1. Window概述
一般真实的流都是无界的,怎么处理无界的数据?可以把无限的数据流进行切分,得到有限的数据集进行处理----也就是得到有界流。
streaming流式计算是一种被设计用于处理无限数据集的数据处理引擎,而无限数据集是指一种不断增长的本质上无限的数据集;
而window是把无限数据流为有限流的一种方式,Window将一个无限的stream拆分成有限大小的”buckets”桶,我们可以在这些桶上做计算操作。
Window API
窗口分配器window( )方法 (一般的DataStream可使用windowall( )这种方式开窗,但所有的数据都在一个分区上,这种方式不推荐使用)
我们可以用.window( )来定义一个窗口,然后基于这个window去做一些聚合或者其他处理操作。注意window( )方法必须在KeyBy(按照不同并行度做分区)之后才能用。
Flink提供了更加简单的.timeWindow和.countWindow方法,用于定义时间窗口和计数窗口。
val minTempPerWindow = dataStream.map(r => (r.id, r.temperature))
.keyBy(_._1)
.timeWindow(Time.seconds(15))
.reduce((r1, r2) => (r1._1, r1._2.min(r2._2)))
窗口分配器(window assigner)
window()方法接收的输入参数是一个WindowAssigner,WindowAssigner负责将每条输入的数据分发到正确的window中(是滚动窗口还是滑动窗口呢?窗口大小,步长);
Flink提供了通用的WindowAssigner:滚动窗口(tumbling window)、滑动窗口(sliding window)、会话窗口(session window)、全局窗口(global window)--所有的数据都放这里边,就变成无界流了没有结束时间,一般用来自定义窗口。
窗口操作至少分成2步: ①是.timewindow或者.countwindow ②是聚合操作 如.reduce( ) ;
创建不同类型的窗口:
滚动时间窗口(tumbling time window) .timeWindow(Time.seconds(15)) 滑动时间窗口(sliding time window) .timeWindow(Time.seconds(15), Time.seconds(5)) 会话窗口(session window) .window(EventTimeSessionWindows.withGap(Time.minutes(10)) //间隔10分钟 滚动计数窗口(tumbling count window).countWindow(5) 滑动计数窗口(sliding count window) .countWindow(10, 2) //10个一个窗口,间隔2个滑下。
窗口函数(window function)
window function定义了要对窗口中收集的数据做的计算操作,可以分为两类:
增量聚合函数(incremental aggregation functions):每条数据到来就进行计算,保持一个简单的状态;ReduceFunction, AggregateFunction
全窗口函数(full window functions):先把窗口所有数据都收集起来,等到计算的时候会遍历所有数据ProcessFunctionWindow

其他可选API
.trigger()----触发器:定义window什么时候关闭,触发计算输出结果 .evitor()----移除器:定义移除某些数据的逻辑; .allowedLateness() ---允许处理迟到的数据 .sideOutputLateData() ---将迟到的数据放入侧输出流 .getSideOutput() ----获取侧输出流
Window API总览

2. EventTime、IngestionTime、ProcessingTime
在Flink的流式处理中,会涉及到时间的不同概念,如下图所示
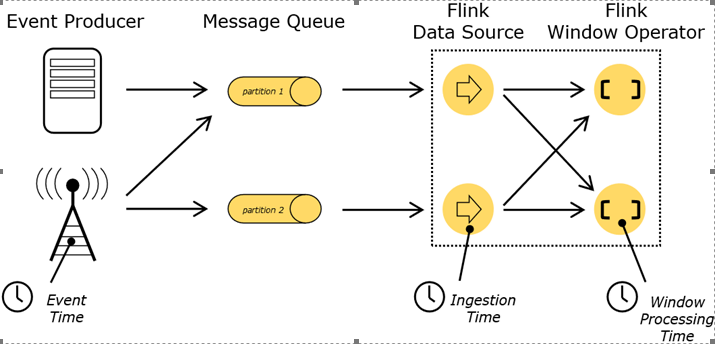
不同的时间语义有不同的应用场景,我们往往更关心事件时间(Event Time--故事发生的时间)。
Event Time:事件创建的时间。它通常由事件中的时间戳描述,例如采集的日志数据中,每一条日志都会记录自己的生成时间,Flink通过时间戳分配器访问事件时间戳。
Ingestion Time:事件-数据进入Flink的时间。
Processing Time:是每一个执行基于时间操作的算子的本地系统时间,与机器相关,默认的时间属性就是Processing Time(事件进入算子的时间)。
例如,一条日志进入Flink的时间为2017-11-12 10:00:00.123,到达Window的系统时间为2017-11-12 10:00:01.234,日志的内容如下:
2017-11-02 18:37:15.624 INFO Fail over to rm2
对于业务来说,要统计1min内的故障日志个数,哪个时间是最有意义的?—— eventTime,因为我们要根据日志的生成时间进行统计。
在代码中设置Event Time
可直接在代码中,对执行环境调用setStreamTimeCharacteristic方法,设置流的时间特性; 具体的时间,还需要从数据中提取时间戳(timestamp); val env = StreamExecutionEnvironment.getExecutionEnvironment //从调用时刻开始给env创建的每一个stream追加时间特征 env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime) 没有设置系统默认按processing time;
3. Watermark--解决乱序问题
我们知道,流处理从事件产生,到流经source,再到operator,中间是有一个过程和时间的,虽然大部分情况下,流到operator的数据都是按照事件产生的时间顺序来的,但是也不排除由于网络、分布式等原因,导致乱序的产生,所谓乱序,就是指Flink接收到的事件的先后顺序不是严格按照事件的Event Time顺序排列的。
乱序数据的影响
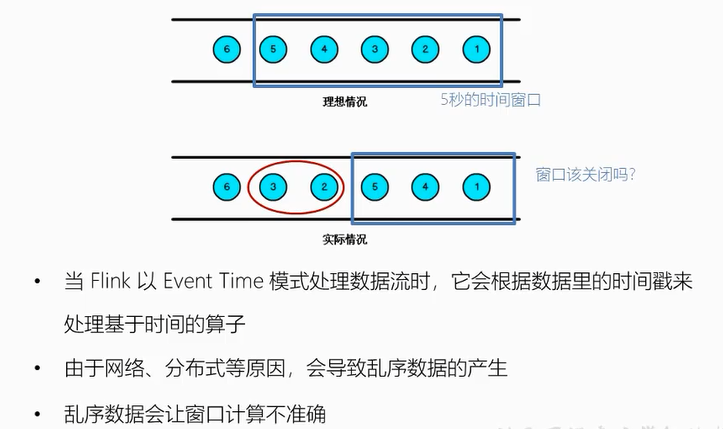
那么此时出现一个问题,一旦出现乱序,如果只根据eventTime决定window的运行(遇到一个时间戳达到了窗口的时间,不应该立刻触发窗口的计算,而是等待一段时间,等迟到的数据来了再关闭窗口),我们不能明确数据是否全部到位,但又不能无限期的等下去,此时必须要有个机制来保证一个特定的时间后,必须触发window去进行计算了,这个特别的机制(延迟触发机制),就是Watermark。
- Watermark是一种衡量Event Time进展的机制,它是数据本身的一个隐藏属性,数据本身携带着对应的Watermark。
- Watermark是用于处理乱序事件的,而正确的处理乱序事件,通常用Watermark机制结合window来实现。
- 数据流中的Watermark用于表示timestamp小于Watermark的数据,都已经到达了,因此,window的执行也是由Watermark触发的。
- Watermark可以理解成一个延迟触发机制,我们可以设置Watermark的延时时长t,每次系统会校验已经到达的数据中最大的maxEventTime,然后认定eventTime小于maxEventTime - t的所有数据都已经到达,如果有窗口的停止时间等于maxEventTime – t,那么这个窗口被触发执行。
- watermark用来让程序自己平衡延迟和结果正确性;
watermark的特点:

watermark的传递
多个输入分区,并行;假如设置为eventtime,1个任务有多个分区,一个分区对应一个分区watermark,数据来一个更新分区内的watermark(只更新比它大的--递增--只涨不跌);多个分区中取最小的watermark为准;
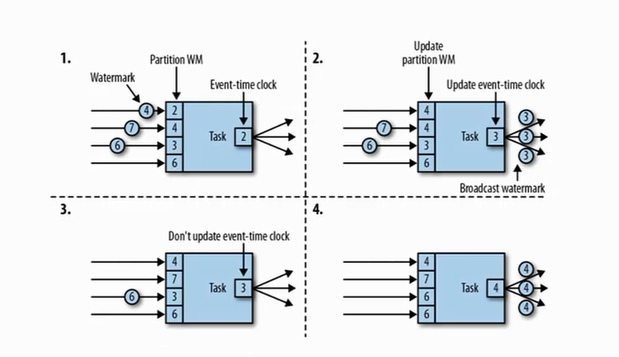
watermark的引入:
Event Time的使用一定要指定数据源的时间戳; 对于排好序的数据,只需要指定时间戳就够了,不需要延迟触发。
//注意单位是毫秒,所以根据时间戳的不同,可能需要乘1000
dataStream.assignAscendingTimestamps(_.timestamp * 1000) //①已经排好序的,就不需延迟触发了
dataStream.assignTimestampsAndWatermarks( // ②同时分配时间戳和水位线
new BoundOutOfOrdernessTimestampExtractor[SensorReading](Time.milliseconds(1000)){ //1000ms是等待延迟的时间
override def extractTimestamp(element: SensorReading): Long = {
element.timestamp * 1000 //取timestamp作为时间戳 单位毫秒
}
})
比如当前5s的数据来了,当前设置了延迟1s,水位线watermark就是4s(不认为5s之前的数据都来了,只认为4s之前的数据都来了);
Flink暴露了TimestampAssigner接口供我们实现,使我们可以自定义如何从事件数据中抽取时间戳和生产watermark
dataStream.assignTimestampsAndWatermarks(new MyAssigner()) //③自定义MyAssigner可以有两种类型,都继承自TimestampAssigner
TimestampAssigner 定义了抽取时间戳,以及生产watermark的方法,有两种类型:
①AssignerWithPeriodicWatermarks
- 周期性的生成watermark:系统会周期性的(processingTime)将watermark插入到流中;
- 默认周期是200毫秒,可以使用ExecutionConfig.setAutoWatermarkInterval()方法进行设置;
- 升序和前面乱序的处理BoundedOutOfOrderness,都是基于周期性watermark的。
②AssignerWithPunctuatedWatermarks
- 没有时间周期规律,可打断的生产watermark。
watermark的设定:
- 在Flink中,watermark由应用程序开发人员生成,这通常需要对应的领域有一定的了解;
- 如果watermark设置的延迟太久,收到结果的速度可能就会很慢,解决办法是在水位线到达之前输出一个近似结果;
- 而如果watermark到达得太早,则可能收到错误结果,不过Flink处理迟到数据的机制可以解决这个问题。
4. Window可以分成两类:
时间窗口TimeWindow:滚动时间窗口(Tumbling Window)、滑动时间窗口(Sliding Window)、会话时间窗口(Session Window)。
计数窗口CountWindow:按照指定的数据条数生成一个Window,与时间无关。分为滚动计数窗口、滑动计数窗口。
TimeWindow
- 1. 滚动窗口(Tumbling Windows)
将数据依据固定的窗口长度对数据进行切片。
特点:时间对齐,窗口长度固定,没有重叠。 它是步长 = site的滑动窗口;
使用场景:商业BI分析统计(关注的商业指标往往是某个时间段的指标,如一天或一周的销售额,每个时间段的聚合操作);
滚动窗口分配器将每个元素分配到一个指定窗口大小的窗口中,滚动窗口有一个固定的大小,并且不会出现重叠。例如:如果你指定了一个5分钟大小的滚动窗口,窗口的创建如下图所示:
import org.apache.flink.api.java.tuple.Tuple import org.apache.flink.streaming.api.TimeCharacteristic import org.apache.flink.streaming.api.functions.timestamps.BoundedOutOfOrdernessTimestampExtractor import org.apache.flink.streaming.api.scala.{DataStream, KeyedStream, StreamExecutionEnvironment, WindowedStream} import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows import org.apache.flink.streaming.api.windowing.time.Time import org.apache.flink.streaming.api.windowing.windows.TimeWindow import org.apache.flink.api.scala._ object StreamEventTimeApp { def main(args: Array[String]): Unit = { //环境 val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment //声明使用eventTime;引入EventTime 从调用时刻开始给env创建的每一个stream追加时间特征 env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
val dstream: DataStream[String] = env.socketTextStream("hadoop101", 7777) val textWithTsDStream: DataStream[(String, Long, Int)] = dstream.map { text => val arr: Array[String] = text.split(" ") (arr(0), arr(1).toLong, 1) } // 1 告知 flink如何获取数据中的event时间戳 2 告知延迟的watermark为 3s val textWithEventTimeDStream: DataStream[(String, Long, Int)] = textWithTsDStream.assignTimestampsAndWatermarks( new BoundedOutOfOrdernessTimestampExtractor[(String, Long, Int)](Time.milliseconds(3000)) { //time别导错包了 override def extractTimestamp(element: (String, Long, Int)): Long = { return element._2 } }).setParallelism(1) //每5秒开一个窗口 统计key的个数 5秒是一个数据的时间戳为准 val textKeyStream: KeyedStream[(String, Long, Int), Tuple] = textWithEventTimeDStream.keyBy(0) textKeyStream.print("textKey: ") //滚动窗口 val windowStream: WindowedStream[(String, Long, Int), Tuple, TimeWindow] = textKeyStream.window(TumblingEventTimeWindows.of(Time.milliseconds(5000))) windowStream.sum(2).print("windows: ").setParallelism(1) env.execute() }
[kris@hadoop101 gmall]$ nc -lk 7777 abc 1000 abc 3000 abc 4000 abc 5000 abc 6000 abc 7000 abc 7500 abc 8000 abc 9000 abc 12000 abc 12999 abc 14000 abc 15000 abc 17000 abc 18000 textKey: :8> (abc,1000,1) textKey: :8> (abc,3000,1) textKey: :8> (abc,4000,1) textKey: :8> (abc,5000,1) textKey: :8> (abc,6000,1) textKey: :8> (abc,7000,1) textKey: :8> (abc,7500,1) textKey: :8> (abc,8000,1) Window: > (abc,1000,3) textKey: :8> (abc,9000,1) textKey: :8> (abc,12000,1) textKey: :8> (abc,12999,1) Window: > (abc,5000,6) textKey: :8> (abc,14000,1) textKey: :8> (abc,15000,1) textKey: :8> (abc,17000,1) textKey: :8> (abc,18000,1) Window: > (abc,12000,3) 滚动窗口: X秒开一个窗口,上例中5s开一个窗; 上例watermark 3s 第n次发车时间:nX+3,车上携带的[X, nX)秒内的 如第一次车上携带 [0, 5)以内的,在第 5 + 3 = 8s时间点发车
第二次车上携带 [5, 10)以内的,在第10 + 3 = 13s时间点发车
第三次车上携带 [10, 15)以内的,在第15 + 3 = 18s时间点发车;
延迟3s, 不认为当前时间的数据都来了, 认为当前时间 - 3s之前的数据都来了;
上例中如果是不同key的结果如下:
在KeyBy之前分配的时间戳和watermark,并行度为1,都是在一个slot里边,都是一个任务;
KeyBy之后是想把它分到不同的分区,那么前边的watermark(多个输入多个输出,对于前边source而言是多个输出,这个watermark要广播出去)
不同key的数据来了之后,相当于先来的key的watermark也会跟着涨; <===> watermark的传递;
textKey::6> (a,2000,1)
textKey::6> (a,3000,1)
textKey::2> (b,4000,1)
textKey::2> (b,5000,1)
textKey::6> (a,6000,1)
textKey::2> (b,7000,1)
textKey::6> (a,7999,1)
windows: :6> (a,2000,2)
windows: :2> (b,4000,1)
textKey::2> (b,9000,1)
textKey::6> (a,9998,1)
textKey::2> (b,11000,1)
textKey::6> (a,12998,1)
textKey::2> (b,13000,1)
windows: :2> (b,5000,3)
windows: :6> (a,6000,3)- 2. 滑动窗口(Sliding Windows)
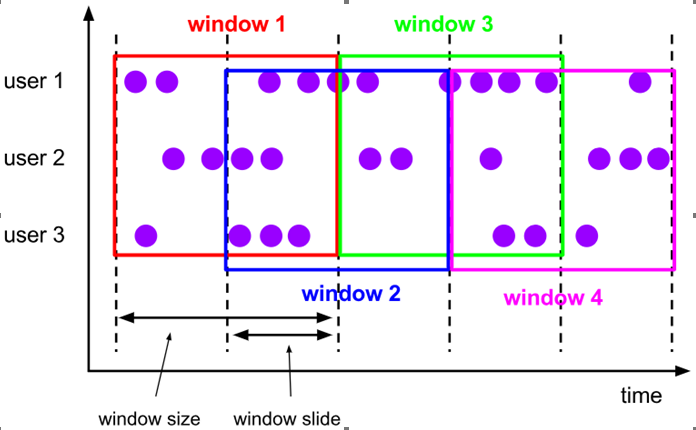
滑动窗口是固定窗口的更广义的一种形式,滑动窗口由固定的窗口长度和滑动间隔组成。
特点:窗口长度固定,有重叠。
适用场景:对最近一个时间段内的统计(求某接口最近5min的失败率来决定是否要报警);
灵活;连续的波浪;比如股票交易所它是最近24小时的涨跌幅度,随时往后算随时往后划;
滑动窗口分配器将元素分配到固定长度的窗口中,与滚动窗口类似,窗口的大小由窗口大小参数来配置,另一个窗口滑动参数控制滑动窗口开始的频率。因此,滑动窗口如果滑动参数小于窗口大小的话,窗口是可以重叠的,在这种情况下元素会被分配到多个窗口中。
例如,你有10分钟的窗口和5分钟的滑动,那么每个窗口中5分钟的窗口里包含着上个10分钟产生的数据,如下图所示:
测试代码:


import org.apache.flink.api.java.tuple.Tuple import org.apache.flink.streaming.api.TimeCharacteristic import org.apache.flink.streaming.api.scala.{DataStream, KeyedStream, StreamExecutionEnvironment, WindowedStream} import org.apache.flink.api.scala._ import org.apache.flink.streaming.api.functions.timestamps.BoundedOutOfOrdernessTimestampExtractor import org.apache.flink.streaming.api.windowing.assigners.{SlidingEventTimeWindows, TumblingEventTimeWindows} import org.apache.flink.streaming.api.windowing.time.Time import org.apache.flink.streaming.api.windowing.windows.TimeWindow object WindowApi { def main(args: Array[String]): Unit = { //环境 val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment //env.setParallelism(1) 全局并行度设为1 //声明使用eventTime env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime) val dstream: DataStream[String] = env.socketTextStream("hadoop101", 7777) val textWithTsDStream = dstream.map{ text => val arr: Array[String] = text.split(" ") (arr(0), arr(1).toLong, 1) } // 1 告知 flink如何获取数据中的event时间戳 2 告知延迟的watermark val textWithEventTimeDStream: DataStream[(String, Long, Int)] = textWithTsDStream.assignTimestampsAndWatermarks( new BoundedOutOfOrdernessTimestampExtractor[(String, Long, Int)](Time.milliseconds(3000)) { override def extractTimestamp(element: (String, Long, Int)): Long = { return element._2 } }).setParallelism(1) //只要它的并行度为1就可以了, 其他的算子不需设并行度为1 val textKeyStream: KeyedStream[(String, Long, Int), Tuple] = textWithEventTimeDStream.keyBy(0) textKeyStream.print("textKey:") //滚动窗口 //val windowStream: WindowedStream[(String, Long, Int), Tuple, TimeWindow] = textKeyStream.window(TumblingEventTimeWindows.of(Time.milliseconds(5000))) //滑动窗口 大小4s, 步长2s, 延迟3s val windowStream: WindowedStream[(String, Long, Int), Tuple, TimeWindow] = textKeyStream.window(SlidingEventTimeWindows.of(Time.milliseconds(4000L), Time.milliseconds(2000L))) windowStream.sum(2).print("windows: ").setParallelism(1) env.execute("Window Stream") } }
如果watermark = 0,窗口大小为5,步长为3s的滑动窗口:
val textWithEventTimeDStream: DataStream[(String, Long, Int)] = textWithTsDStream.assignTimestampsAndWatermarks(
new BoundedOutOfOrdernessTimestampExtractor[(String, Long, Int)](Time.milliseconds(0)) { //time别导错包了
override def extractTimestamp(element: (String, Long, Int)): Long = {
return element._2
}
}).setParallelism(1)
//滑动窗口
val windowStream: WindowedStream[(String, Long, Int), Tuple, TimeWindow] = textKeyStream.window(SlidingEventTimeWindows.of(Time.milliseconds(5000L), Time.milliseconds(3000L)))
windowStream.sum(2).print("windows: ").setParallelism(1)
watermark=0,窗口大小5s, 步长3s :
[kris@hadoop101 ~]$ nc -lk 7777
abc 500
abc 1000
abc 1998
abc 1999
abc 2000 --[0, 2)
abc 3000
abc 4000
abc 4998
abc 4999
abc 5000 --[0, 5)
abc 6000
abc 7000
abc 7998
abc 7999
abc 8000 --[3, 8)
abc 9000
abc 10000
abc 10998
abc 10999
abc 11000 --[6, 11)
abc 12000
abc 13000
abc 13999
abc 14000 --[9, 14)
textKey::8> (abc,500,1)
textKey::8> (abc,1000,1)
textKey::8> (abc,1998,1)
textKey::8> (abc,1999,1)
windows: > (abc,500,4) --[0, 2)
textKey::8> (abc,2000,1)
textKey::8> (abc,3000,1)
textKey::8> (abc,4000,1)
textKey::8> (abc,4998,1)
textKey::8> (abc,4999,1)
windows: > (abc,500,9) --[0, 5)
textKey::8> (abc,5000,1)
textKey::8> (abc,6000,1)
textKey::8> (abc,7000,1)
textKey::8> (abc,7998,1)
textKey::8> (abc,7999,1)
windows: > (abc,3000,9) --[3, 8)
textKey::8> (abc,8000,1)
textKey::8> (abc,9000,1)
textKey::8> (abc,10000,1)
textKey::8> (abc,10998,1)
textKey::8> (abc,10999,1)
windows: > (abc,6000,9) --[6, 11)
textKey::8> (abc,11000,1)
textKey::8> (abc,12000,1)
textKey::8> (abc,13000,1)
textKey::8> (abc,13999,1)
windows: > (abc,9000,8) --[9, 14)
textKey::8> (abc,14000,1)
关于滑动窗口触发执行的时间点:
watermark=0,窗口大小10s, 步长5s, [0, 5) [0, 10) [5, 15) [10, 20) [15, 25) [20, 30)
watermark=0,窗口大小5s, 步长2s, [0, 1) [0, 3) [0, 5) [2, 7) [4, 9)
watermark=0,窗口大小5s, 步长3s, [0, 2) [0, 5) [3, 8) [6, 11) [9, 14)
watermark=0,窗口大小4s, 步长2s, [0, 2) [0, 4) [2, 6) [4, 8) [6, 10)
触发窗口执行的时间点为:如果是整数倍就是步长,否则就是余数
如watermark=0,窗口大小4s, 步长2s,触发窗口执行的时间点为2s ;
watermark=0,窗口大小6s, 步长3s,触发窗口执行的时间点为3s ;
watermark=0,窗口大小10s, 步长5s, 触发窗口执行的时间点为5s ;
---------以上为整数倍,以下为余数-----------
watermark=0,窗口大小5s, 步长3s,触发窗口执行时间点为2s (5%3=2);
watermark=0,窗口大小5s, 步长2s,触发窗口执行时间点为1s (5%2=1);
如果watermark = 3,窗口大小为5,步长为1s的滑动窗口:
val textWithEventTimeDStream: DataStream[(String, Long, Int)] = textWithTsDStream.assignTimestampsAndWatermarks(
new BoundedOutOfOrdernessTimestampExtractor[(String, Long, Int)](Time.milliseconds(3000)) {
override def extractTimestamp(element: (String, Long, Int)): Long = {
return element._2
}
}).setParallelism(1) //只要它的并行度为1就可以了, 其他的算子不需设并行度为1
val windowStream: WindowedStream[(String, Long, Int), Tuple, TimeWindow] = textKeyStream.window(SlidingEventTimeWindows.of(Time.milliseconds(5000L), Time.milliseconds(1000L)))
Time.milliseconds(5000L)---开车接多少人(5s内的),
Time.milliseconds(1000L)---步长决定了触发开车的时机,如果为5000L则跟滚动窗口是一样的;
Time.milliseconds(3000L)---水位线是3s, 1s时触发开车,但延迟3s;
5s的窗口大小,1s的步长,3s的延迟
[kris@hadoop101 ~]$ nc -lk 7777
abc 100
abc 1000
abc 3998
abc 3999
abc 5000
abc 8000
abc 10000
=======================>
textKey::8> (abc,100,1)
textKey::8> (abc,1000,1)
textKey::8> (abc,3998,1)
textKey::8> (abc,3999,1) //开车的时间点在1s,虽然成可以装下5s内的,但是开车的时候那里边只有1个
windows: > (abc,100,1) --1s开车
textKey::8> (abc,5000,1) //开车的时间点在2s,但延迟3s,5s内的都可以,数据时间还不到5s,前边有多少算多少;(将2s以前,5s内的接走)
windows: > (abc,100,2) --2s开车
textKey::8> (abc,8000,1) //8000--> -3000 = 5000,4000,3000 ,2000,1000(这两个发车时间点前边已经发过了)各会发车
windows: > (abc,100,2) --3s开车
windows: > (abc,100,4) --4s开车
windows: > (abc,100,4) --5s开车
textKey::8> (abc,10000,1) //10000--> -3000 = 7000[2000, 7000),6000[1000, 6000)
windows: > (abc,1000,4) --6s开车
windows: > (abc,3998,3) --7s开车
滑动窗口:
窗口大小5s(X), 步长1s(Y), 水位线watermark 3s(Z)
1s开车, 延迟3s, 1 + 3 = 4s, 带走[0, 4)以内的,但时间只是到了1s, 即[0, 1)以内的
2s开车, 延迟3s, 2 + 3 = 5s, 带走[0, 5)以内的,但时间只是到了2s, 即[0, 2)以内的
3s开车, 延迟3s, 3 + 3 = 6s, 带走[1, 6)以内的,但时间只是到了3s, 即[0, 3)以内的
4s开车, 延迟3s, 4 + 3 = 7s, 带走[2, 7)以内的,但时间只是到了4s, 即[0, 4)以内的
5s开车, 延迟3s, 5 + 3 = 8s, 带走[3, 8)以内的,但时间只是到了5s, 即[0, 5)以内的
6s开车, 延迟3s, 6 + 3 = 9s, 带走[4, 9)以内的,但时间只是到了6s, 即[1, 6)以内的
7s开车, 延迟3s, 7 + 3 = 10s, 带走[5, 10)以内的,但时间只是到了7s, 即[2, 7)以内的
...
nYs开车, 延迟Zs, n + Z, 带走[n+Z-X ,n+Z)以内的,但时间只是到了nYs, 即[nY-X, nY)以内的
watermark = 2s, 窗口大小6s, 步长3s :
// 1 告知 flink如何获取数据中的event时间戳 2 告知延迟的watermark
val textWithEventTimeDStream: DataStream[(String, Long, Int)] = textWithTsDStream.assignTimestampsAndWatermarks(
new BoundedOutOfOrdernessTimestampExtractor[(String, Long, Int)](Time.milliseconds(2000)) {
override def extractTimestamp(element: (String, Long, Int)): Long = {
return element._2
}
}).setParallelism(1) //只要它的并行度为1就可以了, 其他的算子不需设并行度为1
//滑动窗口 大小6s, 步长3s, 延迟2s
val windowStream: WindowedStream[(String, Long, Int), Tuple, TimeWindow] = textKeyStream.window(SlidingEventTimeWindows.of(Time.seconds(6), Time.seconds(3)))
[kris@hadoop101 ~]$ nc -lk 7777
abc 1000
abc 2000
abc 3000
abc 4998
abc 4999
abc 5000 --
abc 7998
abc 7999
abc 8000 --
abc 10998
abc 10999
abc 11000 --
abc 13998
abc 13999
abc 14000 --
abc 16998
abc 16999
abc 17000 --
abc 19998
abc 19999
abc 20000 --
textKey::8> (abc,1000,1)
textKey::8> (abc,2000,1)
textKey::8> (abc,3000,1)
textKey::8> (abc,4998,1)
textKey::8> (abc,4999,1)
windows: :8> (abc,1000,2) --[0, 3)
textKey::8> (abc,5000,1)
textKey::8> (abc,7998,1)
textKey::8> (abc,7999,1)
windows: :8> (abc,1000,6) --[0, 6)
textKey::8> (abc,8000,1)
textKey::8> (abc,10998,1)
textKey::8> (abc,10999,1)
windows: :8> (abc,3000,7) --[3, 9)
textKey::8> (abc,11000,1)
textKey::8> (abc,13998,1)
textKey::8> (abc,13999,1)
windows: :8> (abc,7998,6) --[6, 12)
textKey::8> (abc,14000,1)
textKey::8> (abc,16998,1)
textKey::8> (abc,16999,1)
windows: :8> (abc,10998,6) --[9, 15)
textKey::8> (abc,17000,1)
textKey::8> (abc,19998,1)
textKey::8> (abc,19999,1)
windows: :8> (abc,13998,6) --[12, 18)
textKey::8> (abc,20000,1)
3s开车, 延迟2s, 3 + 2 = 5s, 带走[0, 5)以内的,但时间只是到了3s, 即[0, 3)以内的
6s开车, 延迟2s, 6 + 2 = 8s, 带走[2, 8)以内的,但时间只是到了6s, 即[0, 6)以内的
9s开车, 延迟2s, 9 + 2 = 11s, 带走[5, 11)以内的,但时间只是到了9s, 即[3, 9)以内的
12s开车, 延迟2s, 12 + 2 = 14s, 带走[8, 14)以内的,但时间只是到了12s, 即[6, 12)以内的
15s开车, 延迟2s, 15 + 2 = 17s, 带走[11, 17)以内的,但时间只是到了15s, 即[9, 15)以内的
18s开车, 延迟2s, 18 + 2 = 20s, 带走[14, 20)以内的,但时间只是到了18s, 即[12, 18)以内的
...
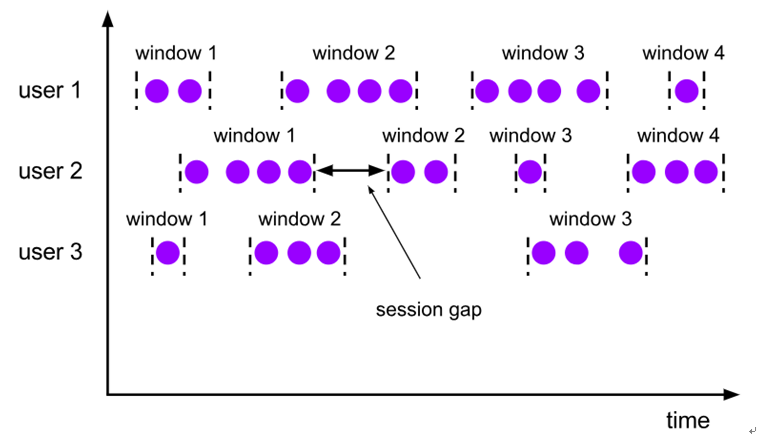
- 3. 会话窗口(Session Windows)
由一系列事件组合一个指定时间长度的timeout间隙组成,类似于web应用的session,也就是一段时间没有接收到新数据就会生成新的窗口。
特点:时间无对齐。
session窗口分配器通过session活动来对元素进行分组,session窗口跟滚动窗口和滑动窗口相比,不会有重叠和固定的开始时间和结束时间的情况,相反,当它在一个固定的时间周期内不再收到元素,即非活动间隔产生,那个这个窗口就会关闭。一个session窗口通过一个session间隔来配置,这个session间隔定义了非活跃周期的长度,当这个非活跃周期产生,那么当前的session将关闭并且后续的元素将被分配到新的session窗口中去。
object StreamEventTimeApp { def main(args: Array[String]): Unit = { //环境 val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment //声明使用eventTime env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime) val dstream: DataStream[String] = env.socketTextStream("hadoop101", 7777) val textWithTsDStream: DataStream[(String, Long, Int)] = dstream.map { text => val arr: Array[String] = text.split(" ") (arr(0), arr(1).toLong, 1) } // 1 告知 flink如何获取数据中的event时间戳 2 告知延迟的watermark val textWithEventTimeDStream: DataStream[(String, Long, Int)] = textWithTsDStream.assignTimestampsAndWatermarks( new BoundedOutOfOrdernessTimestampExtractor[(String, Long, Int)](Time.milliseconds(3000)) { //time别导错包了 override def extractTimestamp(element: (String, Long, Int)): Long = { return element._2 } }).setParallelism(1) //每5秒开一个窗口 统计key的个数 5秒是一个数据的时间戳为准 val textKeyStream: KeyedStream[(String, Long, Int), Tuple] = textWithEventTimeDStream.keyBy(0) textKeyStream.print("textKey: ") //滚动窗口 //val windowDStream: WindowedStream[(String, Long, Int), Tuple, TimeWindow] = textKeyStream.window(TumblingEventTimeWindows.of(Time.milliseconds(5000))) //滑动窗口 //val windowStream: WindowedStream[(String, Long, Int), Tuple, TimeWindow] = textKeyStream.window(SlidingEventTimeWindows.of(Time.milliseconds(5000L), Time.milliseconds(1000L))) //会话窗口 val windowStream: WindowedStream[(String, Long, Int), Tuple, TimeWindow] = textKeyStream.window(EventTimeSessionWindows.withGap(Time.milliseconds(5000L))) windowStream.sum(2).print("windows: ").setParallelism(1) env.execute() } } 只能两次时间的间隔是否满足条件 在触发水位5s的基础上再加延迟3s, [kris@hadoop101 gmall]$ nc -lk 7777 abc 1000 abc 7000 abc 10000 =======>>> textKey: :8> (abc,1000,1) textKey: :8> (abc,7000,1) textKey: :8> (abc,10000,1) //在上一个基础上+延迟时间3s才会开车 windows: > (abc,1000,1) [kris@hadoop101 gmall]$ nc -lk 7777 aaa 1000 aaa 2000 aaa 7001 aaa 9000 aaa 10000 =====>> textKey: :5> (aaa,1000,1) textKey: :5> (aaa,2000,1) textKey: :5> (aaa,7001,1) //两个时间点之间相差达到鸿沟5s了,在这个基础之上再加3s才能开车; textKey: :5> (aaa,9000,1) textKey: :5> (aaa,10000,1) windows: > (aaa,1000,2)
CountWindow
CountWindow根据窗口中相同key元素的数量来触发执行,执行时只计算元素数量达到窗口大小的key对应的结果。
注意:CountWindow的window_size指的是相同Key的元素的个数,不是输入的所有元素的总数。
滚动窗口
默认的CountWindow是一个滚动窗口,只需要指定窗口大小即可,当元素数量达到窗口大小时,就会触发窗口的执行。
滑动窗口
滑动窗口和滚动窗口的函数名是完全一致的,只是在传参数时需要传入两个参数,一个是window_size,一个是sliding_size。
下面代码中的sliding_size设置为了2,也就是说,每收到两个相同key的数据就计算一次,每一次计算的window范围是5个元素。
WindowAPI

Windowall是所有数据都在一个分区上;keyBy之后是分到各个分区再window去处理