0. 说明
【Spark 核心组件示意图】
1. RDD
resilient distributed dataset , 弹性数据集
轻量级的数据集合,逻辑上的集合。等价于 list
没有携带数据。
2. 依赖
RDD 的依赖是 子 RDD 上的每个分区和父 RDD 分区数量上的对应关系
Dependency
|----ShuffleDependency (宽依赖)
|----NarrowDependency (窄依赖:子 RDD 的每个分区依赖少量的父 RDD 分区)
|-----One2OneDependency (一对一依赖)
|-----RangeDependency(范围依赖)
|-----PruneDependency(Prune 依赖)
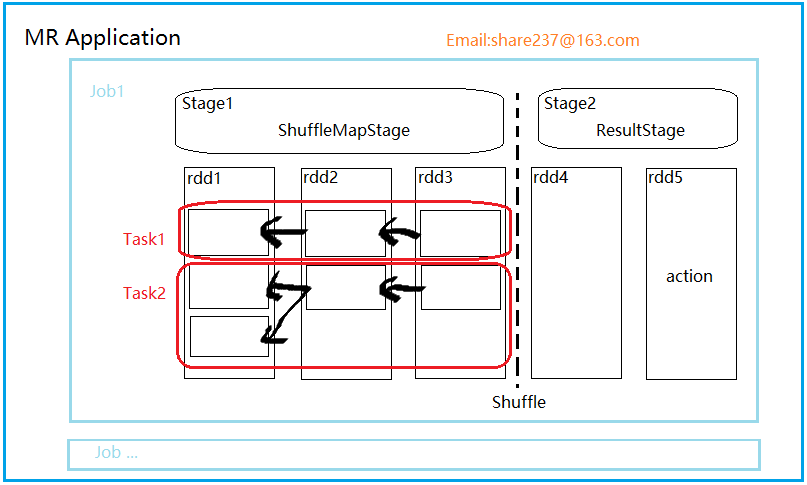
3. Stage(阶段)
并行的 task 集合,同一 Stage 的所有任务有着相同的 Shuffle 依赖。
阶段,一组RDD构成的链条。
阶段的划分按照 Shuffle 标记来进行的。
阶段类型有两种,ShuffleMapStage 和ResultStage。
【ShuffleMapStage】
该阶段任务的结果是下一个阶段任务的输入。需要跟踪每个分区所在的节点。
任务执行期间的中间过程,保存task的输出数据供下一个 reduce 进行 fetch(抓取) 。
该阶段可以单独提交。
【 ResultStage】
结果结果直接执行 RDD 的 action 操作。
对一些分区应用计算函数(不一定需要在所有分区进行计算,比如说first())。
最后一个阶段,执行task后的结果回传给driver
4. Task
task 是 Spark 执行单位,有两种类型。
【ShuffelMapTask】
在 ShuffleMapStage 由多个 ShuffleMapTask 组成。
【ResultTask】
ResultStage 由多个 ResultTask 组成,结果任务直接 task 后,将结果回传给 driver。
driver:
5. job
一个 action 就是一个 job
6. Application
一个应用可以包含多个 job
7. Spark Context
Spark 上下文是 Spark 程序的主入口点,表示到 Spark 集群的连接。可以创建 RDD 、累加器和广播变量。
每个 JVM 只能有一个 active 的上下文,如果要创建新的上下文,必须将原来的上下文 stop。
sc.textFile("");
sc.parallelize(1 to 10);
sc.makeRDD(1 to 10) ; //通过parallelize实现。