一些名词概念
AM : ApplicationMaster RM : ResourceManager NM : NodeManager Backend : 后台 RpcEnv : RPC 进程和进程的通信协议 RpcEndpoint : 终端 constructor -> onStart -> receive* -> onStop RpcEndpointRef :终端引用 NettyRpcEnv RpcEndpointAddress NettyRpcEndpointRef ThreadSafeRpcEndpoint Inbox BIO, NIO, AIO
以yarn-cluster模式为例源码分析作业提交流程
##spark-yarn-cluster模式
bin/spark-submit --class org.apache.spark.examples.SparkPi --num-executors 2 --master yarn --deploy-mode cluster ./examples/jars/spark-examples_2.11-2.1.1.jar 100
##spark-yarn-client模式 bin/spark-submit --class org.apache.spark.examples.SparkPi --num-executors 2 --master yarn --deploy-mode client ./examples/jars/spark-examples_2.11-2.1.1.jar 100
Spark-submit提交源码解析
执行spark-submit实际上执行的是$SPARK_HOME/spark-class -->执行一个java类 java org.apache.spark.launcher.Main调它的main方法(它就是检查参数、构建CommandBuiler指令)--->最终真正要执行 这个类 org.apache.spark.deploy.SparkSubmit xxx是命令行参数,它就会启动一个叫SparkSubmit进程
SparkSubmit类,对命令行参数进行了封装,准备提交环境,不是集群模式它会拿到指令中的--class所传的类, if (isYarnCluster)-->> org.apache.spark.deploy.yarn.Client
利用反射通过类名获取类的信息,利用反射通过类信息获取Main方法,调用Client的main方法: Client的调用只是一个普通方法的调用
根据yarn的配置进行初始化创建yarn客户端准备去跟yarn打交道(要有yarn的server集群), yarnClient.start()启动客户端,获取一个appId,yarn的全局id,根据id可以查询它的所有信息;
Client向yarn的RM提交应用, 集群模式通过submitApplication来完成,启动JAVA_HOME/bin/java org.apache.spark.deploy.yarn.ApplicationMaster这个进程类(主要是为了与Yarn做关联)
这些commands上边封装好的指令|类都提交给yarn,由yarn来执行,这时Client客户端就结束了;
spark-submit 它实际上调用的是"${SPARK_HOME}"/bin/spark-class org.apache.spark.deploy.SparkSubmit (java中的类) spark-class中: RUNNER="${JAVA_HOME}/bin/java" ##执行java.exe-->类 -->相当于启动一个JVM -->就是启动一个进程Process(进程中有独立内存、线程) "$RUNNER" -Xmx128m -cp "$LAUNCH_CLASSPATH"(#就是类路径) org.apache.spark.launcher.Main <=>等同于执行Main这个类,调用main方法 build_command()构建指令; 最终是要执行SparkSubmit ##className.equals("org.apache.spark.deploy.SparkSubmit") org.apache.spark.launcher.Main org.apache.spark.deploy.SparkSubmit --xx等参数
SparkSubmit类 // 对命令行参数进行封装 -- 1. new SparkSubmitArguments(args) //命令行参数包含master、deployMode、executorMemory等 ;在scala中,类{ 类体or构造函数体 },参数中类体,类初始化时都会执行 parse(args.asJava)类体中;parse方法做了正则的匹配 Pattern.compile("(--[^=]+)=(.+)") ==> handle (源码326)方法对传的命令行参数做模式匹配;
