGIServer类中的set_app方法。
def set_app(self,application): self.application = application
将上述RunServer这个app传入到server(httpd)这个实例中。
2、httpd.serve_forever()
def serve_forever(self, poll_interval=0.5): """Handle one request at a time until shutdown. Polls for shutdown every poll_interval seconds. Ignores self.timeout. If you need to do periodic tasks, do them in another thread. """ self.__is_shut_down.clear() try: # XXX: Consider using another file descriptor or connecting to the # socket to wake this up instead of polling. Polling reduces our # responsiveness to a shutdown request and wastes cpu at all other # times. with _ServerSelector() as selector: selector.register(self, selectors.EVENT_READ) while not self.__shutdown_request: ready = selector.select(poll_interval) if ready: self._handle_request_noblock() self.service_actions() finally: self.__shutdown_request = False self.__is_shut_down.set()
server_forever函数中通过select函数当确认已经收到了来自客户端的请求连接,此时调用accept函数不会阻塞时,于是调用_handle_request_noblock函数,在函数中再依次调用了verify_request、process_request、 finish_request。
def _handle_request_noblock(self): """Handle one request, without blocking. I assume that selector.select() has returned that the socket is readable before this function was called, so there should be no risk of blocking in get_request(). """ try: request, client_address = self.get_request() #self.socket.accept()所以request相当于连接conn except OSError: return if self.verify_request(request, client_address): try: self.process_request(request, client_address) except: self.handle_error(request, client_address) self.shutdown_request(request) else: self.shutdown_request(request)
在finsih_request方法中,开始涉及到处理请求的类RequestHandlerClass(其实就是make_server函数中传入的WSGIRequestHandler)。
def finish_request(self, request, client_address): """Finish one request by instantiating RequestHandlerClass.""" self.RequestHandlerClass(request, client_address, self)
此时再看看RequestHandlerClass类相关的,其实就是WSGIRequestHandler类,对其进行初始化。下面就是处理请求类的继承关系:

- WSGIRequestHandler类初始化
class BaseRequestHandler: """Base class for request handler classes. This class is instantiated for each request to be handled. The constructor sets the instance variables request, client_address and server, and then calls the handle() method. To implement a specific service, all you need to do is to derive a class which defines a handle() method. The handle() method can find the request as self.request, the client address as self.client_address, and the server (in case it needs access to per-server information) as self.server. Since a separate instance is created for each request, the handle() method can define other arbitrary instance variables. """ def __init__(self, request, client_address, server): self.request = request self.client_address = client_address self.server = server #server就是httpd,WSGI服务器对象 self.setup() try: self.handle() finally: self.finish() ...
对一些变量赋值,request就是socket中accept函数接收的conn描述符,server就是make_server函数中返回的服务器WSGI对象(httpd)。
- StreamRequestHandler类中的setup
def setup(self): self.connection = self.request if self.timeout is not None: self.connection.settimeout(self.timeout) if self.disable_nagle_algorithm: self.connection.setsockopt(socket.IPPROTO_TCP, socket.TCP_NODELAY, True) self.rfile = self.connection.makefile('rb', self.rbufsize) self.wfile = self.connection.makefile('wb', self.wbufsize)
此处相当于conn进行读、写数据,使用self.rfile、self.wfile进行接收。
- WSGIRequestHandler类中的handle
def handle(self): """Handle a single HTTP request""" self.raw_requestline = self.rfile.readline(65537) #b'GET / HTTP/1.1 '
········if len(self.raw_requestline) > 65536: self.requestline = '' self.request_version = '' self.command = '' self.send_error(414) return if not self.parse_request(): # An error code has been sent, just exit return # Avoid passing the raw file object wfile, which can do partial # writes (Issue 24291) stdout = BufferedWriter(self.wfile) try: handler = ServerHandler( self.rfile, stdout, self.get_stderr(), self.get_environ() ) handler.request_handler = self # backpointer for logging handler.run(self.server.get_app()) finally: stdout.detach()
上面涉及新的类ServerHandler,其中有很重要的run方法,下面是所涉及的ServerHandler类的继承图谱:
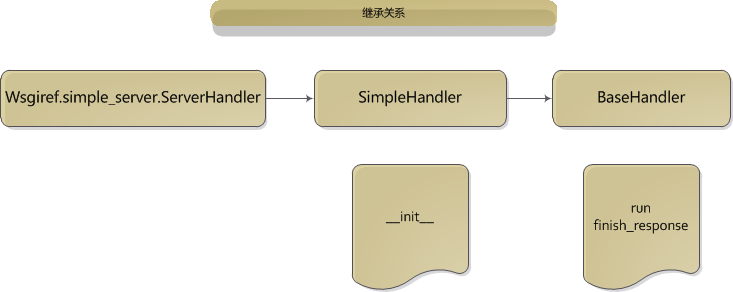
- ServerHandler类的初始化
ServerHandler类没有__init__方法,但是它继承的类SimpleHandler有__init__方法,内部就是一些变量的赋值操作。
