【调试背景】
目前测试kafka集群有两套,版本为 0.10.x。有一套是添加了Kerberos+Sentry认证,另一套没有添加。
现在需要通过sparkStreaming接入kafka做实时分析。
【总体结论】
实验1:1.6.x版本spark的jar包,0.8.x.x的spark-streaming-kafka,无Kerberos+Sentry认证,用createStream,可以从zk中获取broker,接入成功;
实验2:1.6.x版本spark的jar包,0.8.x.x的spark-streaming-kafka,有Kerberos+Sentry认证,用createStream,无法zk中获取broker,接入失败,报空指针;
实验3:1.6.x版本spark的jar包,0.8.x.x的spark-streaming-kafka,有Kerberos+Sentry认证,用createDirectStream,直接设置broker,接入失败,报EOFException;
实验4:2.1.x版本spark的jar包,010版本的spark-streaming-kafka,有Kerberos+Sentry认证,用createDirectStream,直接设置broker,需要修改“KafkaUtils”源码,接入成功;
PS :2.1.x版本spark的jar包,010版本的spark-streaming-kafka,无Kerberos+Sentry认证,用createDirectStream,直接设置broker,接入成功;
PS :2.1.x版本spark的jar包,010版本的spark-streaming-kafka,无Kerberos+Sentry认证,用createDirectStream,直接设置broker,接入成功;
【实验1】可以正常运行
(1)kafka环境:无Kerberos+Sentry认证
(2)使用jar包:
(3)核心代码:
package com.xx.kafka;
import java.util.HashMap;
import java.util.Map;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.streaming.Duration;
import org.apache.spark.streaming.api.java.JavaDStream;
import org.apache.spark.streaming.api.java.JavaPairReceiverInputDStream;
import org.apache.spark.streaming.api.java.JavaStreamingContext;
import org.apache.spark.streaming.kafka.KafkaUtils;
import scala.Tuple2;
public class PrintRecMsg {
public static void main(String[] args) {
Map<String, Integer> topicmap = new HashMap<>();
topicmap.put(args[0], 2);
SparkConf sparkConf = new SparkConf().setAppName("PrintRecMsg").setMaster("local[2]");
final JavaStreamingContext jssc = new JavaStreamingContext(sparkConf, new Duration(10000));
String zkQuorum ="host1:2181,host2:2181,host3:2181";
String group = "mygroup";
JavaPairReceiverInputDStream<String, String> lines = KafkaUtils.createStream(jssc, zkQuorum, group, topicmap);
JavaDStream<String> msg = lines.map(new Function<Tuple2<String,String>, String>() {
@Override
public String call(Tuple2<String, String> tuple2) throws Exception {
return tuple2._1() + "," + tuple2._2();
}
});
msg.print(20);
jssc.start();
jssc.awaitTermination();
}
}
(4)分析:
创建的流只需要三个和Kafka有关的参数:zk集群地址,消费者组,topicMap。
createStream是走的Zookeeper去获取对应集群broker信息,然后进行消费。
【实验2】无法运行
(1)kafka环境:kafka+Kerberos+Sentry认证
(2)使用jar包:(同上)
(3)核心代码:由于需要添加额外的kafka参数,因此采用了另一个“createStream”的重载方法。
public static void main(String[] args) {
SparkConf sparkConf = new SparkConf().setAppName("PrintDirectMsg").setMaster("local[2]");
final JavaStreamingContext jssc = new JavaStreamingContext(sparkConf, new Duration(10000));
Map<String, Integer> topicmap = new HashMap<>();
topicmap.put("gaoweiurl", 2);
HashMap<String, String> kafkaParams = new HashMap<String, String>();
kafkaParams.put("zookeeper.connect", "host1:2181,host2:2181,host3:2181";);
kafkaParams.put("group.id", "mygroup");
kafkaParams.put("auto.offset.reset", "largest");
/** 以下是和Kerberos+sentry认证相关 **/
kafkaParams.put("security.protocol", "SASL_PLAINTEXT");
kafkaParams.put("sasl.mechanism", "GSSAPI");
kafkaParams.put("sasl.kerberos.service.name", "kafka");
System.setProperty("java.security.auth.login.config", "/xx/xx/kafka-jaas.conf");
System.setProperty("java.security.krb5.conf", "/xx/xx/krb5.conf");
JavaPairInputDStream<String, String> lines = KafkaUtils.createStream(jssc, String.class, String.class, StringDecoder.class, StringDecoder.class, kafkaParams, topicmap, StorageLevel.MEMORY_AND_DISK_SER_2());
JavaDStream<String> msg = lines.map(new Function<Tuple2<String, String>, String>() {
@Override
public String call(Tuple2<String, String> tuple2) throws Exception {
return tuple2._1() + "," + tuple2._2();
}
});
msg.print(20);
jssc.start();
jssc.awaitTermination();
}
(4)问题及分析

Zookeeper可以正常连接,而且日志显示,已经成功通过Kerberos+sentry认证。
但是在开始消费消息的时候,一直报一个错误:

通过异常堆栈一行行的查找源码,首先:
==>“at org.apache.kafka.common.utils.Utils.formatAddress(Utils.java:312)”
抛出了空指针异常。进入代码发现:

说明传入host为空。
==>“at kafka.cluster.Broker.connectionString(Broker.scala:62)”
说明是创建Broker对象的时候,调用“connectionString(host,port)”出现的。
查看这个方法,是Broker的一个成员方法

创建Broker的时候,入参host为空,那么是谁创建Broker对象呢?
==>“at kafka.client.ClientUtils$$anonfun$fetchTopicMetadata$5.apply(ClientUtils.scala:89)”

这行代码说明,是有人先创建了“brokers”,然后在执行“fetchTopicMetadata”方法的时候,
执行broker.map(_.connectionString),而brokers的“host”为空,所以空指针异常。
这里的结果已经明确了,但是,还没有找到brokers对象创建的地方。
异常堆栈在这个地方的时候就断了。剩下的就是找到brokers的创建位置。
接下来从下往上看异常:
==>“at kafka.consumer.ConsumerFetcherManager$LeaderFinderThread.doWork(ConsumerFetcherManager.scala:66)”

线程“LeaderFinderThread”启动之后,开始执行doWork()方法。
然后创建了brokers,然后通过“ClientUtlis.fetchTopicMetadata”触发了前面的空指针错误。
那么“getAllBrokersInCluster(zkClient)”方法是怎么生成brokers的呢?
首先,这个例子是通过Zookeeper获取broker的,这个地方基本上可以确定是通过zk获取kafka的broker信息。
通过





进入“getAllBrokersInCluster”方法:
其中,BrokerIdspath为:
接下来,
总之,就是会读取“brokers/ids/id”中的信息,返回brokerInfo,然后创建broker。
回到Broker,进入“createBroker”方法查看:
最终,看看配置了Kerberos+Sentry的kafka的broker信息吧,
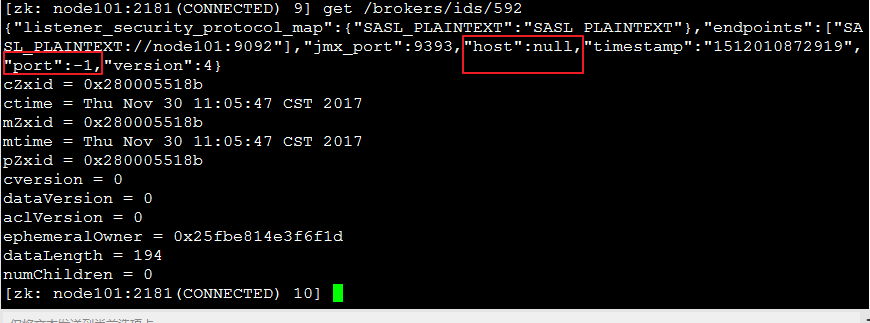
呵呵,比较下不加Kerberos+sentry的kafka的broker信息:

呵呵。
【实验3】无法运行
(1)kafka环境:kafka+Kerberos+Sentry认证
(2)使用jar包:(同上)
(3)核心代码:使用createDirectStream,不用Zookeeper,直接连接broker。
import java.util.HashMap;
import java.util.HashSet;
import java.util.Map;
import java.util.Set;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.streaming.Duration;
import org.apache.spark.streaming.api.java.JavaDStream;
import org.apache.spark.streaming.api.java.JavaPairInputDStream;
import org.apache.spark.streaming.api.java.JavaStreamingContext;
import org.apache.spark.streaming.kafka.KafkaUtils;
import kafka.serializer.StringDecoder;
import scala.Tuple2;
public class PrintDirectMsgDirect {
public static void main(String[] args) {
SparkConf sparkConf = new SparkConf().setAppName("PrintDirectMsg").setMaster("local[2]");
final JavaStreamingContext jssc = new JavaStreamingContext(sparkConf, new Duration(10000));
int numThreads = 2;
Map<String, Integer> topicmap = new HashMap<>();
topicmap.put("gaoweiurl", numThreads);
Set<String> topicSet = new HashSet<>();
topicSet.add("gaoweiurl");
HashMap<String, String> kafkaParams = new HashMap<String, String>();
kafkaParams.put("bootstrap.servers", "node86:9092,node99:9092,node101:9092");
kafkaParams.put("metadata.broker.list", "node86:9092,node99:9092,node101:9092");
kafkaParams.put("group.id", "spark-executor-kafka_shjs_wlpt");
kafkaParams.put("auto.offset.reset", "smallest");
kafkaParams.put("enable.auto.commit", "true");
kafkaParams.put("security.protocol", "SASL_PLAINTEXT");
kafkaParams.put("sasl.mechanism", "GSSAPI");
kafkaParams.put("sasl.kerberos.service.name", "kafka");
System.setProperty("java.security.auth.login.config", "D:\Kerberos\kafka-jaas.conf");
System.setProperty("java.security.krb5.conf", "D:\Kerberos\krb5.conf");
JavaPairInputDStream<String, String> lines= KafkaUtils.createDirectStream(jssc, String.class, String.class,
StringDecoder.class, StringDecoder.class, kafkaParams, topicSet);
JavaDStream<String> msg = lines.map(new Function<Tuple2<String, String>, String>() {
@Override
public String call(Tuple2<String, String> tuple2) throws Exception {
return tuple2._1() + "," + tuple2._2();
}
});
msg.print(20);
jssc.start();
jssc.awaitTermination();
}
}
(4)结果及分析