SparkSubmit类,appArgs.action.match{ SUBMIT| ... }模式匹配,action在SparkSubmitArguments做了封装 action = Option(action).getOrElse(SUBMIT) -- 2. submit(SparkSubmit中的方法) // 准备提交环境 -- 2.1 prepareSubmitEnvironment -- 2.2 doRunMain(声明了但没有执行) isStandaloneCluster 和 其他模式都会走doRunMain方法 -- 2.3 runMain(childArgs, childClasspath, sysProps, childMainClass, args.verbose)参数来自提交对环境准备 <--if (args.proxyUser != null) -- 2.3.1 ClassLoader : Thread.currentThread.setContextClassLoader(loader) //loader类加载器,把类放到集群的节点上去执行; // childMainClass(Client) : org.apache.spark.examples.SparkPi //不是集群模式它会拿到指令中的--class所传的类 // childMainClass(Clustor) : org.apache.spark.deploy.yarn.Client // if (isYarnCluster)集群模式 // 反射:通过类名获取类的信息 -- 2.3.2 mainClass = Utils.classForName(childMainClass) //var mainClass: Class[_] = null,Class为类的全部信息; // 反射:通过类信息获取Main方法 -- 2.3.3 val mainMethod = mainClass.getMethod("main", new Array[String](0).getClass) // 反射:调用main方法 -- 2.3.4 mainMethod.invoke(null, childArgs.toArray)
Client Client的调用只是一个普通方法的调用;如果是进程:java Client=》JVM=》Process; 如果是线程:Thread.start() ; 普通方法调用: method.invoke // 对命令行参数进行封装 -- 1. new ClientArguments(argStrings) //在main方法中 -- 2. new Client(args, sparkConf).run() //它会去调用辅助构造方法-->一定会会去调用主构造方法 private val yarnClient = YarnClient.createYarnClient //它去创建yarn客户端准备去跟yarn打交道(要有yarn的server集群)
private val amMemory = if (isClusterMode) //ApplicationMaster的内存
...等等,主要是去构造属性、方法和对象
-- 3. client.run //创建好了对象.run -- 3.1 submitApplication //this.appId = submitApplication() 提交应用; launcherBackend.connect() //Backend叫后台
yarnClient.init(yarnConf) 根据yarn的配置进行初始化; yarnClient.start()启动客户端 ,目的是与yarn做交互;
appId = newAppResponse.getApplicationId()//获取一个appId,yarn的全局id,根据id可以查询它的所有信息;
yarnClient.submitApplication(appContext) //Client向yarn的RM提交应用,由submitApplication(抽象方法->实现类)来完成;
rmClient.submitApplication(request); //跟RM做关联
// commands(Client): JAVA_HOME/bin/java org.apache.spark.deploy.yarn.ExecutorLauncher //不是集群模式 Spark-shell只能是client模式,不能是集群!! // commands(Clustor):JAVA_HOME/bin/java org.apache.spark.deploy.yarn.ApplicationMaster//如果是集群模式,isClusterMode就把类对名字给amClass;启动一个ApplicationMaster进程
//这些commands上边封装好的指令类都提交给yarn,由yarn来执行,这时Client客户端就结束了; -- 3.1.1 createContainerLaunchContext //要去封装一个指令bin/java javaOpts ++ amArgs(这个参数中Seq(amClass)) ++ 启动一个进程执行ApplicationMaster -- 3.1.2 createApplicationSubmissionContext
val containerContext = createContainerLaunchContext(newAppResponse)
val appContext = createApplicationSubmissionContext(newApp, containerContext) //它调用的是上边的;
// 向Yarn提交应用 -- 3.1.3 yarnClient.submitApplication(appContext) //把上边封装好的给yarnClient(相当于这些指令发给它);在yarn中执行,Client把类提交给yarn之后就完成了
yarn的调度流程 https://www.cnblogs.com/shengyang17/p/10321228.html
SparkSubmit进程(启动一个java虚拟机即启动一个进程名字就叫SparkSubmit) -->调用Client方法,YarnClient去创建yarn客户端并启动, submitApplication()---launcherBackend.connect() ;
