arraylist和linkedlist有什么特点?我相信基本准备过或者说学习过的人应该都对答如流吧,底层实现,数据结构,数组,链表,查找效率,增删效率等等,这些基本上搜索引擎可以随便找到,而且基本上所有的文章差不多都是那点儿货,大家也把这些东西奉若真理,人云亦云,其实只需要非常简单的代码就可以测试这个结论到底对不对。
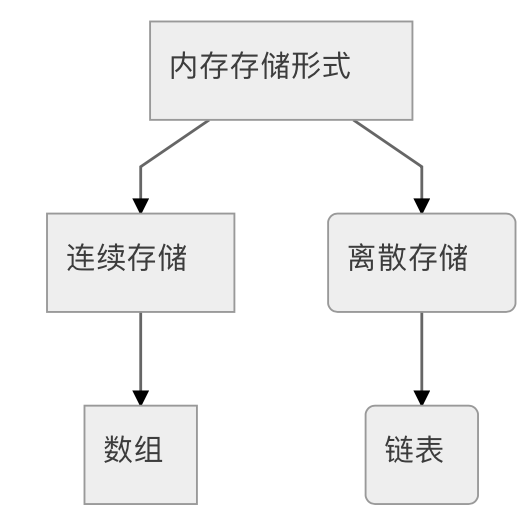
实现原理
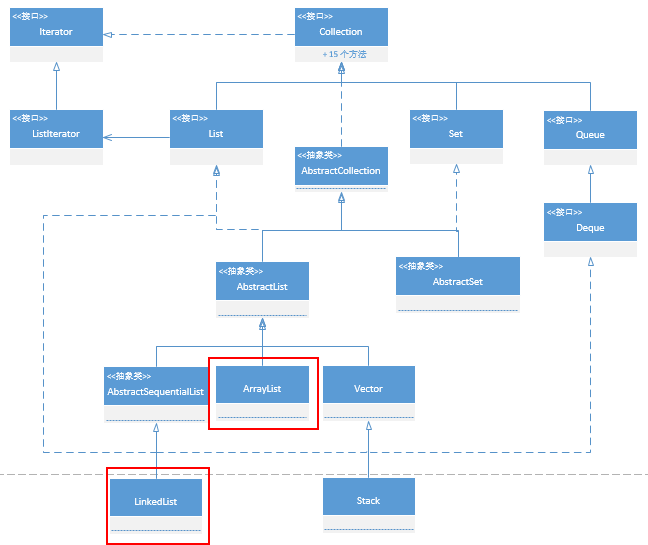
简单的说一下实现原理吧,有助于下面内容的展开,简单带过:ArrayList与LinkedList都是List接口实现类
-
ArrayList:
虽然叫list,底层是通过动态数组来实现,也就是一块连续的内存,初始化默认大小是10,每次扩容为1.5倍 -
LinkedList
java中的链表,内部定义了Node类,类中item用于存储数据,两个Node类分别为prev和next来实现双向链表,每次新增元素时new Node()
目前熟知的优缺点
-
ArrayList
优点:由于底层实现是数组,查找效率为O(1)
缺点:插入和删除操作需要移动所有受影响的元素,效率相对较低 -
LinkedList
优点:插入和删除时只需要添加或删除前后对象的引用,插入较快
缺点:在内存中存储不连续,只能通过遍历查询,效率相对较低
测试
首先由于数组的特性,所以插入操作的话我们分为三种情况:从头部插入,从中间插入和从尾部插入
**测试结果肯定机器性能和当时运行状况的影响,由于只是简单的测试,并不需要非常复杂严谨的测试策略,我这里基本也就是一个情况跑5~10次,而且代码也只是简单的单线程循环插入操作,大体测试结果和趋势是没问题的
1 @Test
2 public void addFromHeaderTestArray() {
3 ArrayList<Integer> list = new ArrayList<>();
4 int i = 0;
5
6 long timeStart = System.nanoTime();
7
8 while (i < 100) {
9 list.add(0, i);
10 i++;
11 }
12 long timeEnd = System.nanoTime();
13 System.out.println("ArrayList cost" + (timeEnd - timeStart));
14 }
15
16 @Test
17 public void addFromHeaderTestLinked() {
18 LinkedList<Integer> list = new LinkedList<>();
19 int i = 0;
20 long timeStart = System.nanoTime();
21 while (i < 100) {
22 list.addFirst(i);
23 i++;
24 }
25 long timeEnd = System.nanoTime();
26
27 System.out.println("LinkedList cost" + (timeEnd - timeStart));
28 }
代码比较简单,只贴出来一段了,每次改一下循环次数和add方法就可以了,以下时间单位均为纳秒
- 头部插入
测试结果(100条):
| name/times | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|
| ArrayList | 88300 | 84900 | 101700 | 93800 | 88100 |
| LinkedList | 68400 | 71200 | 88600 | 93300 | 96000 |
只测试了100条的情况,结果符合预期,这里我特意放了一条特殊情况,因为我们的实验确实比较简单不够复杂和系统,结果跟当时电脑的运行状况有关,但是我们这里只是插入100条,如果你换成10000条,你就会发现差距相当明显了,而且不管跑多少次,都不会出现ArrayList更快的情况,这里具体结果不贴了,有兴趣自己跑一下,结论是没问题的。
- 中间插入
1 while (i < 100) {
2 int temp = list.size();
3 list.add(temp / 2, i);
4 i++;
5 }
测试结果(100条):
|name/times|1|2|3|4|5|
|—|
|ArrayList|128300|92800|106300|77600|90700|
|LinkedList|175100|210900|164200|164200|195700|
测试结果(10000条):
| name/times | 1 | 2 | 3 | 4 |
|---|---|---|---|---|
| ArrayList | 9745300 | 10319900 | 10986800 | 11696600 |
| LinkedList | 66968400 | 63269400 | 70954900 | 65432600 |
这次中间插入分别测试了100条和10000条,是不是有点儿慌了?怎么和自己学的不一样了?从中间插入居然ArrayList更快?
