kafka简介
Kafka 2012年10月由Apache孵化。
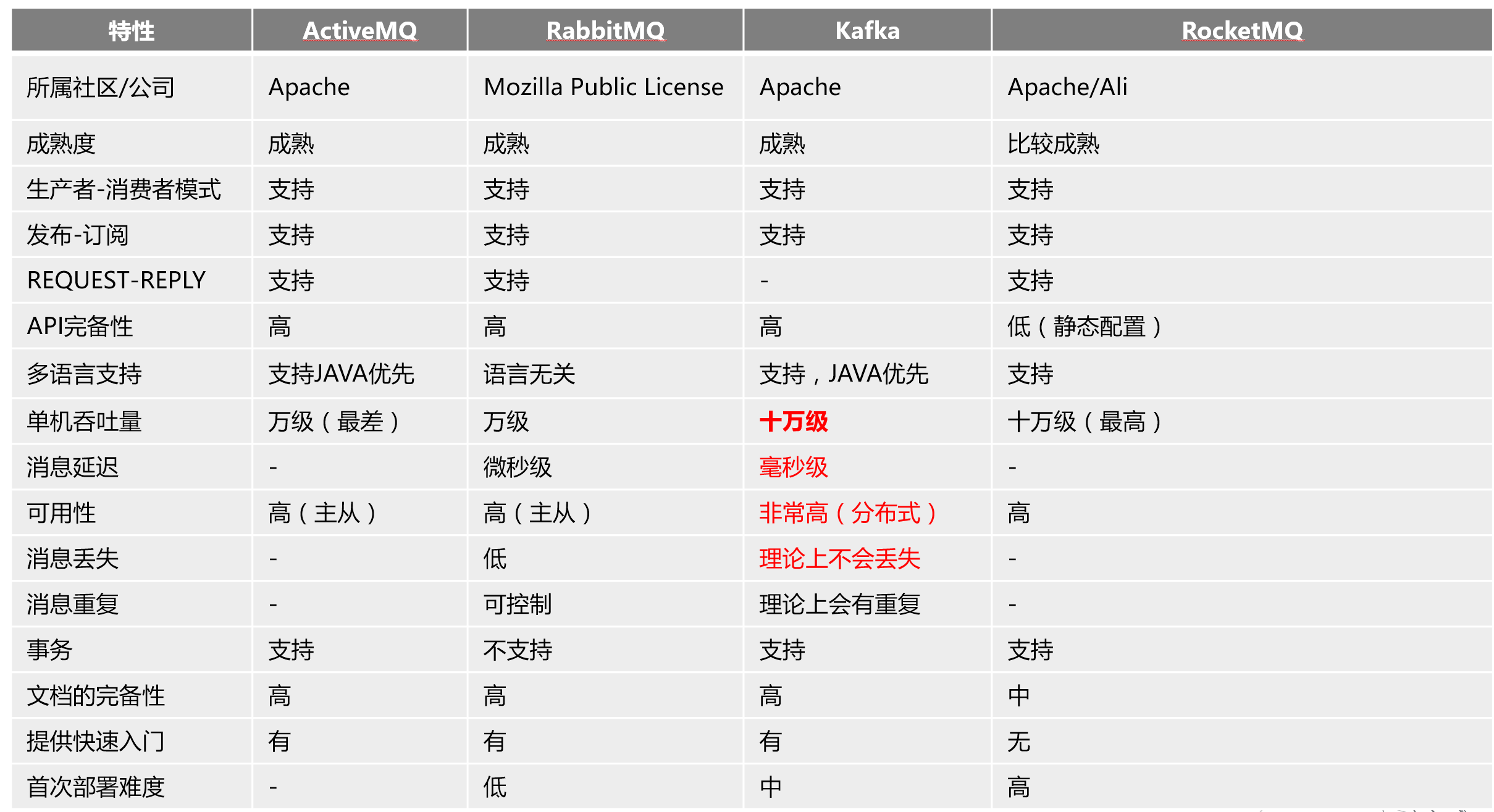
Kafka 是主流的消息队列组件,可以让后端服务之间轻松的相互沟通。
kafka有一个成熟且庞大的生态圈。
消息队列组件的比较
Kafka使用场景
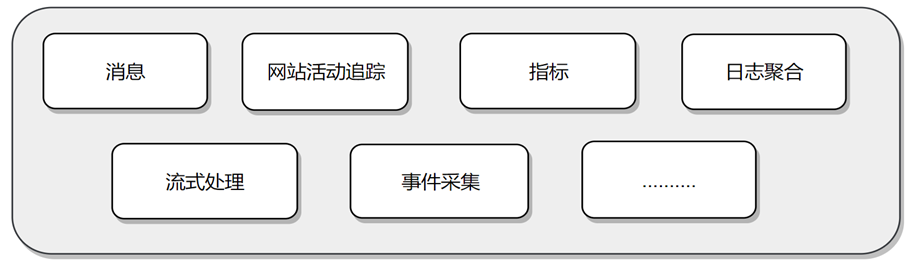
消息:替换传统的消息系统,解耦数据生产者,缓存未处理的消息。吞吐量,内置分区,副本和故障转移
网站活动追踪:网页游览,搜索或其他用户的操作信息,发布到不同的主题中,实时处理,实时监测,也可加载到Hadoop或离线处理数据仓库,生成用户画像。