Client的submitApplication(抽象方法->去找它的实现类YarnClientImpl)向RM提交应用完成之后; rmClient.submitApplication(request)来跟RM做关联;
createContainerLaunchContext去启动一个进程执行ApplicationMaster;
yarnClient.submitApplication(appContext) //把上边封装好的给yarnClient(相当于这些指令发给它),Client把类提交给yarn之后就完成了
ApplicationMaster -- 1. main -- 1.1. new ApplicationMasterArguments(args) //同上,封装了--jar, --class等 -- 1.2. master = new ApplicationMaster(amArgs, new YarnRMClient) yarnConf
heartbeatInterval心跳周期
RpcEnv : RPC 进程和进程的通信协议
RpcEndpoint : 终端 RpcEndpointRef:终端引用 -- 1.3. master.run // 集群模式它运行的是Driver;如果不是集群模式运行的就是ExecutorLauncher -- 1.3.1 runDriver() //isClusterMode
// 启动用户应用 就是提交的类 -- 1.3.1.1 startUserApplication()--->即启动一个Driver线程 // 从命令行参数中获取--class的值,然后获取main方法; 用类加载器加载类 userClass封装类名(从命令行中获取) -- val mainMethod = userClassLoader.loadClass(args.userClass).getMethod("main", classOf[Array[String]])
-- new Thread("Driver").start() ==> --class.invoke(main) 启动之前:userThread.setContextClassLoader(userClassLoader) //类加载器放进去
userThread.setName("Driver") //真正的Driver是一个线程,只是把这个线程起个名字叫Driver
userThread.start() //启动之后肯定会运行线程的run方法 mainMethod.invoke(main);创建SparkConetext的那个类叫Driver,就是你写的那个main方法 虽然start,但什么时候执行不确定, userClassThread.join() //主线程不能结束,要等待它
rpcEnv = sc.env.rpcEnv构建环境对象
// 向Yarn注册AM -- 1.3.1.2 registerAM()//client. allocator = client.register()
allocator.allocateResources() 它们进行注册和分配,申请资源,看看哪个资源可用 allocateResources资源列表;
val allocatedContainers = allocateResponse.getAllocatedContainers() //以container的形式把资源给你,allocatedContainers是列表 // 分配可用资源 (移动数据不如移动计算(计算在Driver,数据在executor,任务task发给哪个节点),本地化级别) -- handleAllocatedContainers 本地化(计算和数据在同一个进程里)本地化(进程本地化即计算和数据中同一个进程 |节点本地化即一个节点有多个executor,发给另外一个executor|机架本地化,发给另外一个nodemanager) -- runAllocatedContainers() //运行已经分配好的容器 -- launcherPool.execute(线程) <-- if(launchContainers) private val launcherPool = ThreadUtils.newDaemonCachedThreadPool //ThreadPool线程池 --> val threadPool = new ThreadPoolExecutor(),底层还是调用了jdk的线程池的操作 launcherPool.execute(new Runnable{ run(方法 new ExecutorRunnable).run( 与nmClient(即nodemanager的关联) ) }) //启动一个线程来执行操作,从线程池里边去执行一个线程 -- ExecutorRunnable.run() //nmClient.init(conf) nmClient.start() startContainer() 要去连接NM -- nmClient.start() // 启动容器 -- startContainer // JAVA_HOME/bin/java org.apache.spark.executor.CoarseGrainedExecutorBackend //执行器的后台,数据对接收处理,在NM中执行; -- val commands = prepareCommand() -- nmClient.startContainer(container.get, ctx) //由NM(AM就在这里边)来启动这个容器;xtx就是commands指令 CoarseGrainedExecutorBackend 粗粒度的 -- 1. main -- 1.1. run //var executor: Executor = null //所谓的Executor是后台CoarseGrainedExecutorBackend的一个计算对象,就是一个属性; SparkEnv.createExecutorEnv() env.rpcEnv.setupEndpoint() env.rpcEnv.awaitTermination() //主线程不会结束,需要等待它的结束