__init__从self.rfile中读取数据,其实就是客户端的请求信息,通过self.parse_request对request信息信息进行解析。
def parse_request(self): """Parse a request (internal). The request should be stored in self.raw_requestline; the results are in self.command, self.path, self.request_version and self.headers. Return True for success, False for failure; on failure, an error is sent back. """ self.command = None # set in case of error on the first line self.request_version = version = self.default_request_version self.close_connection = True requestline = str(self.raw_requestline, 'iso-8859-1') requestline = requestline.rstrip(' ') self.requestline = requestline words = requestline.split() if len(words) == 3: command, path, version = words if version[:5] != 'HTTP/': self.send_error( HTTPStatus.BAD_REQUEST, "Bad request version (%r)" % version) return False try: base_version_number = version.split('/', 1)[1] version_number = base_version_number.split(".") # RFC 2145 section 3.1 says there can be only one "." and # - major and minor numbers MUST be treated as # separate integers; # - HTTP/2.4 is a lower version than HTTP/2.13, which in # turn is lower than HTTP/12.3; # - Leading zeros MUST be ignored by recipients. if len(version_number) != 2: raise ValueError version_number = int(version_number[0]), int(version_number[1]) except (ValueError, IndexError): self.send_error( HTTPStatus.BAD_REQUEST, "Bad request version (%r)" % version) return False if version_number >= (1, 1) and self.protocol_version >= "HTTP/1.1": self.close_connection = False if version_number >= (2, 0): self.send_error( HTTPStatus.HTTP_VERSION_NOT_SUPPORTED, "Invalid HTTP Version (%s)" % base_version_number) return False elif len(words) == 2: command, path = words self.close_connection = True if command != 'GET': self.send_error( HTTPStatus.BAD_REQUEST, "Bad HTTP/0.9 request type (%r)" % command) return False elif not words: return False else: self.send_error( HTTPStatus.BAD_REQUEST, "Bad request syntax (%r)" % requestline) return False self.command, self.path, self.request_version = command, path, version #command=GET;path=/;request_version=HTTP/1.1 # Examine the headers and look for a Connection directive. try: #解析头部 self.headers = http.client.parse_headers(self.rfile, _class=self.MessageClass) except http.client.LineTooLong: self.send_error( HTTPStatus.BAD_REQUEST, "Line too long") return False except http.client.HTTPException as err: self.send_error( HTTPStatus.REQUEST_HEADER_FIELDS_TOO_LARGE, "Too many headers", str(err) ) return False conntype = self.headers.get('Connection', "") if conntype.lower() == 'close': self.close_connection = True elif (conntype.lower() == 'keep-alive' and self.protocol_version >= "HTTP/1.1"): self.close_connection = False # Examine the headers and look for an Expect directive expect = self.headers.get('Expect', "") if (expect.lower() == "100-continue" and self.protocol_version >= "HTTP/1.1" and self.request_version >= "HTTP/1.1"): if not self.handle_expect_100(): return False return True
接下来就是生成ServerHandler实例,其中传入的参数有self.get_environ(),这里生成的是一个环境变量的字典。
def get_environ(self): env = self.server.base_environ.copy() #env = self.base_environ = {} env['SERVER_PROTOCOL'] = self.request_version env['SERVER_SOFTWARE'] = self.server_version env['REQUEST_METHOD'] = self.command if '?' in self.path: path,query = self.path.split('?',1) else: path,query = self.path,'' env['PATH_INFO'] = urllib.parse.unquote(path, 'iso-8859-1') env['QUERY_STRING'] = query host = self.address_string() if host != self.client_address[0]: env['REMOTE_HOST'] = host env['REMOTE_ADDR'] = self.client_address[0] if self.headers.get('content-type') is None: env['CONTENT_TYPE'] = self.headers.get_content_type() else: env['CONTENT_TYPE'] = self.headers['content-type'] length = self.headers.get('content-length') if length: env['CONTENT_LENGTH'] = length for k, v in self.headers.items(): k=k.replace('-','_').upper(); v=v.strip() if k in env: continue # skip content length, type,etc. if 'HTTP_'+k in env: env['HTTP_'+k] += ','+v # comma-separate multiple headers else: env['HTTP_'+k] = v return env
- BaseHandler类中的run方法
def run(self, application): """Invoke the application""" # Note to self: don't move the close()! Asynchronous servers shouldn't # call close() from finish_response(), so if you close() anywhere but # the double-error branch here, you'll break asynchronous servers by # prematurely closing. Async servers must return from 'run()' without # closing if there might still be output to iterate over. try: self.setup_environ() #执行传入的application RunServer self.result = application(self.environ, self.start_response) self.finish_response() except: try: self.handle_error() except: # If we get an error handling an error, just give up already! self.close() raise # ...and let the actual server figure it out.
