Liu J, Wang S, Urtasun R. DSIC: Deep Stereo Image Compression[C]//Proceedings of the IEEE International Conference on Computer Vision. 2019: 3136-3145.
- 作者主要是讲利用深度学习的方法,对双摄像头拍摄的立体深度图像进行信息共享、实现压缩效率的提高,即Deep Stereo Image Compression
DSIC工作已完整复现
基于pytorch框架
完成模型的训练、测试、包括熵编码(采用独立的Range coder实现)工程实现
其中熵编码工程实现基于混合高斯模型GMM(与论文一致),采用区间编码器实现,对于网络的训练过程此步可跳过,因为是无损编解码的过程。
详询vx: ywz978020607 注明来意
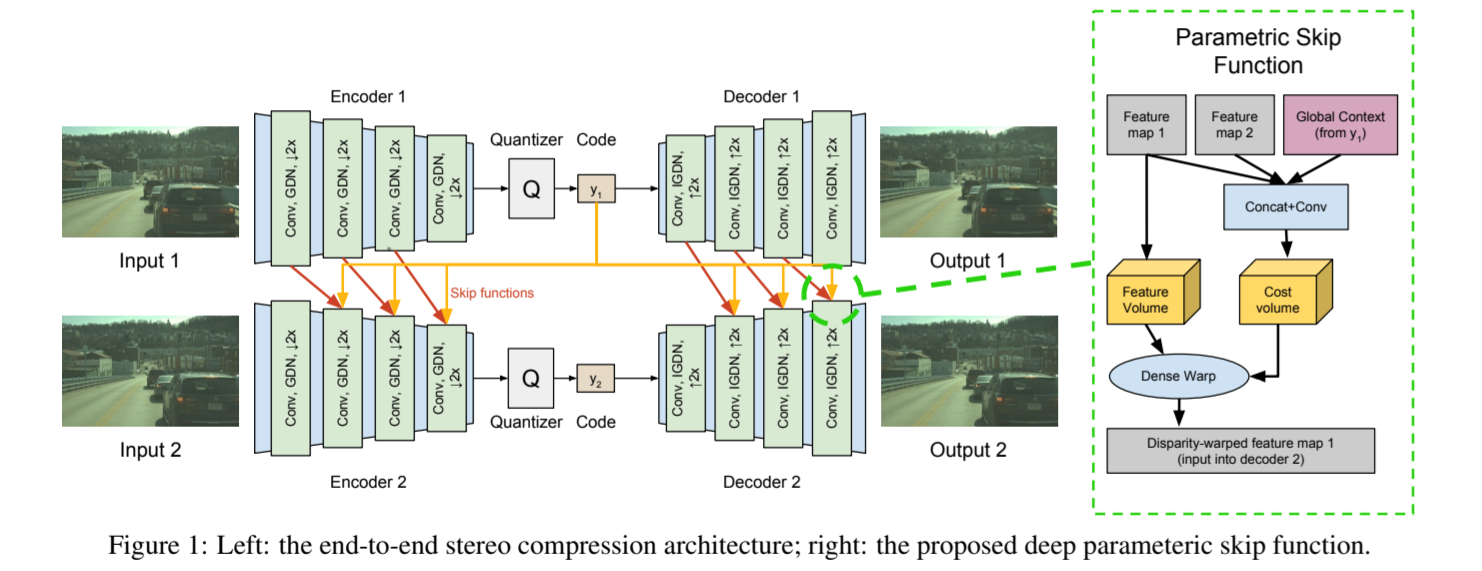
1.整体思路
1. 利用图像1经过网络和编码器后生成的code,对图像2的编码和解码过程进行参数“借鉴复用”,从而减少图像2所需的比特,称为Parametric skip function,下称参数跳传。
2. 对于这个参数“复用”的过程,作者利用熵编码提出了一种方法,有效最大化利用两幅图像的相似性。
1.1.编码/解码和量化过程
借鉴了一篇单张图像的压缩模型,编码器、解码器和量化器借鉴此篇论文Johannes Balle, David Minnen, Saurabh Singh, Sung Jin Hwang, and Nick Johnston. Variational image compression with a scale hyperprior. In ICLR, 2018.
编码器采用四次下采样的卷积层和GDN层,每个解码器是四个上采样(均为2x)和Inverse-GDN层实现。二者之间还有量化器将不同图片量化编码为不同码字。
` GDN是在图像压缩中用来代替BN层的一种方法,因为在图像编解码过程中要尽量减少噪声的引入,再使用BN层不合适,用GDN代替。 `
1.2 参数跳传(Parametric skip function)
参数跳传是实现本算法的核心,其依赖图像内容相似性以及图1编码后的码字的指导作用。
参数跳传部分是一个神经网络,使用前一层的图像1、2的数据和图像1的码字作为指导,由于认为立体拍摄的两张图像有大量重复相似内容,因此只要知道两幅特征图的差异估计,就可以将其中图像1的特征图进行warp弯曲映射到图像2对应的特征图中,来实现图像1和图像2的像素点级别的映射关系。之后便可通过学习训练得到这种映射关系,将图像1的特征准确直接地传递到图像2中。
1.3 条件熵模型
实现两幅图像复用的关键就是利用熵模型来实现。两幅图像的码字有强相关性。因此,作者提出了一个联合熵模型,利用神经网络估计码字的分布。
目标即为已知图像1,获取图像2的条件熵,并尽量降低两图像信息的联合熵。
作为深度学习的网络,通过损失函数反向传播调整参数,因此条件熵模型的作用也就在于,通过条件熵,让第二幅图的编码-解码的双通道尽可能地复用依赖图像1的支路,而让单独通过y2的支路尽可能小,留下“干货”,实现最大信息的复用。
注: 后续工作需要,暂不更新相关内容,此篇代码已复现,即将开源,有需要可联系。