executor = new Executor() //在里边构建对象,跟CoarseGrainedExecutorBackend关系是很紧密的
case LaunchTask(data) => executor.launchTask() //executor启动任务
-- 1.1.1 env.rpcEnv.setupEndpoint("Executor", new CoarseGrainedExecutorBackend //把当前的Executor对象创建出来; setupEndpoint设置,它是个抽象方法=>实现类NettyRpcEnv
override def setupEndpoint(): RpcEndpointRef = {dispatcher.registerRpcEndpoint(name, endpoint)} //把当前对象进行封装成name把它绑定中一起,形成注册效果就可以实现消息对发送和接收;
registerRpcEndpoint完成注册
ApplicationMaster
master = new ApplicationMaster.run()即runDriver()->startUserApplication()--->即启动一个Driver线程(通过反射来获取类名).join()还没启动, 向Yarn注册AM--registerAM
client.register().allocateResources() 进行注册和分配,申请资源,看看哪个资源可用 allocateResources资源列表; allocateResponse.getAllocatedContainers() //以container的形式把资源给你
分配可用资源--handleAllocatedContainers--runAllocatedContainers() //运行已经分配好的容器
if(launchContainers)--> launcherPool.execute(线程)->.run(ExecutorRunnable.run()),nmClient(即与nodeManager的关联)
nmClient.init(conf) nmClient.start() nmClient.startContainer(container.get, ctx) //由NM(AM就在这里边)来启动这个容器
CoarseGrainedExecutorBackend
所谓的Executor是后台CoarseGrainedExecutorBackend的一个计算对象,就是一个属性;
case LaunchTask(data) => new Executor().launchTask() //executor启动任务
RpcEndpointAddress NettyRpcEndpointRef new EndpointData() //往终端里传数据 --> val inbox = new Inbox(ref, endpoint)//收件箱 -->inbox.synchronized {messages.add(OnStart)} //往消息里发送数据,给当前终端CoarseGrainedExecutorBackend发送OnStart消息 当前终端是可以通信的;ThreadSafeRpcEndpoint extends RpcEndpoint; RpcEndpoint终端是有生命周期的: The life-cycle of an endpoint is: constructor构造方法 -> onStart启动 -> receive* -> onStop关闭 CoarseGrainedExecutorBackend接收到消息就会去调用OnStart
-->rpcEnv.asyncSetupEndpointRefByURI(driverUrl).flatMap 通过URI异步的去安装引用,通过一个地址得到远程对象对引用 通过driverUrl地址建立了两个executor之间的通信,而且是异步发送; "Connecting to driver: " + driverUrl 找到Driver所在进程(AM),异步的这个操作等同于拿到了与ApplicationMaster的关系; driver = Some(ref) 起完driver ref.ask[Boolean](RegisterExecutor()) 发送RegisterExecutor请求,它会去反向注册 driver应该接收消息,它是一个线程不能接收,通过以下方法: SparkContext 中SchedulerBackend属性 它的实现类CoarseGrainedSchedulerBackend(driver这边的引用),而CoarseGrainedExecutorBackend是executor的后台引用; 它们之间通信,刚刚ref发送了消息,它就接收到--->case RegisterExecutor 在PartialFunction偏函数中(所有的模式匹配的case都是); 反向注册就是建立executor和driver之间的关系; if (executorDataMap.contains(executorId)) { executorRef.send(RegisterExecutorFailed("Duplicate executor ID: " + executorId)) //如果executorDataMap的数据集合中包含executorId,它向executor的引用发送注册失败的消息;else就启动 context.reply(true) executorRef.send(RegisteredExecutor)//向远程的executor引用发送消息说在driver中已经注册好了可以启动了; }
