0.前次作业:从文件创建DataFrame
1.pandas df 与 spark df的相互转换 df_s=spark.createDataFrame(df_p) df_p=df_s.toPandas()
# 从数组创建pandas dataframe import pandas as pd import numpy as np arr = np.arange(6).reshape(-1,3) arr df_p = pd.DataFrame(arr) df_p df_p.columns = ['a','b','c'] df_p

# pandas df 转为spark df df_s = spark.createDataFrame(df_p) df_s.show() df_s.collect()

# spark df 转为pandas df df_s.show() df_s.toPandas()

2. Spark与Pandas中DataFrame对比
http://www.lining0806.com/spark%E4%B8%8Epandas%E4%B8%ADdataframe%E5%AF%B9%E6%AF%94/
3.1 利用反射机制推断RDD模式
- sc创建RDD
spark.sparkContext.textFile("file:///D:/Spark/spark-2.4.7-bin-hadoop2.7/examples/src/main/resources/people.txt").first() spark.sparkContext.textFile("file:///D:/Spark/spark-2.4.7-bin-hadoop2.7/examples/src/main/resources/people.txt") .map(lambda line:line.split(',')).first()

- 转换成Row元素,列名=值
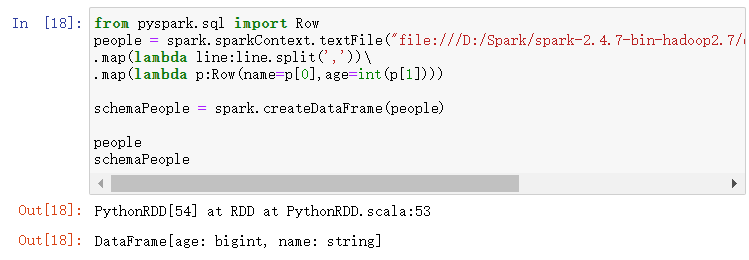
from pyspark.sql import Row people = spark.sparkContext.textFile("file:///D:/Spark/spark-2.4.7-bin-hadoop2.7/examples/src/main/resources/people.txt") .map(lambda line:line.split(',')) .map(lambda p:Row(name=p[0],age=int(p[1])))
- spark.createDataFrame生成df
schemaPeople = spark.createDataFrame(people)
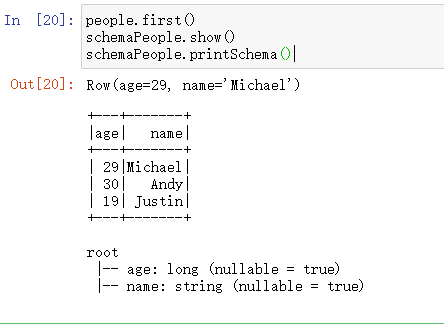
- df.show(), df.printSchema()
schemaPeople.show()
schemaPeople.printSchema()
3.2 使用编程方式定义RDD模式
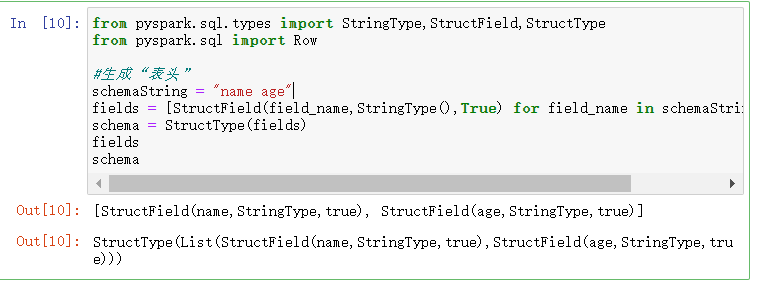
- 生成“表头”
- fields = [StructField(field_name, StringType(), True) ,...]
- schema = StructType(fields)
from pyspark.sql.types import StringType,StructField,StructType from pyspark.sql import Row #生成“表头” schemaString = "name age" fields = [StructField(field_name,StringType(),True) for field_name in schemaString.split(" ")] schema = StructType(fields)
- 生成“表中的记录”
- 创建RDD
- 转换成Row元素,列名=值
# 生成“表中的记录” lines = spark.sparkContext.textFile("file:///D:/Spark/spark-2.4.7-bin-hadoop2.7/examples/src/main/resources/people.txt") parts = lines.map(lambda x:x.split(",")) people = parts.map(lambda p:Row(p[0],p[1].strip())) people.collect()
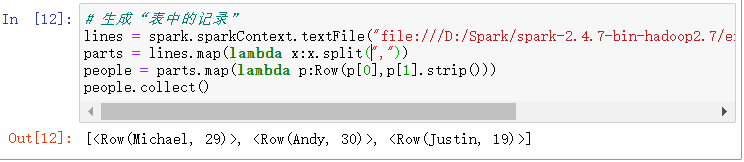
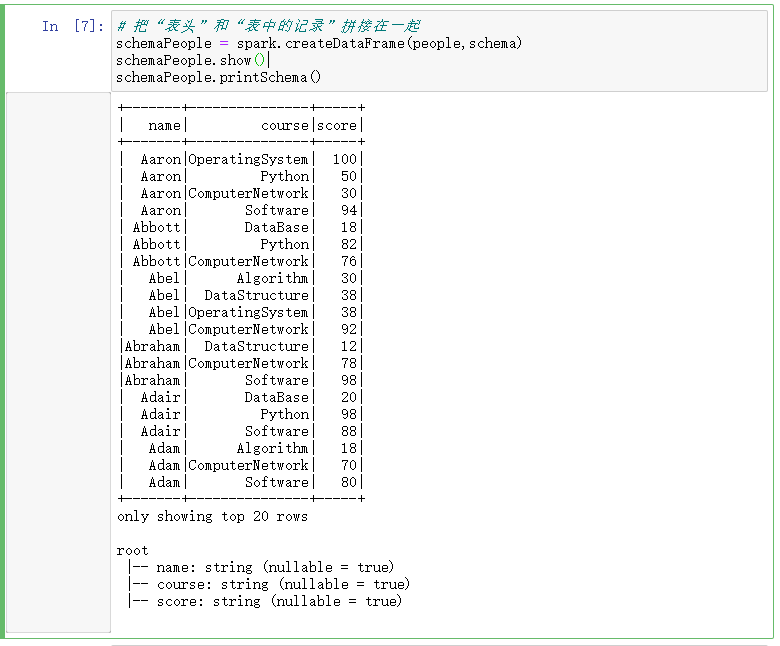
- 把“表头”和“表中的记录”拼装在一起
- = spark.createDataFrame(RDD, schema)
# 把“表头”和“表中的记录”拼接在一起 schemaPeople = spark.createDataFrame(people,schema) schemaPeople.show() schemaPeople.printSchema()