指标:常常用于监测数据。分布式应用程序生成的统计数据集中聚合,补丁指标。
日志聚合:通常从服务器中收集物理日志文件,并将它们放在中央位置如文件服务器或HDFS进行处理。Kafka抽象出文件的细节,并将日志或事件数据更清晰地抽象为消息流。这允许更低延迟的处理并更容易支持多个数据源和分布式数据消费。
流处理:消息处理一般包含多个阶段。除了Kafka Streams,还有Apache Storm和Apache Samza可选择。
事件采集:事件采集是一种应用程序的设计风格,其中状态的变化根据时间的顺序记录下来,kafka支持这种非常大的存储日志数据的场景。
Kafka的四个核心API
1、应用程序使用 Producer API 发布消息到1个或多个topic(主题)中。
2、应用程序使用 Consumer API 来订阅一个或多个topic,并处理产生的消息。
3、应用程序使用 Streams API 充当一个流处理器,从1个或多个topic消费输入流,并生产一个输出流到1个或多个输出topic,有效地将输入流转换到输出流。
4、Connector API 可构建或运行可重用的生产者或消费者,将topic连接到现有的应用程序或数据系统。例如,连接到关系数据库的连接器可以捕获表的每个变更。

Kafka消息系统的基本结构
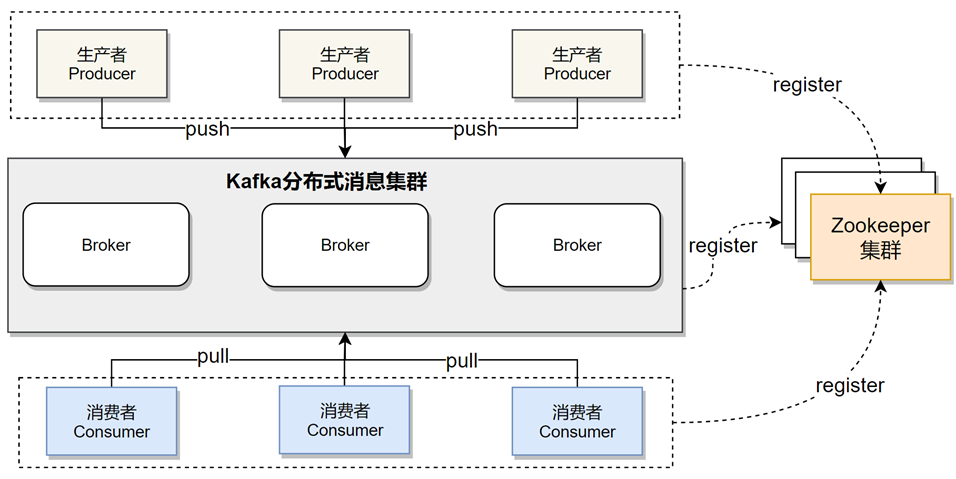
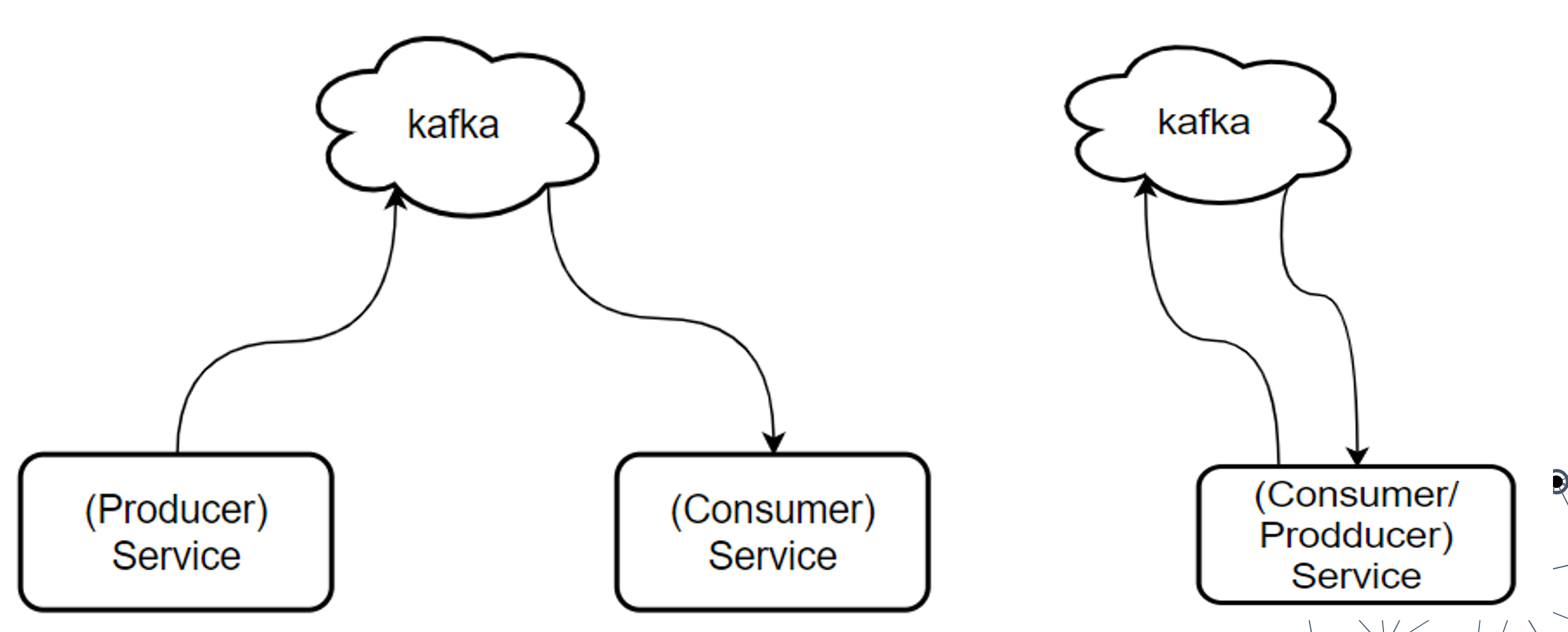
