一、GFS
Google File System就是HDFS的前身
HDFS 参照了GFS的设计理念,大部分架构设计概念是类似的,比如 HDFS NameNode 相当于 GFS Master,HDFS DataNode 相当于 GFS chunkserver
1.设计目标:
- 多个客户端可以在不需要额外的同步锁定的 情况下,同时对一个文件追加数据
一个问题:
一个 Chunk块为64MB,HDFS中的一个块大小也64MB,但是一般的文件系统中一个磁盘块大小只有512B
=> 那么为什么分布式文件系统中的一个数据块要设置的这么大呢?
0. 目的是为了最小化寻址开销,
1. 采用较大的 Chunk 尺寸,客户端能够对一个块进行多次操作,这样就可以 通过与 Chunk 服务器保持较长时间的 TCP 连接来减少网络负载
2.架构:
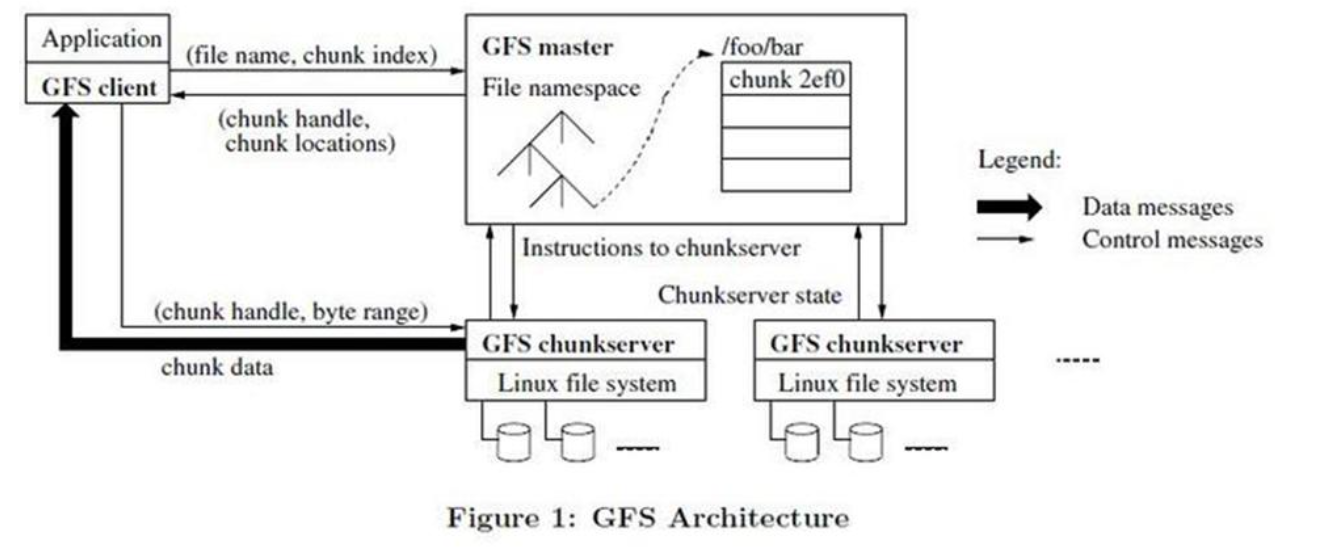
- Master 节点使用心跳信息周期地和每个 Chunk 服务器通讯,发送指令到各个 Chunk 服务器并接收 Chunk 服务器的状态信息。
- 客户端并不通过 Master 节点读写文件数据。反之,客户端向 Master 节点询问它应该联系的 Chunk 服务器。 客户端将这些元数据信息缓存一段时间,后续的操作将直接和 Chunk 服务器进行数据读写操作。
3.GFS的一致性模型:
尽量采用追加写入而不是覆盖,Checkpoint,自验证的写入操作,自标识的记录
4. 对比HDFS架构:
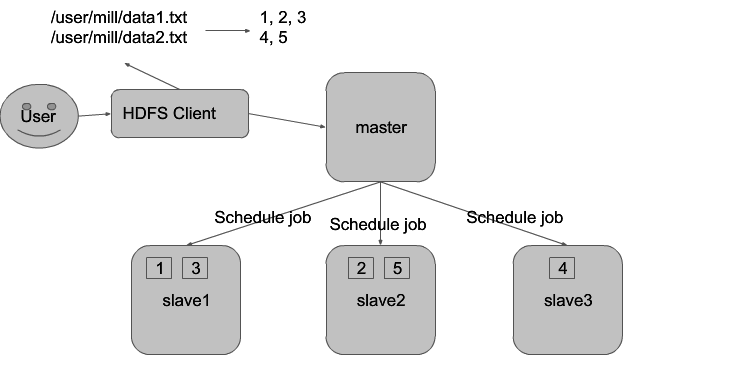
- master slave model: 只有主人和slave进行主观能动的通信,slave间不会通信。
- master只会决定哪个slave去做读/写工作,然后client会直接和slave去传输。master只会收到request,master不会传输数据。
- 怎么存储数据:block of small file
- 谁负责去将数据拆分成小的blocks? => HDFS client
二、BigTable
三、MapReduce