self.result获取返回给前端的数据,其中的self.environ是环境参数,self.start_response函数获取status和headers。
- BaseHandler类中的finish_response方法
所有的数据都在finish_response()中写回给客户端。finish_response函数调用了write函数,write函数每次调用时都会检查headers是否已发送,否则先发送headers再发送data。
def finish_response(self): """Send any iterable data, then close self and the iterable Subclasses intended for use in asynchronous servers will want to redefine this method, such that it sets up callbacks in the event loop to iterate over the data, and to call 'self.close()' once the response is finished. """ try: if not self.result_is_file() or not self.sendfile(): #self.result是一个可迭代对象 for data in self.result: #write函数向客户端发送数据data之前检查是否发送了heasers,如果没有会先发送headers self.write(data) self.finish_content() finally: self.close()
总结:
上面涉及三类比较重要的内容,第一类是服务器WSGIServer相关类,构建服务器对象,接收客户端请求;第二类是处理请求WSGIRequestHandler相关类;第三类是给客户端返回响应的ServerHandler相关类。
三、自定义Web框架
(一)environ变量
environ是一个字典包含了一个请求的相关的所有变量,可以通过get_environ函数获取WSGI环境字典。
1、REQUEST_METHOD
HTTP请求方法,例如“ GET”或“ POST”。这永远不能是空字符串,因此始终是必需的。
2、SCRIPT_NAME
请求URL的“路径”的初始部分与应用程序对象相对应,以便应用程序知道其虚拟的“位置”。如果应用程序对应于服务器的“根”,则它可以是一个空字符串。
3、PATH_INFO
请求URL的其余“路径”,指定应用程序中请求目标的虚拟“位置”。如果请求URL定位到应用程序的根目录并且不带斜杠,则它 可以是一个空字符串。
4、CONTENT-TYPE
HTTP请求中任何Content-Type字段的内容。可能为空或缺席。
5、CONTENT_LENGTH
HTTP请求中任何Content-Length字段的内容。可能为空或缺席。
6、SERVER_NAME、SERVER_PORT
与SCRIPT_NAME和PATH_INFO结合使用时,可以使用这两个字符串来完成URL。但是请注意,HTTP_HOST(如果存在)应优先于SERVER_NAME用来重建请求URL。SERVER_NAME和SERVER_PORT 永远不能为空字符串,因此始终是必需的。
7、SERVER_PROTOCOL
客户端用于发送请求的协议版本。通常,这类似于“ HTTP / 1.0”或“ HTTP / 1.1”, 并且应用程序可以使用它来确定如何处理任何HTTP请求标头。
8、HTTP_变量
与客户端提供的HTTP请求标头相对应的变量(即,名称以“ HTTP_”开头的变量)。这些变量的存在与否应与请求中适当的HTTP标头的存在与否相对应。
(二)自定义Web框架
from wsgiref.simple_server import make_server #视图函数 # 返回的必须是一个可迭代对象,因为内部对结果self.result进行循环 ,最后通过self.write(data)写入发送 def index(): return [bytes('<h1>Hello, index!</h1>', encoding='utf-8'), ] def login(): return [bytes('<h1>Hello, login!</h1>', encoding='utf-8'), ] #路由系统 def routers(): urlpatterns = ( ('/index/', index), ('/login/', login), ) return urlpatterns def RunServer(environ, start_response): start_response('200 OK', [('Content-Type', 'text/html')]) url = environ['PATH_INFO'] urlpatterns = routers() func = None for item in urlpatterns: if item[0] == url: func = item[1] break if func: return func() else: return [bytes('<h1>404 not found</h1>', encoding='utf-8'), ] if __name__ == '__main__': httpd = make_server('', 8000, RunServer) httpd.serve_forever()
(三)Django框架与WSGI
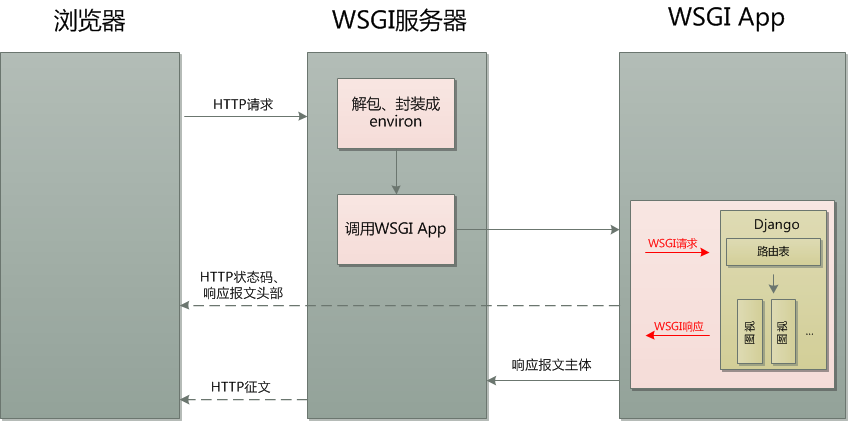
需要注意的是WSGI App需要满足以下三点:
(1)是可调用的,比如是一个函数,或者是一个可调用类(具有__call__方法)的实例
(2)WSGI应用应当返回一个可迭代(iterable)的值,比如字符串列表
(3)WSGI应用在返回之前,应当调用WSGI服务器传入的start_response函数发送状态码和HTTP报文头部
既然和django有关,那么WSGI App必然要和django有关:
from wsgiref.simple_server import make_server from django.core.wsgi import get_wsgi_application #创建WSGI应用对象 from django.http import HttpRequest,HttpResponse from django.urls.conf import path,re_path from django.conf import settings import sys #依赖settings中的配置 settings.configure() settings.DEBUG = True #视图函数 def login(request): return HttpResponse('login...') #路由表 urlpatterns = [ re_path(r'^$',login),#r为防止正则字符串被转义,'^$'中Django框架在使用定义的路由表之前,已经吃掉了$符前的那个前缀的/ ] settings.ROOT_URLCONF = sys.modules[__name__] #创建WSGI应用对象 wsgi_app = get_wsgi_application() if __name__ == '__main__': httpd = make_server('127.0.0.1', 8000, wsgi_app) print("start...") httpd.serve_forever()
在这里分析一下wsgi_app,get_wsgi_application函数返回的是一个WSGIHandler(django.core.handlers.wsgi.WSGIHandler)对象。
class WSGIHandler(base.BaseHandler): request_class = WSGIRequest def __init__(self, *args, **kwargs): super().__init__(*args, **kwargs) self.load_middleware() #存在__call__方法 def __call__(self, environ, start_response): set_script_prefix(get_script_name(environ)) #发送一个信号 signals.request_started.send(sender=self.__class__, environ=environ) #处理请求、处理中间件 request = self.request_class(environ) #处理响应 response = self.get_response(request) response._handler_class = self.__class__ status = '%d %s' % (response.status_code, response.reason_phrase) response_headers = list(response.items()) for c in response.cookies.values(): response_headers.append(('Set-Cookie', c.output(header=''))) #返回状态码、响应头 start_response(status, response_headers) if getattr(response, 'file_to_stream', None) is not None and environ.get('wsgi.file_wrapper'): response = environ['wsgi.file_wrapper'](response.file_to_stream) return response
这个对应比较重要的是__call__(self, environ, start_response)方法:
def __call__(self, environ, start_response): set_script_prefix(get_script_name(environ)) #发送一个信号 signals.request_started.send(sender=self.__class__, environ=environ) #处理请求、处理中间件 request = self.request_class(environ) #处理响应 response = self.get_response(request) response._handler_class = self.__class__ status = '%d %s' % (response.status_code, response.reason_phrase) response_headers = list(response.items()) for c in response.cookies.values(): response_headers.append(('Set-Cookie', c.output(header=''))) #返回状态码、响应头 start_response(status, response_headers) if getattr(response, 'file_to_stream', None) is not None and environ.get('wsgi.file_wrapper'): response = environ['wsgi.file_wrapper'](response.file_to_stream) return response
__call__函数是每一次请求的入口函数,内部的代码都是请求过程。
四、自定义异步I/O框架
异步I/O框架基于I/O多路复用模型来实现的。因此严格的来说它还是同步的,在等待数据从客户端(服务端)的内核态到服务端(客户端)的内核态以及从服务端的内核态(客户端)的用户态的过程中是阻塞的,当然可通过socket.setblocking(False)是第一阶段(accept函数)非阻塞,详情参见:https://www.cnblogs.com/shenjianping/p/11618647.html。
(一)基于客户端自定义异步I/O框架
1、I/O多路复用
I/O多路复用中使用到了select模块或者selectors模块。
rlist,wlist,elist = select.select([socket对象1,socket对象2,],[socket对象1,socket对象2,],[],0.05)
rlist:因为是客户端,所以监听的socket对象是conn,只要conn变化,说明服务端发送数据过来了
wlist:里面的socket对象是已经和服务端建立连接的conn对象,它比rlist要先有数据,毕竟先连接上了,才能发送请求。
其次,rlist、wlist中添加的是socket对象,其实内部不仅仅是只能添加socket对象,只要添加的对象符合实现了fileno方法并且返回一个文件描述符即可。
