1. Spark概述
一种基于内存的快速、通用、可扩展的大数据分析引擎;
内置模块:
Spark Core(封装了rdd、任务调度、内存管理、错误恢复、与存储系统交互);
Spark SQL(处理结构化数据)、
Spark Streaming(对实时数据进行流式计算) 、
Spark Mlib(机器学习程序库包括分类、回归、聚合、协同过滤等)、
Spark GraghX(图计算);
独立调度器、Yarn、Mesos
特点:
快( 基于内存(而MR是基于磁盘)、多线程模型(而mapReduce是基于多进程的,每个MR都是独立的JVM进程)、可进行迭代计算(而hadoop需要多个mr串行) )、
易用(支持java、scala、python等的API,支持超过80多种算法,支持交互式的 Python 和 Scala 的 shell,可方便地在shell中使用spark集群来验证解决问题,而不像以前需要打包上传验证)、
通用(spark提供了统一解决方案,可用于批处理、交互式查询(spark sql) 实时流式处理(spark streaming)机器学习和图计算,可在同一应用中无缝使用)
兼容性(与其他开源产品的融合,如hadoop的yarn、Mesos、HDFS、Hbase等);
http://spark.apache.org/ 文档查看地址 https://spark.apache.org/docs/2.1.1/
集群角色
Master和Workers
1)Master
Spark特有资源调度系统的Leader。掌管着整个集群的资源信息,类似于Yarn框架中的ResourceManager,主要功能:
(1)监听Worker,看Worker是否正常工作;
(2)Master对Worker、Application等的管理(接收worker的注册并管理所有的worker,接收client提交的application,(FIFO)调度等待的application并向worker提交)。
2)Worker
Spark特有资源调度系统的Slave,有多个。每个Slave掌管着所在节点的资源信息,类似于Yarn框架中的NodeManager,主要功能:
(1)通过RegisterWorker注册到Master;
(2)定时发送心跳给Master;
(3)根据master发送的application配置进程环境,并启动StandaloneExecutorBackend(执行Task所需的临时进程)
Driver和Executor
1)Driver(驱动器)
Spark的驱动器是执行开发程序中的main方法的进程。它负责开发人员编写的用来创建SparkContext、创建RDD,以及进行RDD的转化操作和行动操作代码的执行。如果你是用spark shell,那么当你启动Spark shell的时候,系统后台自启了一个Spark驱动器程序,就是在Spark shell中预加载的一个叫作 sc的SparkContext对象。如果驱动器程序终止,那么Spark应用也就结束了。主要负责:
(1)把用户程序转为任务
(2)跟踪Executor的运行状况
(3)为执行器节点调度任务
(4)UI展示应用运行状况
2)Executor(执行器)
Spark Executor是一个工作进程,负责在 Spark 作业中运行任务,任务间相互独立。Spark 应用启动时,Executor节点被同时启动,并且始终伴随着整个 Spark 应用的生命周期而存在。如果有Executor节点发生了故障或崩溃,Spark 应用也可以继续执行,会将出错节点上的任务调度到其他Executor节点上继续运行。主要负责:
(1)负责运行组成 Spark 应用的任务,并将状态信息返回给驱动器进程;
(2)通过自身的块管理器(Block Manager)为用户程序中要求缓存的RDD提供内存式存储。RDD是直接缓存在Executor进程内的,因此任务可以在运行时充分利用缓存数据加速运算。
总结:Master和Worker是Spark的守护进程,即Spark在特定模式下正常运行所必须的进程。Driver和Executor是临时进程,当有具体任务提交到Spark集群才会开启的进程。
1. Local模式-本地单机
Linux中查看有多少核数: [kris@hadoop101 ~]$ cat /proc/cpuinfo ... [kris@hadoop101 ~]$ cat /proc/cpuinfo | grep 'processor' | wc -l 8
Local模式
在一台计算机,可以设置Master; (提交任务时需要指定--master)Local模式又分为:
① Local所有计算都运行在一个线程中(单节点单线程),没有任何并行计算;
②Local[K] ,如local[4]即运行4个Worker线程(单机也可以并行有多个线程),可指定几个线程来运行计算,通常CPU有几个Core就执行几个线程,最大化利用cpu的计算能力;
③Local[*], 直接帮你安装Cpu最多Cores来设置线程数,这种是默认的;