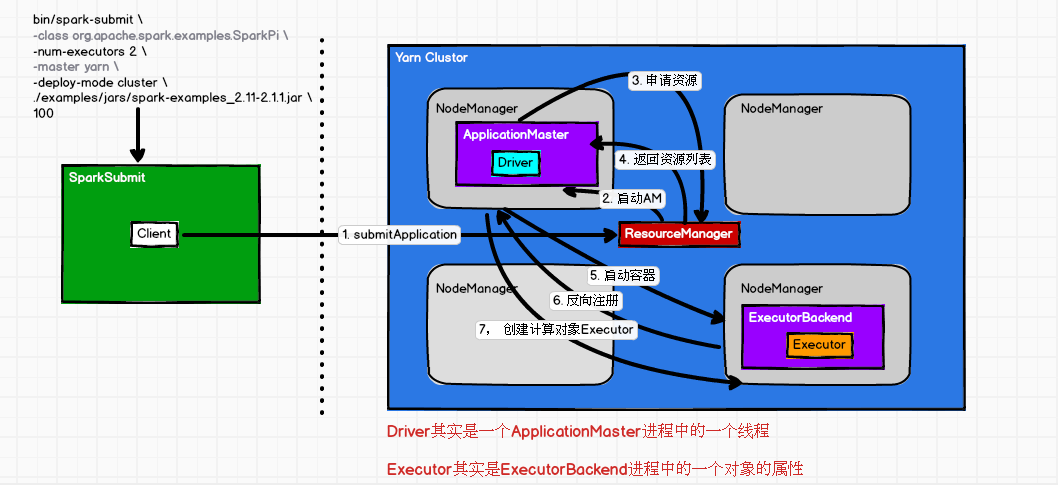
①脚本启动,执行SparkSubmit里面的main方法;
②反射获取Client类里边的main方法;
③封装并发送指令:bin/java ApplicationMaster
④选择一台NM机器启动AM
执行spark-submit实际上执行的是$SPARK_HOME/spark-class -->执行一个java类 java org.apache.spark.launcher.Main调它的main方法(它就是检查参数、构建CommandBuiler指令)--->最终真正要执行 这个类 org.apache.spark.deploy.SparkSubmit xxx是命令行参数,它就会启动一个叫SparkSubmit进程
SparkSubmit类,对命令行参数进行了封装,准备提交环境,不是集群模式它会拿到指令中的--class所传的类, if (isYarnCluster)-->> org.apache.spark.deploy.yarn.Client
利用反射通过类名获取类的信息,利用反射通过类信息获取Main方法,调用Client的main方法: Client的调用只是一个普通方法的调用
根据yarn的配置进行初始化创建yarn客户端准备去跟yarn打交道(要有yarn的server集群), yarnClient.start()启动客户端,获取一个appId,yarn的全局id,根据id可以查询它的所有信息;
Client向yarn的RM提交应用, 集群模式通过submitApplication来完成,启动JAVA_HOME/bin/java org.apache.spark.deploy.yarn.ApplicationMaster这个进程类(主要是为了与Yarn做关联)
这些commands上边封装好的指令|类都提交给yarn,由yarn来执行,这时Client客户端就结束了;
RM找一个节点NM来启动ApplicationMaster--java command;虽然只是不是集群模式它的类是ExecutorLauncher,但底层它同样还是调用的是ApplicationMaster.main;
集群模式 集群模式它运行的是Driver,启动用户应用 就是--class提交的类(通过类加载器);
new Thread("Driver").start() Driver只是ApplicationMaster进程中的一个线程起名叫Driver; 之后它运行的是--class.invoke(main)就是你写的那个有sparkContext的main方法的那个类
称为Driver类; 向Yarn的RM注册AM,并申请资源;RM会返回一个资源列表,去进行分配资源,资源是以container的方式;
分配可用资源 (移动数据不如移动计算(计算在Driver,数据在某个节点executor,driver来分配任务task发给哪个节点),本地化级别);
AM建立与NM的关联,向指定的资源NM发送指令; NM就会启动,它启动它的container容器;
//启动一个进程 JAVA_HOME/bin/java org.apache.spark.executor.CoarseGrainedExecutorBackend //执行器的后台,数据对接收处理,在NM中执行,粗粒度的执行器后台
;所谓的Executor是后台CoarseGrainedExecutorBackend的一个计算对象,就是一个属性;
反向注册就是建立executor和driver之间的关系,告诉driver我有一个executor已经启动了;
向远程的executor引用发送消息说在driver中已经注册好了可以启动了;
RDD中的数据变成一个个分区的数据,一个个分区变成任务
RDD(对数据计算逻辑的 抽象,里边没有数据)提交
任务的划分、分配、执行
RDD -- 1. collect -- 1.1 SparkContext.runJob -- dagScheduler.runJob() //有向无环图,有放向不能形成一个环,血缘关系形成的一个有向无环图调度器; -- submitJob() -- eventProcessLoop.post( JobSubmitted()) //它等同往里边放了一个样例类;发送消息JobSubmitted -- dagScheduler.handleJobSubmitted() //接收到JobSubmitted消息 DAGScheduler -- 1. handleJobSubmitted // 划分阶段-Stage -- 1.1 createResultStage //finalStage = createResultStage(finalRDD, func, partitions, jobId, callSite) val job = new ActiveJob()构建job对象即一个作业;有多个行动算子即执行了多个作业; // 提交阶段,有多少个阶段State val missing = getMissingParentStages(stage).sortBy(_.id) 这个阶段有没有上级即上一饿阶段Stage呢 -- 1.2 submitStage // 提交任务 ,如果有上一个阶段就提交上个阶段,如果还有上个阶段就继续提交上个阶段,如果没有就提交现阶段中的任务 -- 1.2.1 submitMissingTasks提交任务,missing表没有上级了 //if (missing.isEmpty) 