然后,百度了下,呵呵。

Spark的1.x版本不支持“Secure Kafka”。
【实验4】失败后成功
换了高版本的spark和sparkStreaming和sparkStreamingKafka的jar包
(1)kafka环境:kafka+Kerberos+Sentry认证
(2)使用jar包:全部是高版本
<spark.version>2.1.0</spark.version>
<spark-streaming-kafka.version>2.1.0</spark-streaming-kafka.version>
<!-- spark core 核心依赖包 -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.10</artifactId>
<version>${spark.version}</version>
</dependency>
<!-- spark streaming 依赖包 -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.10</artifactId>
<version>${spark.version}</version>
</dependency>
<!-- spark streaming kafka 依赖包 -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-10_2.10</artifactId>
<version>${spark-streaming-kafka.version}</version>
</dependency>
(3)核心代码:
package com.ustcinfo.ishare.bdp.spark
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.streaming.kafka010._
import org.apache.spark.streaming.kafka010.LocationStrategies.PreferConsistent
/**
* @Description: 所有spark任务的总入口
* @author: Beethoven.S
* @date: 2017/9/14 13:50
* @e-mail: sheng.gang@ustcinfo.com
*/
object sparkJobExecutor {
/** krb5.conf配置文件 **/
val KRB5_CONF: String = "D:\Kerberos\krb5.conf"
/** JAAS配置文件 **/
val KAFKA_JAAS_CONF: String = "D:\Kerberos\kafka-jaas.conf"
/** kafka broker地址,多个broker用逗号分开 **/
val KAFKA_BROKERS: String = "node86:9092,node99:9092,node101:9092"
def main(args: Array[String]) {
/** 添加Kerberos认证所需的JAAS配置文件到运行时环境 **/
System.setProperty("java.security.auth.login.config", KAFKA_JAAS_CONF)
/** 添加krb5配置文件到运行时环境 **/
System.setProperty("java.security.krb5.conf", KRB5_CONF)
val sparkConf = new SparkConf().setMaster("local[4]").setAppName("sparkStreaming")
val streamingContext = new StreamingContext(sparkConf, Seconds(10))
val stream = KafkaUtils.createDirectStream[String, String](
streamingContext,
PreferConsistent,
ConsumerStrategies.Subscribe[String, String](Array("gaoweiurl"), Map(
"bootstrap.servers" -> "node86:9092,node99:9092,node101:9092",
"key.deserializer" -> "org.apache.kafka.common.serialization.StringDeserializer",
"value.deserializer" -> "org.apache.kafka.common.serialization.StringDeserializer",
"group.id" -> "kafka_shjs_wlpt",
"enable.auto.commit" -> "true",
"auto.offset.reset" -> "earliest",
"sasl.kerberos.service.name" -> "kafka",
"security.protocol" -> "SASL_PLAINTEXT"
))
)
stream.foreachRDD(kv => {
println("============> ")
kv.foreach(x => println("RDD==> " + x))
})
streamingContext.start()
streamingContext.awaitTermination()
}
}
然后,在没有数据写入的时候,很正常,但是一旦开始接收数据之后,就会出现如下错误:

没错,sparkStreaming开始监听并且连接的时候,用的消费者组ID确实是我代码中配置的:

但是,一旦开始接收消息,通过RDD读取数据的时候,groupId居然被自动添加了“spark-executor-”的前缀。
(我这个开始设置的“spark-executor-kafka_shjs_wlpt”这个就是看看是不是有了前缀就不再加的,结果,
还是自动的添加了前缀,成了“spark-executor-spark-executor-kafka_shjs_wlpt”)。
然后,在spark运行的时候发现了这句话:

找到“KafkaUtils”代码中,追踪到万恶之源:

而且是,只要收到消息,创建RDD的时候会这么干:

解决方式就是覆盖这个源码:

注意覆盖的时候,包的名称路径必须要和源码路径一模一样,否则会出现scala的私有依赖引用问题。
然后再次,执行:

kafka的数据可以正常读取。