class Bar: def fileno(self): obj = socket() return obj.fileno()
rlist,wlist,elist = select.select([Bar对象,],[Bar对象,],[],0.05)
2、实现
class HttpRequest: """ 主要用于封装host、callback """ def __init__(self,sk,host,callback): self.socket = sk self.host = host self.callback = callback def fileno(self): return self.socket.fileno() class HttpResponse: """ 处理服务端响应内容 """ def __init__(self,recv_data): self.recv_data = recv_data self.header_dict = {} self.body = None self.initialize() def initialize(self): """ 处理请求头和请求体 :return: """ headers, body = self.recv_data.split(b' ', 1) self.body = body header_list = headers.split(b' ') for h in header_list: h_str = str(h,encoding='utf-8') v = h_str.split(':',1) if len(v) == 2: self.header_dict[v[0]] = v[1] class AsyncRequest: def __init__(self): self.conn = [] self.connection = [] # 用于检测是否已经连接成功 def add_request(self,host,callback): """ 因为使用setblocking,connect不会阻塞,如果不进行异常处理就会报错 :param host: :param callback: :return: """ try: sk = socket.socket() sk.setblocking(False) sk.connect((host,80,)) except BlockingIOError as e: pass #需要将host与回调函数callback传入,所以在使用HttpRequest进行封装 request = HttpRequest(sk,host,callback) #HttpRequest中实现了fileno方法并且返回文件描述符,所以可以加入列表self.conn、self.connection进行监听 self.conn.append(request) self.connection.append(request) def run(self): while True: #注意这是客户端的select监听,所以self.connection表示是否已经连接上服务端,它先有数据 rlist,wlist,elist = select.select(self.conn, self.connection, self.conn, 0.05) #连接服务端成功,并且可以发送请求 for w in wlist: print(w.host,'连接成功...') # 只要能循环到,表示socket和服务器端已经连接成功 tpl = "GET / HTTP/1.0 Host:%s " %(w.host,) w.socket.send(bytes(tpl,encoding='utf-8')) self.connection.remove(w) #获取服务端的响应 for r in rlist: # r,是HttpRequest recv_data = bytes() while True: #进行异常处理,防止数据接收完毕报错 try: chunck = r.socket.recv(8096) recv_data += chunck except Exception as e: break #对响应的数据进行处理 response = HttpResponse(recv_data) #调用回调函数,并且将服务端返回的数据传给每一个请求对应的回调函数 r.callback(response) #关闭socket,HTTP是短链接,无状态 r.socket.close() #不再监听self.conn self.conn.remove(r) #而非self.connection,只有当响应完成才能退出 if len(self.conn) == 0: break #每一个请求地址对应的回调函数 def func1(response): print('保存到文件',response.header_dict) def func2(response): print('保存到数据库', response.body) #客户端访问的请求地址 url_list = [ {'host':'www.baidu.com','callback': func1}, {'host':'www.cnblogs.com','callback': func2}, ] req = AsyncRequest() for item in url_list: req.add_request(item['host'],item['callback']) req.run()
上面通过非阻塞的socket和IO多路复用结合实现了异步I/O框架(所谓的异步是自行调用回调函数),但是需要注意的是I/O多路复用的唯一作用就是监听多个socket对象,实现并发连接(在一个线程内实现并发连接),其次非阻塞的socket其实在I/O模型的第二阶段有阻塞,但是对使用者这来讲自行回调实现了异步。
在asyncio、gevent、twisted内部也是基于这种原理来实现的,所谓的事件循环就是上述while死循环利用select模块来监视socket对象(客户端的conn对象)。
(二)基于服务端自定义异步I/O框架
服务端就是用于处理客户端发来的请求,并且返回响应的结果,上面也说了select模块主要功能就是监视多个socket对象,它可以基于单线程实现并发。但是服务端的accept、recv函数是阻塞的,所以它需要配合非阻塞I/O模型来使用,那么这是不是就和客户端的异步I/O框架一样了呢?在客户端的异步I/O框架中最后都自行调用回调函数,回调函数在服务端的体现就是每一个路由匹配的视图函数,如果视图函数中有I/O阻塞怎么办?这里使用了Future对象。体现了三点:
- select模块解决多客户端连接的并发问题
- 使用socket.setblocking(False)解决accept、recv的阻塞问题
- Future对象解决回调函数(视图函数)中的I/O阻塞问题
import socket import select import re import time class Future(object): def __init__(self,time_out=0): self.result=None self.start_time=time.time() self.time_out=time_out class HttpRequest(object): def __init__(self,content): self.content=content self.header_bytes=bytes() self.body_bytes=bytes() self.method='' self.url='' self.protocal='' self.headers_dict={} self.initialize() self.initialize_header() def initialize(self): temp_list=self.content.split(b' ',1) #类似于GET请求,只有请求头 if len(temp_list) == 1: self.header_bytes += temp_list[0] else: #类似于POST请求既有请求头又有请求体 h, b = temp_list self.header_bytes += h self.body_bytes += b #将请求头的字节类型转成字符串类型 def header_str(self): return str(self.header_bytes,encoding='utf-8') #处理请求头、请求体 def initialize_header(self): headers=self.header_str().split(' ') #处理请求首行 GET /index HTTP/1.0 first_line_list=headers[0].split(' ') if len(first_line_list)==3: self.method,self.url,self.protocal=first_line_list #处理请求头,变成字典形式 for line in headers: headers_list=line.split(':') if len(headers_list)==2: headers_title,headers_body=headers_list self.headers_dict[headers_title]=headers_body #视图函数 def login(request): return 'login' def index(request): """ 非正常的请求,返回future对象 """ future=Future(5) return future #路由系统 routers=[ ('/login/',login), ('/index/',index), ] def run(): sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM) #如果要已经处于连接状态的soket在调用closesocket后强制关闭,不经历TIME_WAIT的过程: sock.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1) sock.bind(('127.0.0.1', 8888), ) sock.setblocking(False) sock.listen(128) inputs = [] inputs.append(sock) asyn_request_dic={ # 'sock':future } while True: rlist,wlist,elist=select.select(inputs,[],[],0.005) #客户端发送的正常请求 for r in rlist: if r==sock: #有客户端来进行连接 conn,addr=sock.accept() conn.setblocking(False) inputs.append(conn) else: #客户端发来数据 data = b"" while True: #防止数据接收完毕报错,进行异常处理 try: chunk = r.recv(1024) data = data + chunk except Exception as e: chunk = None if not chunk: break #将请求信息封装到HttpRequest类中处理 request = HttpRequest(data) func=None flag=False #路由匹配,匹配请求的url,执行对应的视图函数 for route in routers: if re.match(route[0], request.url): flag=True func = route[1] break #匹配成功 if flag: #获取对应请求url视图函数执行结果 result=func(request) #判断返回的是否是future对象,如果是非正常请求,将conn添加到字典,后面单独处理,注意此时与这个客户端并没有断开连接 if isinstance(result, Future): asyn_request_dic[r]=result #正常请求就正常返回,注意返回后需要从监视的列表中移除conn,并且断开连接,因为HTTP是短链接 else: r.sendall(bytes(result, encoding='utf-8')) inputs.remove(r) r.close() #匹配没成功 else: r.sendall(b'404') inputs.remove(r) r.close() #客户端发送非正常请求,比如在视图函数中阻塞了,判断非正常请求是否超时,如果超时就设置 future.result="请求超时", #此时future.result就有值了,直接返回 for conn in list(asyn_request_dic.keys()): future=asyn_request_dic[conn] start_time=future.start_time time_out=future.time_out finall_time=time.time() if future.result: #此处有sendall(),需要将字符串转为字节类型 conn.sendall(bytes(future.result,encoding='utf-8')) conn.close() #字典在循环时是不能进行修改、删除等操作的,所以转换为列表即可 del asyn_request_dic[conn] inputs.remove(conn) if start_time + time_out <= finall_time: future.result="请求超时" if __name__ == '__main__': run()