如果上一个阶段为空没有,则submitMissingTasks提交task //如果有阶段就把上一个阶段给提交了 submitStage(parent) // 将任务进行封装,进行调度 stage 模式匹配 ShuffleMapStage | ResultStage ,spark中只有两种模式匹配; val tasks: Seq[Task[_]] 构建任务集合{对stage进行操作} 如果上ShuffleMapStage会计算分区partitionsToCompute.map <=>new ShuffleMapTask多少个分区变成多少个任务 -- 1.2.2 taskScheduler.submitTasks(TaskSet)//任务调度器提交任务<--if (tasks.size > 0), 把任务封装成一个TaskSet集合传进来 submitTasks的实现类TaskSchedulerImpl; backend.reviveOffers() reviveOffers的实现类CoarseGrainedSchedulerBackend ->reviveOffers->makeOffers()-->launchTasks(scheduler.resourceOffers(workOffers)) // 启动任务 -- 1.2.3 launchTasks //拿到了一个个任务; val serializedTask = ser.serialize(task)序列化 executorData.executorEndpoint.send(LaunchTask(new SerializableBuffer(serializedTask)))从executor中取出一个终端,从当前后台去找的executor的后台 发送一个LaunchTask启动任务的消息 CoarseGrainedExecutorBackend -- LaunchTask //receive接收到一个消息LaunchTask,表让executor执行这个任务 val taskDesc = ser.deserialize[TaskDescription](data.value)反序列化 -- executor.launchTask() //拿到任务,executor再去启动 --> val tr = new TaskRunner(context, taskId = taskId, attemptNumber = attemptNumber, taskName,serializedTask) // 运行任务 threadPool.execute(tr) //线程池在执行某个线程操作即TaskRunner extends Runnable -->run -- task.run //释放内存更新状态等;
DAGScheduler
划分阶段 finalStage = createResultStage(finalRDD..);
ShuffleMapStage | ResultStage ,spark中只有两种模式匹配;
taskScheduler.submitTasks(TaskSet)//任务调度器提交任务<--if (tasks.size > 0), 把任务封装成一个TaskSet集合传进来;
Spark通信架构
RPC通信:远程过程(服务)调用-(两个进程之间的通信)
RPC的实现有多种,其中有RMI,原理:
一个Process1中的client去调用它的service,要让Process2中的service去执行;通过socket,两个进程的service一定是个接口,那么client怎么去调用接口呢
通过动态代理(把接口代理为对象来使用),client通过代理对象Proxy与service去关联,代理对象会完成两个进程中socket的交互;
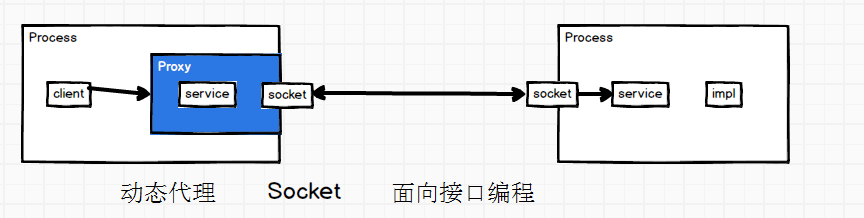
有封装好的框架可以使用;
Spark2.x版本使用Netty通讯框架作为内部通讯组件。spark 基于netty新的rpc框架借鉴了Akka的中的设计(随着版本升级已不再使用Akka,用Netty),它是基于Actor模型;
Actor模型
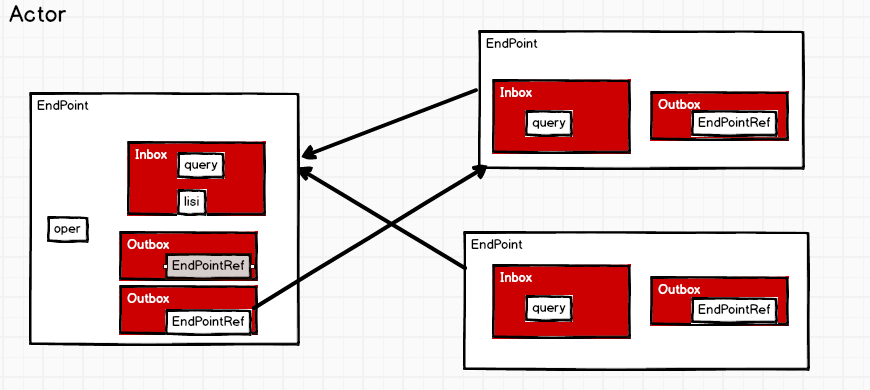
Actor模型: 有多个对象,Object1, Object2 、Object3都给Object1发消息,都可以发消息(异步操作,发完该干嘛干嘛去;同步是发完之后不能做别的要等待它的返回),但消息的先后由自己决定 接收消息的一方Object1有个收件箱Inbox(消息不是马上执行的),它会去周期性的去取即轮询操作,有就去处理; Object1从Inbox中查询到消息,发件箱Outbox(对应每一个对象),可以有多个发件箱可以同时发送 Outbox(Object2) ---> Object2中相应的要有收件箱Inbox(query),则Object1中要有Object2中地址的引用; Actor模型中不叫Object了改叫EndPoint,Outbox(Object2)中的Object2引用改叫EndPointRef Ref即远程的引用,要有地址去连接RpcAddress,终端和终端的引用互相发生关联;
Endpoint(Client/Master/Worker)有1个InBox和N个OutBox,每一个引用就是一个OutBox,多个OutBox可以同时发送消息
Netty
NETT底层还是socket
IO中三种不同的处理方式:
BIO(最慢,阻塞式IO,读取文件时要等着不能去做别的事),
NIO(非阻塞式IO), 性能高,拿一个线程不断的去轮询,还可以去做其他事(只是在做事的过程中要不断的去问下好了没); 也叫多路IO复用,redis linux中
AIO(异步非阻塞式IO),读取文件时遇到阻塞可以去做别的事,没有阻塞了它会把文件直接发送给你,不需你不断的去轮询的去问
Netty就是基于AIO的 ;但是linux中不能用,windows可以
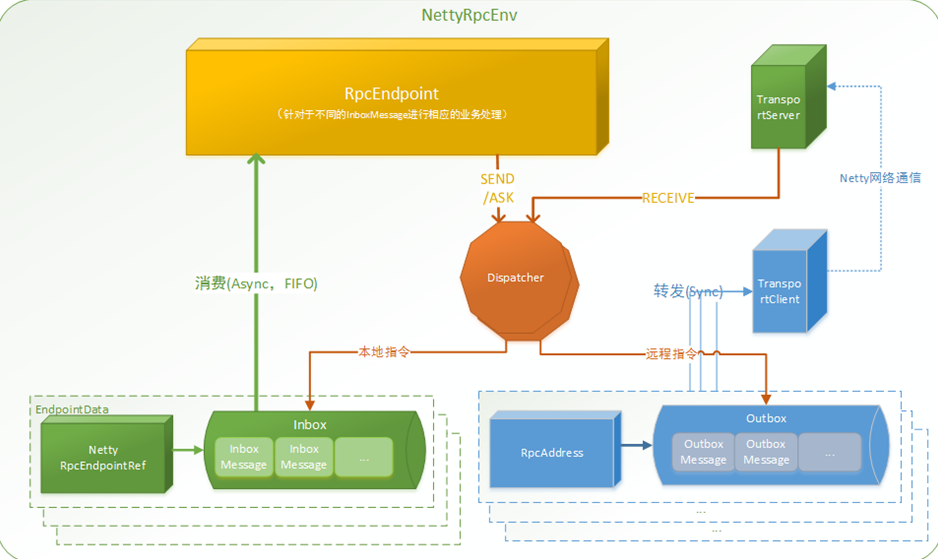
NettyRpcEnv是整个通信的环境,RpcEndpoint 终端,可以send和ask消息,还可以receive接收消息,请求和接收消息都要走Dispatcher调度器,它来决定你发送的消息该往收件箱还是发件箱走;在收件箱按照队列方式排列好,周期性的去取FIFO(先进先出),消息处理完之后发往send另外一个RpcEndPoint,往发件箱OubBox里走(会有一个远程地址RpcEndpointAddress-->该给谁发消息);发消息时会有一个TransportClient,往远程去发(通过Netty网络通信去发);
远程TransportServer接收消息又回到了Inbox,处理再返回; ===>整个过程形成8字环绕
Spark任务调度
RDD是对数据计算逻辑的抽象;真正执行(行动算子)的时候才会计算;
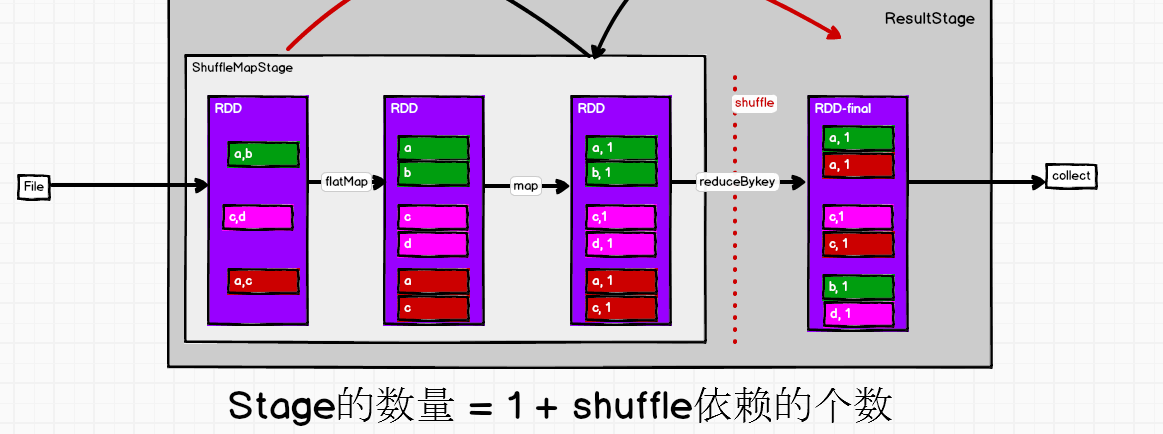
在DAGScheduler的handleJobSubmitted这个方法中完成了阶段的划分 finalStage = createResultStage(finalRDD, func, partitions, jobId, callSite) --->val stage = new ResultStage(id, rdd, func, partitions, parents, jobId, callSite) //结果阶段,作业执行一遍这个对象也是就创建一遍 把当前作业当作整体形成完整的阶段--称作ResultStage val parents = getOrCreateParentStages(rdd, jobId) //参数rdd是handleJobSubmitted(finalRDD,xxx)给的,即当前要执行行动算子的rdd叫做finalRDD private def getOrCreateParentStages(rdd: RDD[_], firstJobId: Int): List[Stage] = { getShuffleDependencies(rdd).map { shuffleDep => //把rdd传进去获取shuffle的依赖关系,.map把得到的结果进行转换;getShuffleDependencies返回的结果是parents val parents = new HashSet[ShuffleDependency[_, _, _]] case shuffleDep: ShuffleDependency[_, _, _] => parents += shuffleDep 先压栈new Stack[RDD[_]].push(rdd),循环如果不为空就弹出来.pop() 判断依赖关系中有没有shuffle依赖,有就加上 parents += shuffleDep case dependency => waitingForVisit.push(dependency.rdd)//没有shuffle就把上一层的rdd取出来,再做循环,push、pop不断的取上一级做判断 getOrCreateShuffleMapStage(shuffleDep, firstJobId) //它又new ShuffleMapStage() }.toList } ShuffleMapStage和ResultStage两个阶段,最后构建job、设定、提交submitJob
spark任务的划分、分配和执行
RDD读取file数据(按一行一行的读取),放到3个分区;发现0号分区不是想要的比如统计wordcount,分解产生了一个新的rdd(所有的转换算子等同于产生了一个新的rdd,rdd是不可变数据集),把一行一行数据变成一个个的,flatMap;转换结构如(a, 1)这样的结构map;reduceBykey打乱重组,产生shuffle过程
有向无环图的调度器,运行并且提交job作业(会进行简单的判断,jobWaiter传到样例类一旦发生特殊事件就产生特殊的方法 handlerJobSubmit完成了整个过程的阶段划分resultStage); 把当前作业当成一个整体,形成了一个完整的阶段称为resultStage;
阶段怎么划分成一个个任务的了?
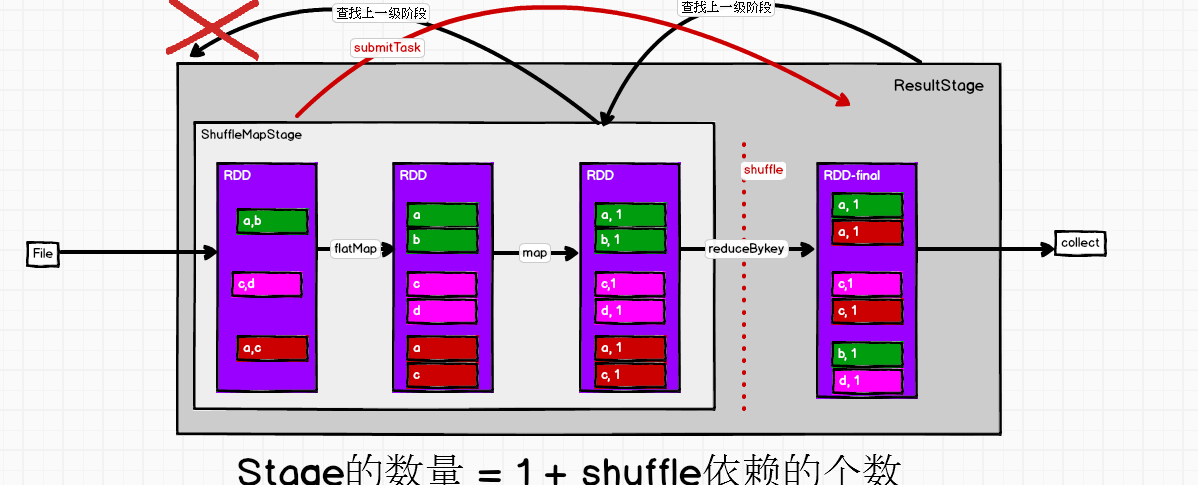
map->new MapPartitionsRDD -->extends RDD[U](prev)-->def this(@transient oneParent: RDD[_]) =this(oneParent.context, List(new OneToOneDependency(oneParent))) OneToOneDependency[T](rdd: RDD[T]) extends NarrowDependency[T](rdd) ,源码中只有窄依赖,不是窄的就是宽的呗就是有shuffle的 创建了两个Stage,给的是finalStage, 创建job,提交submitStage(finalStage) val missing = getMissingParentStages(stage).sortBy(_.id) //看看有没有上一级的阶段即查找ShuffleMapStage new HashSet[Stage].push(stage.rdd) 把当前的rdd传到栈里-压栈,---不为空-->弹栈.pop() -->visit() rdd.dependencies取出它的依赖关系,找到shuffle的依赖关系,val mapStage = getOrCreateShuffleMapStage(shufDep, stage.firstJobId)有就拿来没有就创建新的 missing += mapStage //放到hashSet里 missing.toList missing不为空 --> for (parent <- missing) {submitStage(parent)}循环遍历提交每一个Stage 准备提交ResultStage时把它ShuffleMapStage取出来; submitStage(parent)}又自己调自己,找它ShuffleMapStage的上一级,为空-->submitMissingTasks(stage, jobId.get)提交任务 提交的是shuffleStage,找的时候是一层层往上找,提交时是从最开始那一层层往下submitWaitingChildStages(stage) 提交任务: 只有两种类型的Stage case s: ShuffleMapStage => case s: ResultStage => taskIdToLocations,最优位置决定计算在哪里算,task和位置进行关联来决定在哪个executor中执行 getPreferredLocs(stage.rdd, p) case stage: ShuffleMapStage => partitionsToCompute.map计算分区 locs part ShuffleMapTask //一个阶段中多个分区map转换一个分区形成一个任务 case stage: ResultStage => p locs part ResultTask 用shuffle来划分stage,因为shuffle是要落盘的;flatmap、map处理数据中间不停留,直接处理往下走,RDD之间每个分区的数据都是连贯的,但是 在shuffle阶段它就不连贯了,在这个阶段它要等待所有的数据都处理完了,shuffle是要全落盘的;这也是划分阶段的原因; 任务跟阶段有关系,有多少个分区就有多少个任务 taskScheduler.submitTasks(new TaskSet()) //任务的调度器它来提交任务,封装成任务集 val manager = createTaskSetManager(taskSet, maxTaskFailures)//任务集管理器 schedulableBuilder.addTaskSetManager(manager, manager.taskSet.properties) //manager会放到任务池中 --->FIFOSchedulableBuilder 可以往里边放任务addTaskSetManager{ rootPool.addSchedulable(manager)} //任务池,TaskPool把任务划分好了来不及执行,可能划分好任务时资源还没申请到, backend.reviveOffers() --> launchTasks(scheduler.resourceOffers(workOffers))查找任务集 resourceOffers 看看有没有可用的资源executor, 拿到之后 launchTasks()[TaskDescription] ser.serialize(task)把任务序列化,executorData,executorData.executorEndpoint.send(LaunchTask(new SerializableBuffer(serializedTask))) 找到executor向它的终端发送消息--启动task,把得到的任务发送过去; 反向注册目的是启动一个Executor之后告诉Driver我准备好了-->可以发任务了; 启动: case LaunchTask(data) => if (executor == null) -->val taskDesc = ser.deserialize[TaskDescription](data.value)反序列化得到任务对象 executor.launchTask() -->run() task.run() //只有两种task 以ResultTask为例: runTask(),shuffle前把数据写到文件里-->rdd.iterator读取数据func(context, rdd.iterator(partition, context)) -->ShuffleRDD中 compute .getReader .read() 读取的是shuffle之前往里写的数据 -->ShuffleMapTask阶段的最后一个RDD runTask() .getWriter 由它来写
taskScheduler.submitTasks(new TaskSet()) //任务的调度器来提交任务,把任务封装成一个TaskSet任务集
val manager = createTaskSetManager(taskSet..)//任务集管理器
schedulableBuilder.addTaskSetManager(manager, manager.taskSet.properties) //manager会放到任务池中
-->FIFOSchedulableBuilder 可以往里边放任务addTaskSetManager{ rootPool.addSchedulable(manager)} //任务池
backend.reviveOffers(), launchTasks(scheduler.resourceOffers(workOffers))查找任务集, 拿到之后launchTasks(), ser.serialize(task)把任务序列化
特质SchedulerBackend--实现类--> CoarseGrainedSchedulerBackend它是(driver这边的引用);