bin/spark-submit //提供任务的命令 --class org.apache.spark.examples.SparkPi //指定运行jar的主类 --master //它有默认值是local[*] =>spark://host:port, mesos://host:port, yarn, or local. --executor-memory 1G //指定每个executor可用内存 --total-executor-cores 2 指定executor总核数 ./examples/jars/spark-examples_2.11-2.1.1.jar \jar包 100 //main方法中的args参数 ./bin/spark-submit 回车可查看所有的参数
[kris@hadoop101 spark-local]$ bin/spark-shell Spark context Web UI available at http://192.168.1.101:4040 Spark context available as 'sc' (master = local[*], app id = local-1554255531204). ##spark core的入口sc Spark session available as 'spark'. ##它是spark sql程序的入口 再起一个spark-shell会报错: spark sql也有一个默认的元数据也是存在derby数据库里边 Failed to start database 'metastore_db' with class loader org.apache.spark.sql.hive.client.IsolatedClientLoader$$anon$1@63e5b8aa, see the next exception for details. Caused by: org.apache.derby.iapi.error.StandardException: Another instance of Derby may have already booted the datab 查看页面:hadoop101:4040 scala> sc.textFile("./wc.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect res0: Array[(String, Int)] = Array((Hello,3), (smile,1), (java,2), (world,1), (kris,1)) 提交任务(或者开启spark-shell)的时候会有driver和executor进程,Local模式下它被封装到了SparkSubmit中
提交任务分析

driver和executor是干活的;
① Client提交任务--->②起一个Driver ---> ③注册应用程序,申请资源--资源管理者有 (Master(Standalone模式)、ResourceManage(yarn模式))----->④拿到资源后去其他节点启动Executor----> ⑤Executor会反向注册给Driver汇报;
⑥(把提交的jar包做任务切分,把任务发给具体执行的节点Executor)--->Driver会进行初始化sc、任务划分、任务调度 <===>Executor具体执行任务(负责具体执行任务、textFile、flatMap、map...)
⑦ Driver把任务发到Executor不一定会执行,有可能资源cpu或内存不够了或者executor挂了,spark会有一个容错机制,某一个挂了可转移到其他的Executor;
最后任务跑完了,Driver会向资源管理者申请注销(Executor也会注销)
数据流程
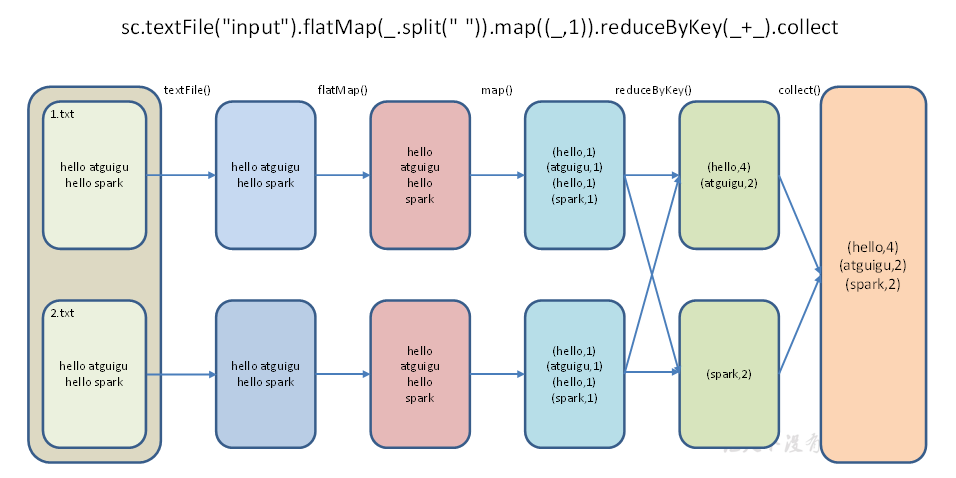
textFile("input"):读取本地文件input文件夹数据;
flatMap(_.split(" ")):压平操作,按照空格分割符将一行数据映射成一个个单词;
map((_,1)):对每一个元素操作,将单词映射为元组;
reduceByKey(_+_):按照key将值进行聚合,相加;
collect:将数据收集到Driver端展示。
2. Standalone模式--完全分布式
概述
构建一个由Master+Slave构成的Spark集群,Spark运行在集群中;它的调度器是其实就是Master
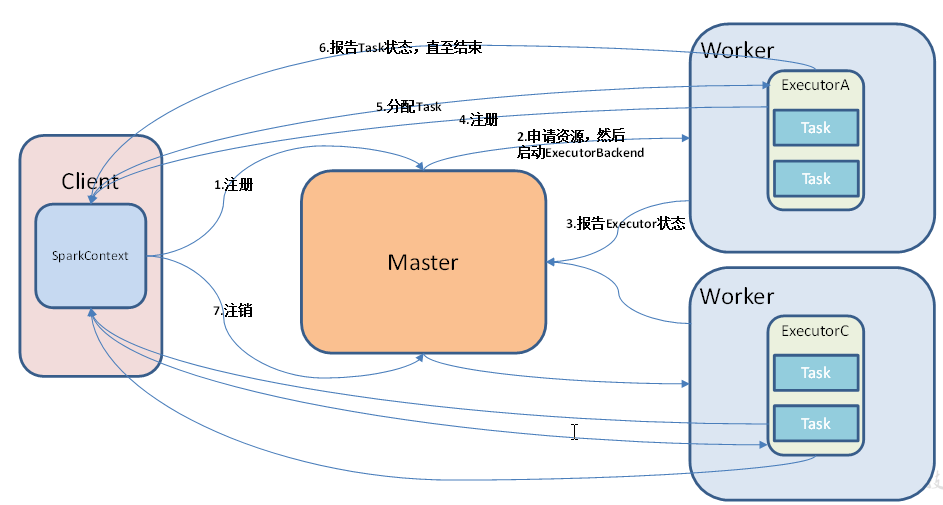
提交任务时需要有一个客户端Client,Master和Worker是守护进程它们是资源管理系统,提交任务(运行spark-shell或者spark-submit)之前它们就已经启动了;
①提交--->起Driver就是初始化SparkContext,然后启动Executor时需要资源;②向Master申请资源(即注册),启动ExecutorBackend
启动Executor---->反向注册给Driver汇报信息;
③ Driver划分切分任务把Task发送给Executor,如果Executor会有一个容错机制,Executor运行时会给Driver发送报告Task运行状态直至结束;
④最后任务运行完之后driver向master申请注销,Executor也会注销掉;
不一定非要在Client中起Driver(SparkContext),cluster模式,具体在哪个节点起sc由Master决定,随机的在worker节点上选择一个一个;
Driver在哪个节点起的原因:driver和executor之间是有通讯,每个 executor都要向driver汇报信息,互相通讯(消耗内存、资源+cpu数); 所有的executor节点都去跟driver做通讯,客户端的压力就会特别大;
Client是本地调试用,输入之后马上能看到输入的结果;
1)修改slave文件,添加work节点:
[kris@hadoop101 conf]$ vim slaves
hadoop101
hadoop102
hadoop103
2)修改spark-env.sh文件,添加如下配置:
在高可用集群需把下面内容这给注释掉:
#SPARK_MASTER_HOST=hadoop101
#SPARK_MASTER_PORT=7077
[kris@hadoop101 conf]$ vim spark-env.sh export JAVA_HOME=/opt/module/jdk1.8.0_144 ##如果遇到JAVA_HOME not set异常时可配置 SPARK_MASTER_HOST=hadoop101 SPARK_MASTER_PORT=7077 #配置历史服务 export SPARK_HISTORY_OPTS="-Dspark.history.ui.port=18080 -Dspark.history.retainedApplications=30 -Dspark.history.fs.logDirectory=hdfs://hadoop101:9000/directory" #配置高可用 export SPARK_DAEMON_JAVA_OPTS=" -Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=hadoop101,hadoop102,hadoop103 -Dspark.deploy.zookeeper.dir=/spark"
3)修改spark-default.conf文件,开启Log:
[kris@hadoop101 conf]$ vi spark-defaults.conf spark.eventLog.enabled true spark.eventLog.dir hdfs://hadoop101:9000/directory
注意:HDFS上的目录需要提前存在。 hadoop fs -mkdir /directory
4) 分发spark包 分发的原因,因为这种模式下的资源调度是master和worker,各个节点需要自己去启进程;
[kris@hadoop101 module]$ xsync spark/spark-standalone
5)启动
② [kris@hadoop101 spark]$ sbin/start-all.sh
网页查看Master:hadoop101:8080
可看到Status:ALIVE;Memory in use 等信息
高可用集群的启动,要① 先启动zookeeper;
在hadoop102上(也可以是其他节点)单独启动master节点
[kris@hadoop102 spark]$ sbin/start-master.sh
启动历史服务之前要先启动 ③ start-dfs.sh
sbin/start-history-server.sh --->HistoryServer
查看历史服务hadoop101:18080
官方求PI案例
##运行之前上边的① ② ③步都要启动其他; 默认的是client模式
[kris@hadoop101 spark]$ bin/spark-submit
--class org.apache.spark.examples.SparkPi
--master spark://hadoop101:7077
--executor-memory 1G
--total-executor-cores 2
./examples/jars/spark-examples_2.11-2.1.1.jar
100
===>>
Pi is roughly 3.1417439141743913 启动spark shell /opt/module/spark/bin/spark-shell --master spark://hadoop101:7077 --executor-memory 1g --total-executor-cores 2 只要提交了任务就可以看到driver和executor,driver被封装在了SparkSubmit里边;CoarseGrainedExecutorBackend就是启动的executor 提交任务提交给哪个executor都是有可能的
执行WordCount程序 scala>sc.textFile("./wc.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect
res0: Array[(String, Int)] = Array((Hello,2), (World,1), (java,2), (sbase,1), (spark,2), (Hi,1))
[kris@hadoop101 ~]$ jpsall
-------hadoop101-------
6675 DataNode
5971 Master
6100 Worker
7463 CoarseGrainedExecutorBackend
7895 Jps
7368 SparkSubmit
6527 NameNode
5855 QuorumPeerMain
-------hadoop102-------
4647 CoarseGrainedExecutorBackend
4075 QuorumPeerMain
4875 Jps
4380 DataNode
4188 Worker
-------hadoop103-------
4432 SecondaryNameNode
4353 DataNode
4085 QuorumPeerMain
4198 Worker
4778 Jps
在Standalone--cluster模式下
[kris@hadoop101 spark-standalone]$ bin/spark-submit
--class org.apache.spark.examples.SparkPi
--master spark://hadoop101:7077
--deploy-mode cluster
--executor-memory 1G
--total-executor-cores 2
./examples/jars/spark-examples_2.11-2.1.1.jar
100
任务未执行完时的进程:
[kris@hadoop101 spark-standalone]$ jpsall
-------hadoop101-------
16740 CoarseGrainedExecutorBackend
16404 HistoryServer
16006 NameNode
15686 Master
16842 Jps
15805 Worker
16127 DataNode
-------hadoop102-------
10240 CoarseGrainedExecutorBackend
10021 DataNode
9911 Worker
10334 Jps
-------hadoop103-------
9824 DataNode
9714 Worker
9944 SecondaryNameNode
10299 Jps
10093 DriverWrapper ##cluster 模式下的Driver
任务执行完的进程:
[kris@hadoop101 spark-standalone]$ jpsall
-------hadoop101-------
16404 HistoryServer
16006 NameNode
15686 Master
15805 Worker
17166 Jps
16127 DataNode
-------hadoop102-------
10021 DataNode
9911 Worker
10447 Jps
-------hadoop103-------
10416 Jps
9824 DataNode
9714 Worker
9944 SecondaryNameNode
spark-shell的 spark HA集群访问,前提是另外一个Master启起来了;
/opt/module/spark/bin/spark-shell --master spark://hadoop101:7077,hadoop102:7077 --executor-memory 1g --total-executor-cores 2
把其中ACTIVE状态节点的kill掉,另外一个Master的状态将从standby模式--->active状态;
可验证下:
scala>sc.textFile("./wc.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect
res0: Array[(String, Int)] = Array((Hello,2), (World,1), (java,2), (sbase,1), (spark,2), (Hi,1))
提交任务时:
--deploy-mode DEPLOY_MODE Whether to launch the driver program locally ("client") or
on one of the worker machines inside the cluster ("cluster")
(Default: client).
client和cluster的区别:
SparkContext的位置不同(也就是运行Driver的位置不一样),由Master决定,随机的在其他节点初始化一个sc
Driver和Executor之间会有通信,通信需要消耗资源内存cpu等,所有的executor去和客户端(如果是client模式,Driver是启在Client上的)去通信,
客户端的压力会非常大,如果有大量的executor再加上提交多个任务就启动多个Driver,那么Client单点就挂掉被拖垮;
cluster模式,每次提交任务时的sc的位置分散在不同节点上,分担了压力,
Client本地调试时候用,可以看到输出的结果,如可看到打印的π
--deploy-mode DEPLOY_MODE Whether to launch the driver program locally ("client") or
on one of the worker machines inside the cluster ("cluster")
(Default: client).
--executor-cores NUM Number of cores per executor. (Default: 1 in YARN mode,
or all available cores on the worker in standalone mode)
bin/spark-submit
--class org.apache.spark.examples.SparkPi
--master spark://hadoop101:7077
--deploy-mode cluster
--executor-memory 1G
--total-executor-cores 2 ##总的是2,默认1个cores/executor--->推导出有2/1个executor;可控制executor的数量;
./examples/jars/spark-examples_2.11-2.1.1.jar
100
cluster模式下,driver叫DriverWrapper
3. Yarn模式
概述
之前的standalone模式,是自己Master和worker管理资源,分发是为了在各个节点启进程;yarn模式资源由RM、NM来管理
Spark客户端直接连接Yarn,不需要额外构建Spark集群。有yarn-client和yarn-cluster两种模式,主要区别在于:Driver程序的运行节点。
yarn-client:Driver程序运行在客户端,适用于交互、调试,希望立即看到app的输出;
yarn-cluster:Driver程序运行在由RM(ResourceManager)启动的AM(APPMaster)适用于生产环境。分担压力不会拖垮某个节点;
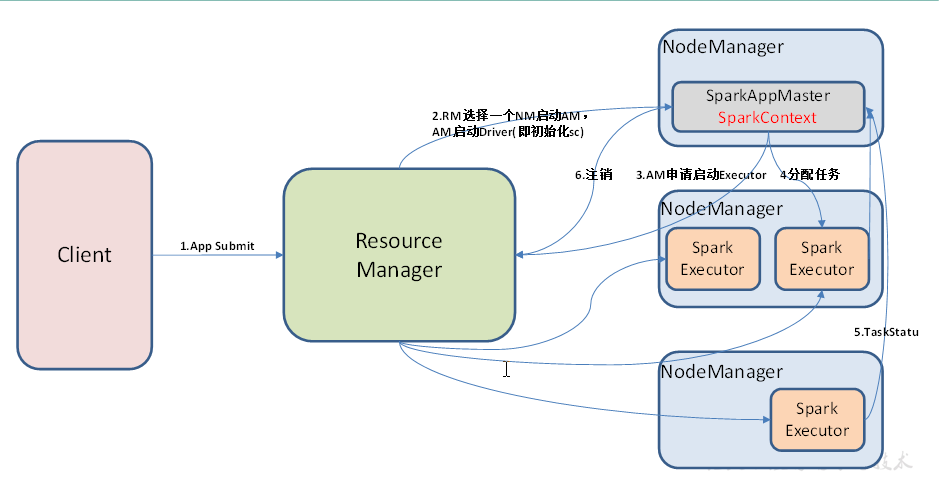
提交任务之前,客户端Client、ResourceManager、NodeManager都是要启动好的;
提交任务,App Submit; RM选择一个NM启动AM,AM来启动Driver(即初始化sc),yarn的cluster模式SparkAppMaster(用来申请资源,启动driver)和SparkContext在一个进程里边;
AM(SparkAppMaster)向RM申请启动Executor;(默认情况下一个节点启一个executor这样子负载比较均衡,也可以启两个),executor也是有个反向注册的过程;
切分分配任务,同时executor上报集群状况;跑完之后申请注销;
安装使用
1)修改hadoop配置文件yarn-site.xml,添加如下内容:
[kris@hadoop101 hadoop]$ vim yarn-site.xml
<!--是否启动一个线程检查每个任务正使用的物理内存量,如果任务超出分配值,则直接将其杀掉,默认是true -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!--是否启动一个线程检查每个任务正使用的虚拟内存量,如果任务超出分配值,则直接将其杀掉,默认是true -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
2)配置历史服务JobHistoryServer| 配置日志查看功能
修改spark-env.sh,添加如下配置:
[kris@hadoop101 conf]$ vim spark-env.sh
export JAVA_HOME=/opt/module/jdk1.8.0_144 YARN_CONF_DIR=/opt/module/hadoop-2.7.2/etc/hadoop # 配置JobHistoryServer 注意:HDFS上的目录需要提前存在。 export SPARK_HISTORY_OPTS="-Dspark.history.ui.port=18080 -Dspark.history.retainedApplications=30 -Dspark.history.fs.logDirectory=hdfs://hadoop101:9000/directory"
从这里看到历史日志:http://hadoop102:8088/cluster点击直接跳转到spark中 http://hadoop101:18080/history/application_1554294467331_0001/jobs/
[kris@hadoop101 conf]$ vim spark-defaults.conf
#修改spark-default.conf文件,开启Log: spark.eventLog.enabled true spark.eventLog.dir hdfs://hadoop101:9000/directory # 日志查看 spark.yarn.historyServer.address=hadoop101:18080 spark.history.ui.port=18080
提交任务到Yarn执行 [kris@hadoop101 spark-yarn]$ bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode client ./examples/jars/spark-examples_2.11-2.1.1.jar 100
[kris@hadoop101 spark-yarn]$ bin/spark-shell --master yarn ##shell只能用client模式启动,默认的也是这种模式;
Spark context Web UI available at http://192.168.1.101:4040
Spark context available as 'sc' (master = yarn, app id = application_1554290192113_0004).
Spark session available as 'spark'.
-------hadoop101-------
25920 NodeManager
25751 DataNode
28075 SparkSubmit ##Driver还是被封装到这里边的
28252 Jps
25469 QuorumPeerMain
25630 NameNode
-------hadoop102-------
14995 CoarseGrainedExecutorBackend
15076 Jps
13447 DataNode
13672 NodeManager
13369 QuorumPeerMain
13549 ResourceManager
14942 ExecutorLauncher #Executor启动器,就是AppMaster,Cluster模式,AM和sc在一个进程里边的,这种模式AM的任务是:既可以申请资源又可以做任务切分和调度;
Client模式它们就不在一个进程了,由RM随机选择一个节点来启动AM,这种模式它的作用仅仅是用来申请资源去启动Executor;
-------hadoop103-------
13536 DataNode
14610 CoarseGrainedExecutorBackend
14691 Jps
13638 NodeManager
13464 QuorumPeerMain
13710 SecondaryNameNode
yarn--cluster模式
[kris@hadoop101 spark-yarn]$ bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode cluster ./examples/jars/spark-examples_2.11-2.1.1.jar
在任务未完成之前的进程:
[kris@hadoop101 spark-yarn]$ jpsall
-------hadoop101-------
13328 SparkSubmit
12146 NodeManager
13706 CoarseGrainedExecutorBackend
12555 NameNode
12702 DataNode
13951 Jps
-------hadoop102-------
6864 ResourceManager
8101 Jps
7403 DataNode
6990 NodeManager
-------hadoop103-------
7984 ApplicationMaster ## Yarn-Cluster模式下SparkAppMaster和Sparkcontext即Driver是在一个进程的
8432 Jps
7560 SecondaryNameNode
8158 CoarseGrainedExecutorBackend
7230 NodeManager
7438 DataNode
任务完成之后的进程:
[kris@hadoop101 spark-yarn]$ jpsall
-------hadoop101-------
12146 NodeManager
12555 NameNode
12702 DataNode
14031 Jps
-------hadoop102-------
6864 ResourceManager
8153 Jps
7403 DataNode
6990 NodeManager
-------hadoop103-------
7560 SecondaryNameNode
8537 Jps
7230 NodeManager
7438 DataNode
[kris@hadoop101 spark-yarn]$ sbin/start-history-server.sh ##开启历史服务
提交任务到Yarn执行 [kris@hadoop101 spark-yarn]$ bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode client ./examples/jars/spark-examples_2.11-2.1.1.jar 100


Mesos模式
Spark客户端直接连接Mesos;不需要额外构建Spark集群。国内应用比较少,更多的是运用yarn调度。
几种模式对比

package com.atguigu.spark import org.apache.spark.{SparkConf, SparkContext} object WordCount { def main(args: Array[String]): Unit = { //1.创建SparkConf并设置App名称 val conf = new SparkConf().setAppName("WordCount") //2.创建SparkContext,该对象是提交Spark App的入口 val context = new SparkContext(conf) //3.使用sc创建RDD并执行相应的transformation和action context.textFile(args(0)).flatMap(_.split(" ")).map((_, 1)).reduceByKey(_+_, 1).sortBy(_._2, false).saveAsTextFile(args(1)) //4.关闭连接 context.stop() } }
/wc.txt必须在HDFS上有这个文件
[kris@hadoop101 spark-yarn]$ hadoop fs -put wc.txt / [kris@hadoop101 spark-yarn]$ bin/spark-submit --class com.atguigu.spark.WordCount --master yarn --deploy-mode client /opt/module/spark/spark-yarn/WordCount.jar /wc.txt /out 结果: (Hello,3) (smile,2) (kris,2) (alex,1) (hi,1)