上述实现的就是服务端的自定义异步I/O框架,可以看到上面很重要的一点就是使用了Future对象,它的作用就是处理视图函数给客户端的响应阻塞。
import socket import select import re import time class HttpRequest(object): def __init__(self, content): self.content = content self.header_bytes = bytes() self.body_bytes = bytes() self.method = '' self.url = '' self.protocal = '' self.headers_dict = {} self.initialize() self.initialize_header() def initialize(self): temp_list = self.content.split(b' ', 1) # 类似于GET请求,只有请求头 if len(temp_list) == 1: self.header_bytes += temp_list[0] else: # 类似于POST请求既有请求头又有请求体 h, b = temp_list self.header_bytes += h self.body_bytes += b # 将请求头的字节类型转成字符串类型 def header_str(self): return str(self.header_bytes, encoding='utf-8') # 处理请求头、请求体 def initialize_header(self): headers = self.header_str().split(' ') # 处理请求首行 GET /index HTTP/1.0 first_line_list = headers[0].split(' ') if len(first_line_list) == 3: self.method, self.url, self.protocal = first_line_list # 处理请求头,变成字典形式 for line in headers: headers_list = line.split(':') if len(headers_list) == 2: headers_title, headers_body = headers_list self.headers_dict[headers_title] = headers_body # 视图函数 def login(request): return 'login' def index(request): """ 这个视图函数会阻塞,导致后面的请求都处理不了 :param request: :return: """ time.sleep(10) return 'index' # 路由系统 routers = [ ('/login/', login), ('/index/', index), ] def run(): sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM) # 如果要已经处于连接状态的soket在调用closesocket后强制关闭,不经历TIME_WAIT的过程: sock.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1) sock.bind(('127.0.0.1', 8888), ) sock.setblocking(False) sock.listen(128) inputs = [] inputs.append(sock) while True: rlist, wlist, elist = select.select(inputs, [], [], 0.005) # 客户端发送的请求 for r in rlist: if r == sock: # 有客户端来进行连接 conn, addr = sock.accept() conn.setblocking(False) inputs.append(conn) else: # 客户端发来数据 data = b"" while True: # 防止数据接收完毕报错,进行异常处理 try: chunk = r.recv(1024) data = data + chunk except Exception as e: chunk = None if not chunk: break # 将请求信息封装到HttpRequest类中处理 request = HttpRequest(data) func = None flag = False # 路由匹配,匹配请求的url,执行对应的视图函数 for route in routers: if re.match(route[0], request.url): flag = True func = route[1] break # 匹配成功 if flag: result=func(request) r.sendall(bytes(result, encoding='utf-8')) inputs.remove(r) r.close() # 匹配没成功 else: r.sendall(b'404') inputs.remove(r) r.close() if __name__ == '__main__': run()
在这个同步I/O框架中没有使用Future对象,当请求url匹配到/index/时执行视图函数index,但是因为index中的等待了10s,导致后面的请求处理都跟着等待10s,Future对象刚好解决了这个问题,当index函数中是阻塞的时,就将这个请求临时加入到一个指定的字典中,然后先不用管它(但并没有断开连接),在index阻塞这段时间中还可以处理其它请求,当处理完正常请求后再处理这些阻塞的请求。
Tornado框架的实现原理就是基于这种异步I/O框架的,内部也使用了Future对象来处理这种阻塞情况的。
参考: