数据结构
2.树
2.1二叉树
**定义:**每个节点不能有多于两个节点 **性质:**一个平均二叉树的深度要比节点个数$N$小得多,平均深度为$O(sqrt {N})$,最坏为$N-1$, **特别地,**二叉查找树的平均深度为$O(logN)$. 由于二叉查找最多有两个子节点,所以可以直接保链接到它们链。节点包括三部分:
- element(元素)
- left节点的引用
- right节点的引用
应用:编译器的设计领域
表达式数:树叶为操作数,其他节点为操作符,当所有的操作时二元的则刚好是二叉树,也有一些更复杂的情况,比如有些一目的操作符,或者需要多个操作数。
通过对树叶进行先序遍历、后序便利、中序遍历,依次可以得到前缀表达式(节点、左子树、右子树),后缀表达式(左子树、右子树、节点),中缀表达式(左子树,节点,右子树)
构造表达树算法:把后缀表达式转化为表达式树
输入为一个后缀表达式,一次一个符号地读入表达式
若符号是操作数,我们就建立一个单节点树,并将它推入栈中,如果符号是操作符,就熊栈中弹出两颗树(T_1)和(T_2)((T_1)先弹出)并形成一颗新的树,该树的根就是操作符,它的左右儿子分别是(T_2)和(T_1)(注意这里的顺序)。然后这颗新树压入栈中。
2.2二叉查找树
**特点:**使得二叉树成文二叉查找树的性质是:对于树中的每个节点$X$,它的左子树中所有项的值小于$X$中的项,而它的右子树中所有项的值大于X中的项。 **注:**根据以上的要求可知,二叉查找树要求所有的项都能够排序。实现接口Comparable,通过compareTo比较,通过该方法返回0判断两项相等(而不是使用equal),可以使用一个函数对象进行比较也就是比较器Comparator ####2.2.1contains方法 **作用:**如果在树T中存在含有项X的节点,那么这个操作需要返回true,否则返回false 如果T是空集,直接返回false,若存储在T出的项是X,,返回true,否则,对树T的左子树或右子树进行一次递归调用(依赖X与存储在T中项的关系,X小于T中的项则对左子树进行调用) **实现方法:** ####2.2.2findMin方法和findMax方法 **findMin方法:**递归调用左子树 **findMiax方法:**递归调用右子树 ####2.2.3insert方法: 可以像用contains那样沿着树查找,如果找到X,则什么也不用做,否则,将X插入到遍历路径上的最后一点。若为空树,新建一个节点,否则递归的插入x到适当的子树中(这里类似于contains) ####2.2.4remove方法 * 若节点为叶子节点直接删除, * 若节点有一个儿子:可以在该节点的父节点调整自己的链,绕过该节点,然后删除 * 若节点有两个儿子:用右子树的最小的数据代替该节点的数据并递归的删除那个歌节点(现在它是空的)。因为右子树的最小的节点没有左儿子,所以第二次remove更容易,上面的这种删除方法有助于是的左子树比右子树深度深,我们可以随机选取右子树的最小元素或者左子树的最大元素来代替被删除的元素以消除这种不平衡问题。
懒惰删除:当一个元素要被删除时,他仍然被留在树中,而只是被标记删除。
懒惰好处:
- 实际节点数和“被删除”的节点数相同时,数的深度预计只上升一个小的常数
- 时间消耗很小
- 被删除项刚好是新插入的项,避免分配一个新单元的开销。
2.2.5运行时间
内部路径长:所有节点的深度的和
在没有删除或者使用懒惰删除的情况下,我们可以断言:上述的操作的平均时间都是(O(log(N))),(平均是针对向二叉查找树中所有可能的插入序列进行的)
若向数中插入预先排好序的数据,就会花费二次时间,代价很多,因为树将只有没有左儿子的节点组成,所以需要有平衡的附加条件。
2.3 AVL树
**定义:**带有平衡条件的二叉查找树,每个节点的左子树和右子树的高度最多差1的二叉查找树(空树的高度为-1)。每个节点(在其节点结构中)保留高度信息。 高度为$h$的AVL树中,最少节点数$S(h)=S(h-1)+S(h-2)+1$对AVL插入,导致数的平衡破坏的情况,对于第一个平衡被破坏的节点(即最深的节点)(alpha),出现不平衡的四种情况:
- 对左儿子的左子树进行插入
- 对左儿子的右子树进行插入
- 对右儿子的左子树进行插入
- 对右儿子的右子树进行插入
1和4发生在“外边”可以通过单旋转调整平衡
2和3发生在“内部”需要通过双旋转调整平衡
情形1和4是关于(alpha)镜面对称的,后面的旋转也可看出这一点
2.3.1 单旋转
(k_2)为第一个平衡被破坏的节点
情形1:
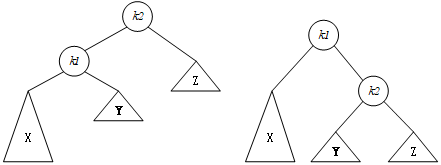
情形4

2.3.2 双旋转、
(k_3)为第一个平衡被破坏的节点
情形2
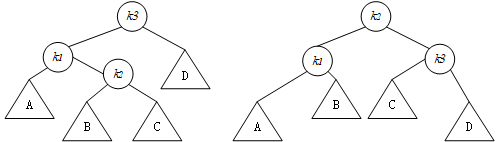
情形3

2.3.3插入
与二叉查找树的插入删除类似,只是多了一个平衡。部分代码如下:
/**
* Internal method to remove from a subtree.
* @param x the item to remove.
* @param t the node that roots the subtree.
* @return the new root of the subtree.
*/
private AvlNode<AnyType> remove( AnyType x, AvlNode<AnyType> t )
{
if( t == null )
return t; // Item not found; do nothing
int compareResult = x.compareTo( t.element );
if( compareResult < 0 )
t.left = remove( x, t.left );
else if( compareResult > 0 )
t.right = remove( x, t.right );
else if( t.left != null && t.right != null ) // Two children
{
t.element = findMin( t.right ).element;
t.right = remove( t.element, t.right );
}
else
t = ( t.left != null ) ? t.left : t.right;
return balance( t );
}
// Assume t is either balanced or within one of being balanced
private AvlNode<AnyType> balance( AvlNode<AnyType> t )
{
if( t == null )
return t;
if( height( t.left ) - height( t.right ) > ALLOWED_IMBALANCE )
if( height( t.left.left ) >= height( t.left.right ) )
t = rotateWithLeftChild( t );
else
t = doubleWithLeftChild( t );
else
if( height( t.right ) - height( t.left ) > ALLOWED_IMBALANCE )
if( height( t.right.right ) >= height( t.right.left ) )
t = rotateWithRightChild( t );
else
t = doubleWithRightChild( t );
t.height = Math.max( height( t.left ), height( t.right ) ) + 1;
return t;
}
/**
* Internal method to insert into a subtree.
* @param x the item to insert.
* @param t the node that roots the subtree.
* @return the new root of the subtree.
*/
private AvlNode<AnyType> insert( AnyType x, AvlNode<AnyType> t )
{
if( t == null )
return new AvlNode<>( x, null, null );
int compareResult = x.compareTo( t.element );
if( compareResult < 0 )
t.left = insert( x, t.left );
else if( compareResult > 0 )
t.right = insert( x, t.right );
else
; // Duplicate; do nothing
return balance( t );
}
/**
* Return the height of node t, or -1, if null.
*/
private int height( AvlNode<AnyType> t )
{
return t == null ? -1 : t.height;
}
/**
* Rotate binary tree node with left child.
* For AVL trees, this is a single rotation for case 1.
* Update heights, then return new root.
*/
private AvlNode<AnyType> rotateWithLeftChild( AvlNode<AnyType> k2 )
{
AvlNode<AnyType> k1 = k2.left;
k2.left = k1.right;
k1.right = k2;
k2.height = Math.max( height( k2.left ), height( k2.right ) ) + 1;
k1.height = Math.max( height( k1.left ), k2.height ) + 1;
return k1;
}
/**
* Double rotate binary tree node: first left child
* with its right child; then node k3 with new left child.
* For AVL trees, this is a double rotation for case 2.
* Update heights, then return new root.