4. DataFrame保存为文件
df.write.json(dir)
schemaPeople.write.json("file:///D:/Demo/schemaPeople")
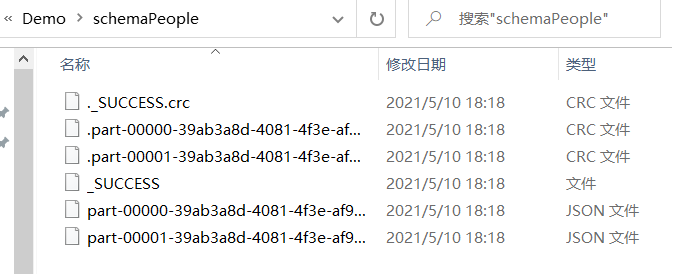
预练习:
读 学生课程分数文件chapter4-data01.txt,创建DataFrame。并尝试用DataFrame的操作完成实验三的数据分析要求。
1.利用反射机制推断RDD模式
from pyspark.sql import Row people = spark.sparkContext.textFile("file:///D:/chapter4-data01.txt") .map(lambda line:line.split(',')) .map(lambda p:Row(name=p[0],course=p[1],score=int(p[2]))) df = spark.createDataFrame(people) people df
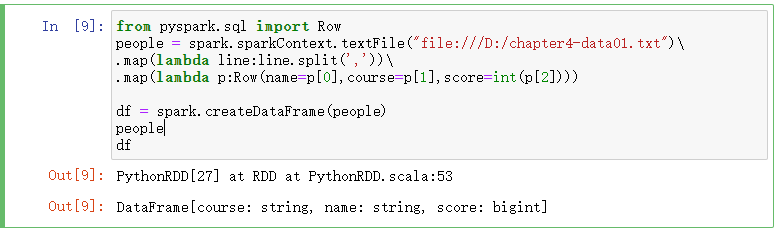
people.first()
df.show()
df.printSchema()

2.使用编程方式定义RDD模式
url = "file:///D:/chapter4-data01.txt" rdd = sc.textFile(url).map(lambda line:line.split(',')) rdd.take(3)

from pyspark.sql.types import IntegerType,StringType,StructField,StructType from pyspark.sql import Row #生成“表头” schemaString = "name course score" fields = [StructField(field_name,StringType(),True) for field_name in schemaString.split(" ")] schema = StructType(fields) fields schema
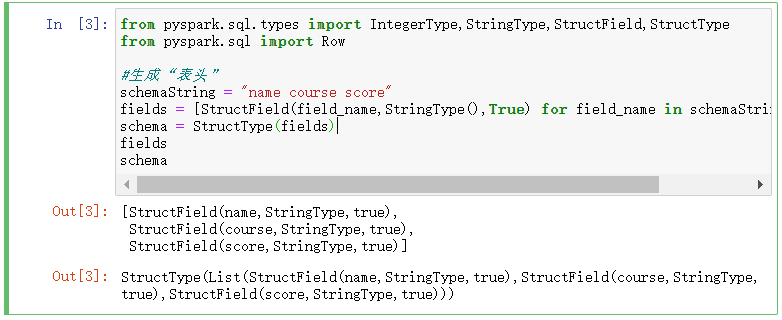
# 生成“表中的记录” lines = spark.sparkContext.textFile("file:///D:/chapter4-data01.txt") parts = lines.map(lambda x:x.split(",")) people = parts.map(lambda p:Row(p[0],p[1],p[2].strip())) people.collect()
# 把“表头”和“表中的记录”拼接在一起 schemaPeople = spark.createDataFrame(people,schema) schemaPeople.show() schemaPeople.printSchema()