- 尾部插入
1 while (i < 10000) {
2 list.add(i);
3 i++;
4 }
测试结果(100条):
| name/times | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|
| ArrayList | 32100 | 23600 | 23500 | 27800 | 16100 |
| LinkedList | 72200 | 73400 | 70200 | 74800 | 90000 |
结果已经很明显了,只贴了100条的数据,有兴趣可以自己试试,插入更多条也还是ArrayList更快,怎么样?看到这里是不是颠覆认知了
测试结果
头部插入:ArrayList>LinkedList
中间插入:ArrayList<LinkedList
尾部插入:ArrayList<LinkedList (差不多,AL稍微快一点;对于尾部插入而言,ArrayList 与 LinkedList 的性能几乎是一致的。)
结果分析
- 头部插入:由于ArrayList头部插入需要移动后面所有元素,所以必然导致效率低
- 中间插入:查看源码会注意到LinkedList的中间插入其实是先判断插入位置距离头尾哪边更接近,然后从近的一端遍历找到对应位置,而ArrayList是需要将后半部分的数据复制重排,所以两种方式其实都逃不过遍历的操作,相对效率都很低,但是从实验结果我们可以看到还是ArrayList更胜一筹,我猜测这与数组在内存中是连续存储有关
- 尾部插入:ArrayList并不需要复制重排数据,所以效率很高,这也应该是我们日常写代码时的首选操作,而LinkedList由于还需要new对象和变换指针,所以效率反而低于ArrayList
删除操作这里不做实验了,但是可以明确的告诉大家,结果是一样的,因为逻辑和添加操作并没有什么区别
数组扩容
再说一下数组扩容的问题,虽然ArrayList存在扩容的效率问题,但这只是在容量较小的时候,假如初始是10,第一次扩容结束是15,没有增加太多,但是如果是10000,那么扩容后就到了15000,实际上越往后每次扩容对后续性能影响越小,而且即便存在扩容问题,实验结果表明还是优于LinkedList的。
LinkedList源码
1 // 在index前添加节点,且节点的值为element
2 public void add(int index, E element) {
3 addBefore(element, (index==size ? header : entry(index)));
4 }
5
6 // 获取双向链表中指定位置的节点
7 private Entry<E> entry(int index) {
8 if (index < 0 || index >= size)
9 throw new IndexOutOfBoundsException("Index: "+index+
10 ", Size: "+size);
11 Entry<E> e = header;
12 // 获取index处的节点。
13 // 若index < 双向链表长度的1/2,则从前向后查找;
14 // 否则,从后向前查找。
15 if (index < (size >> 1)) {
16 for (int i = 0; i <= index; i++)
17 e = e.next;
18 } else {
19 for (int i = size; i > index; i--)
20 e = e.previous;
21 }
22 return e;
23 }
24
25 // 将节点(节点数据是e)添加到entry节点之前。
26 private Entry<E> addBefore(E e, Entry<E> entry) {
27 // 新建节点newEntry,将newEntry插入到节点e之前;并且设置newEntry的数据是e
28 Entry<E> newEntry = new Entry<E>(e, entry, entry.previous);
29 // 插入newEntry到链表中
30 newEntry.previous.next = newEntry;
31 newEntry.next.previous = newEntry;
32 size++;
33 modCount++;
34 return newEntry;
从中,我们可以看出:通过add(int index, E element)向LinkedList插入元素时。先是在双向链表中找到要插入节点的位置index;找到之后,再插入一个新节点。
双向链表查找index位置的节点时,有一个加速动作:若index < 双向链表长度的1/2,则从前向后查找; 否则,从后向前查找。
接着,我们看看ArrayList.java中向指定位置插入元素的代码。如下:
1 // 将e添加到ArrayList的指定位置
2 public void add(int index, E element) {
3 if (index > size || index < 0)
4 throw new IndexOutOfBoundsException(
5 "Index: "+index+", Size: "+size);
6
7 ensureCapacity(size+1); // Increments modCount!!
8 System.arraycopy(elementData, index, elementData, index + 1,
9 size - index);
10 elementData[index] = element;
11 size++;
12 }
ensureCapacity(size+1) 的作用是“确认ArrayList的容量,若容量不够,则增加容量。”
真正耗时的操作是 System.arraycopy(elementData, index, elementData, index + 1, size - index);
实际上,我们只需要了解: System.arraycopy(elementData, index, elementData, index + 1, size - index); 会移动index之后所有元素即可。这就意味着,ArrayList的add(int index, E element)函数,会引起index之后所有元素的改变!
插入位置的选取对LinkedList有很大的影响,一直往数据中间部分与尾部插入删除的时候,ArrayList比LinkedList更快
原因大概就是当数据量大的时候,system.arraycopy的效率要比每次插入LinkedList都需要从两端查找index和分配节点node来的更快。
LinkedList 双向链表实现
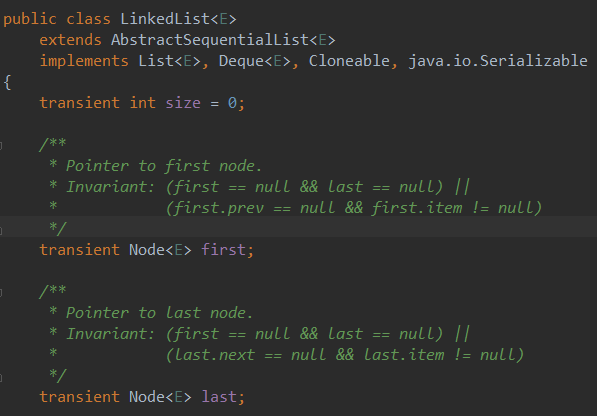
可以看到, LinkedList 的成员变量只有三个:
- 头节点 first
- 尾节点 last
- 容量 size
节点是一个双向节点:
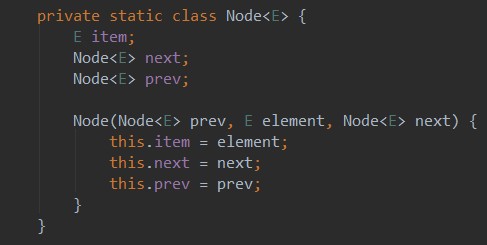
用一副图表示节点:

双向链表的底层结构图:
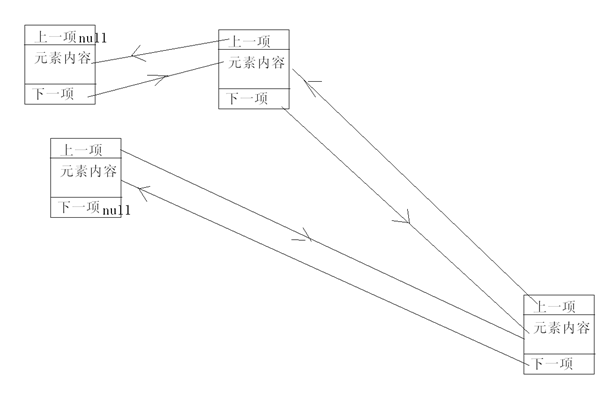
每个节点元素里包含三部分:前一个节点元素地址,下一个节点元素地址,当前节点元素内容
LinkedList 特点
- 双向链表实现
- 元素时有序的,输出顺序与输入顺序一致
- 允许元素为 null
- 所有指定位置的操作都是从头开始遍历进行的
- 和 ArrayList 一样,不是同步容器
并发访问注意事项
linkedList 和 ArrayList 一样,不是同步容器。所以需要外部做同步操作,或者直接用 Collections.synchronizedList 方法包一下,最好在创建时就包一下:
List list = Collections.synchronizedList(new LinkedList(...));
Thanks:
https://blog.csdn.net/zycR10/article/details/99775821?utm_medium=distribute.pc_relevant_t0.none-task-blog-BlogCommendFromMachineLearnPai2-1.channel_param&depth_1-utm_source=distribute.pc_relevant_t0.none-task-blog-BlogCommendFromMachineLearnPai2-1.channel_param
https://www.cnblogs.com/syp172654682/p/9817277.html
深入理解linkedlist: https://blog.csdn.net/u011240877/article/details/52876543