*/
private AvlNode<AnyType> doubleWithLeftChild( AvlNode<AnyType> k3 )
{
k3.left = rotateWithRightChild( k3.left );
return rotateWithLeftChild( k3 );
}
AVL数的节点声明,是一个嵌套类:
private static class AvlNode<AnyType>
{
// Constructors
AvlNode( AnyType theElement )
{
this( theElement, null, null );
}
AvlNode( AnyType theElement, AvlNode<AnyType> lt, AvlNode<AnyType> rt )
{
element = theElement;
left = lt;
right = rt;
height = 0;
}
AnyType element; // The data in the node
AvlNode<AnyType> left; // Left child
AvlNode<AnyType> right; // Right child
int height; // Height
}
2.4伸展树
在前面的运行时间的讨论中,我们可以看到,在二叉查找树中,我们无法保证人与单个的操作的时间界为$O(log(N))$,但是某些自调整树结构可以保证连续的M次操作在最坏的情形下花费时间为$O(M log(N))$.伸展树:保证从空树开始连续M次对数的操作最多花费(O(M log(N)))时间。
堆还运行时间:一般来说,当M次操作的序列总的最坏运行时间为(O(M f(N)))时,我们就说它的堆还运行时间为(O( f(N)))。
一棵伸展树每次操作的堆还代价为(O(log(N)))
二叉查找树的问题在于,虽然一系列访问整体是坏的操作有可能发生,但是很罕见。
思路:只要一个节点被访问,它就必须被移动,否则,一旦发现一个深层的节点,我们就有可能不断对它进行访问。
伸展树的思想:当一个节点被访问时,他就要经过一系列AVL树的旋转被推到根上。注意,如果一个节点很深,那么在其路径上就存在许多也相对较深的节点,通过重新狗仔可以减少对所有这些节点的进一步访问,而且在实际中,一个节点被访问,很可能会在不久再次被访问,而且伸展树不要求保留高度或平衡信息,因此它在某种程度上节省空间并简化代码。
2.4.1实现方法一:单旋转
缺点:在将访问节点推向树根的过程中可能会会将另外的节点推向很深的深度,使得M个操作时间需要(Omega (M cdot N))
2.4.2实现方法二:展开
令X是访问路径上的一个(非根)节点,具体操作如下:
- 如果X的父节点是树根,那么只要旋转X和树根(这是沿着访问路径上的最后旋转)
- 如果X有父亲(P)和祖父(G),存在两种情况以及对应的情形要考虑
- 之字形情形:X是右儿子,P是左儿子;或者X左儿子,P是右儿子:此时执行一次像AVL双旋转那样的双旋转
- 一字型情形:X是右儿子,P是右儿子;或者X左儿子,P是左儿子:此时执行一次下图所示的对应的旋转
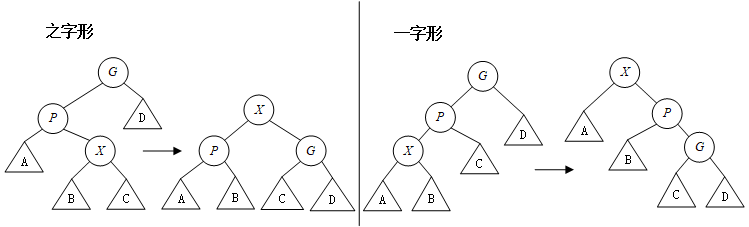
展开的优势:展开操作不仅将访问的节点移动到根处,而且还把访问路径上的大部分节点的深度大致减小一半(某些浅的节点最多向下推后两层)
展开树的基本的和关键的性质:当访问路径长而导致超出正常查找时间的时候这些旋转将对未来的操作有益;而当耗时很少的时候,这些旋转则不那么有益甚至有害
展开带来的新的节点删除方法:通过要被访问的节点来执行删除。这种删除将节点推到根处,如果删除该节点这得到两个子树(T_L)和(T_R)(左子树和右子树)。如果我们知道(T_L)中最大的元素,那么这个元素就被旋转到(T_L)的根下,而此时(T_L)将有一个没有有儿子的根,我们可以使(T_R)为其右儿子完成删除。