一、离线推荐服务
离线推荐服务是综合用户所有的历史数据,利用设定的离线统计算法和离线推荐算法周期性的进行结果统计与保存,计算的结果在一定时间周期内是固定不变的,变更的频率取决于算法调度的频率。
离线推荐服务主要计算一些可以预先进行统计和计算的指标,为实时计算和前端业务相应提供数据支撑。
离线推荐服务主要分为统计性算法、基于ALS的协同过滤推荐算法以及基于ElasticSearch的内容推荐算法。
在recommender下新建子项目StatisticsRecommender,pom.xml文件中只需引入spark、scala和mongodb的相关依赖:
离线统计服务
1. 历史热门电影统计
根据所有历史评分数据,计算历史评分次数最多的电影。
实现思路:
通过Spark SQL读取评分数据集,统计所有评分中评分数最多的电影,然后按照从大到小排序,将最终结果写入MongoDB的RateMoreMovies数据集中。
2 最近热门电影统计
根据评分,按月为单位计算最近时间的月份里面评分数最多的电影集合。
实现思路:
通过Spark SQL读取评分数据集,通过UDF函数将评分的数据时间修改为月,然后统计每月电影的评分数。统计完成之后将数据写入到MongoDB的RateMoreRecentlyMovies数据集中。
3 电影平均得分统计
根据历史数据中所有用户对电影的评分,周期性的计算每个电影的平均得分。
实现思路:
通过Spark SQL读取保存在MongDB中的Rating数据集,通过执行以下SQL语句实现对于电影的平均分统计:
4 每个类别优质电影统计
根据提供的所有电影类别,分别计算每种类型的电影集合中评分最高的10个电影。
实现思路:
在计算完整个电影的平均得分之后,将影片集合与电影类型做笛卡尔积,然后过滤掉电影类型不符合的条目,将DataFrame输出到MongoDB的GenresTopMovies集合中。
二、基于隐语义模型的协同过滤推荐
项目采用ALS作为协同过滤算法,分别根据MongoDB中的用户评分表和电影数据集计算用户电影推荐矩阵以及电影相似度矩阵。
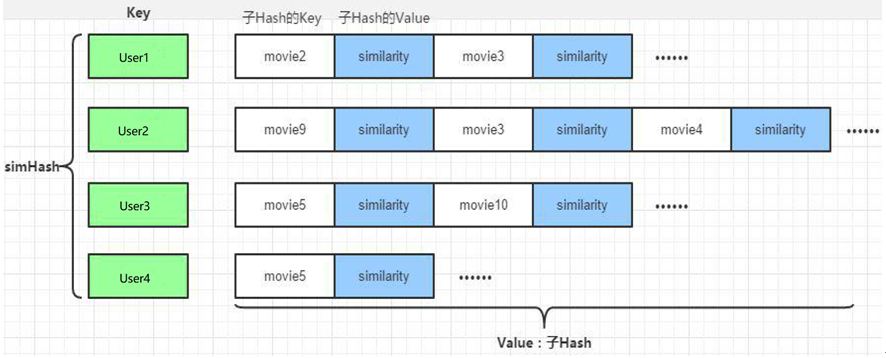
1 用户电影推荐矩阵
通过ALS训练出来的Model来计算所有当前用户电影的推荐矩阵,主要思路如下:
- UserId和MovieID做笛卡尔积,产生(uid,mid)的元组
- 通过模型预测(uid,mid)的元组。
- 将预测结果通过预测分值进行排序。
- 返回分值最大的K个电影,作为当前用户的推荐。
最后生成的数据结构如下:将数据保存到MongoDB的UserRecs表中
新建recommender的子项目OfflineRecommender,引入spark、scala、mongo和jblas的依赖:
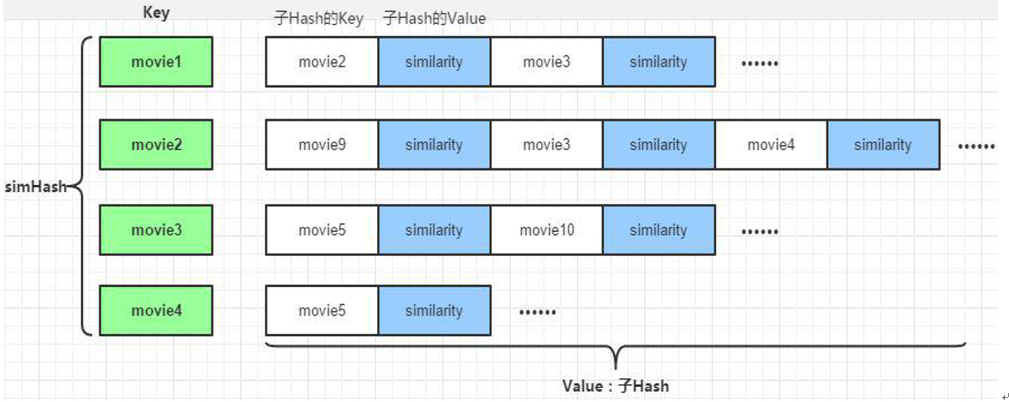
2 电影相似度矩阵
通过ALS计算电影见相似度矩阵,该矩阵用于查询当前电影的相似电影并为实时推荐系统服务。
离线计算的ALS 算法,算法最终会为用户、电影分别生成最终的特征矩阵,分别是表示用户特征矩阵的U(m x k)矩阵,每个用户由 k个特征描述;表示物品特征矩阵的V(n x k)矩阵,每个物品也由 k 个特征描述。
V(n x k)表示物品特征矩阵,每一行是一个 k 维向量,虽然我们并不知道每一个维度的特征意义是什么,但是k 个维度的数学向量表示了该行对应电影的特征。
所以,每个电影用V(n x k)每一行的向量表示其特征,于是任意两个电影 p:特征向量为,电影q:特征向量为之间的相似度sim(p,q)可以使用和的余弦值来表示:
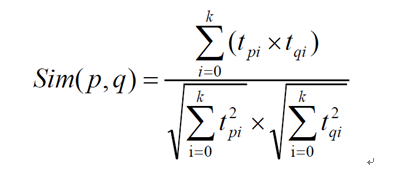
数据集中任意两个电影间相似度都可以由公式计算得到,电影与电影之间的相似度在一段时间内基本是固定值。最后生成的数据保存到MongoDB的MovieRecs表中。
3 模型评估和参数选取
在上述模型训练的过程中,我们直接给定了隐语义模型的rank,iterations,lambda三个参数。对于我们的模型,这并不一定是最优的参数选取,所以我们需要对模型进行评估。通常的做法是计算均方根误差(RMSE),考察预测评分与实际评分之间的误差。
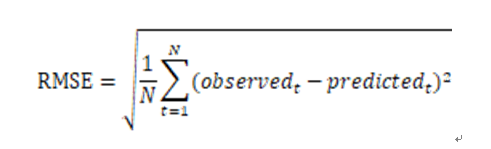
有了RMSE,我们可以就可以通过多次调整参数值,来选取RMSE最小的一组作为我们模型的优化选择。
新建单例对象ALSTrainer,