Kafka的基础讲解- Producer&Consumer
生产者-消费者( Producer & Consumer ):
服务 Producer 向 Kafka 发送消息,消费者服务 Consumer 监听 Kafka 接收消息。
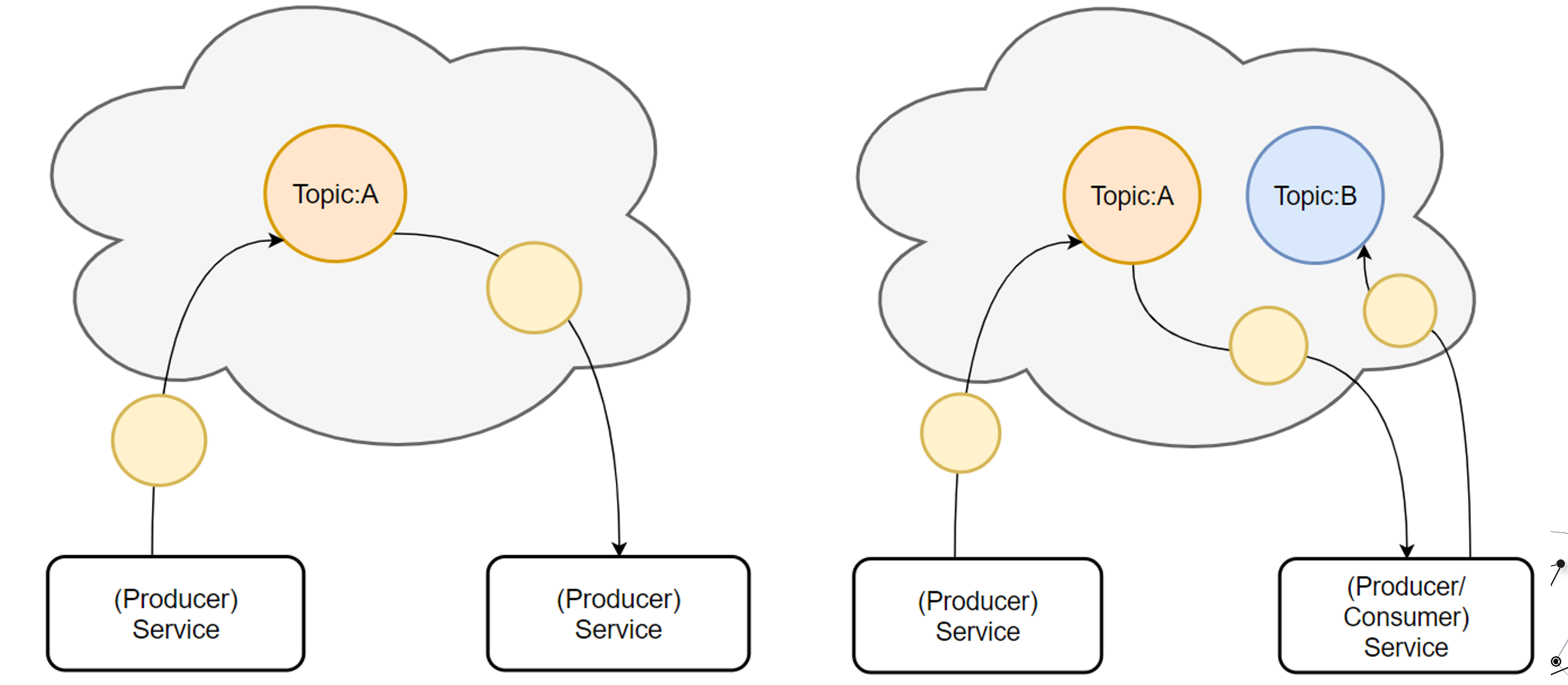
Kafka的基础讲解-Topic
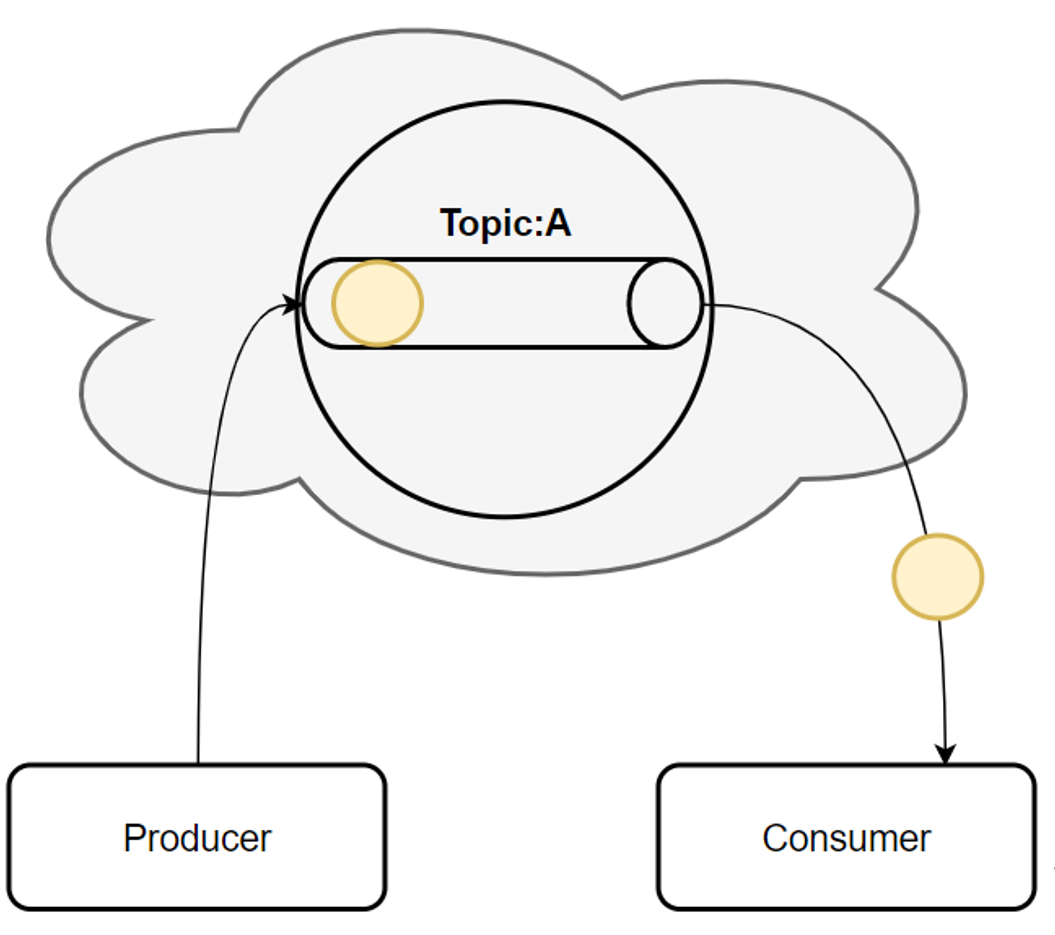
话题(Topic):是特定类型的消息流,话题是消息的分类名,是消费者的监听目标;
Kafka的基础讲解-consumer-group(消费者组)
这是一组服务,扮演一个消费者。
如果是消费者组接收消息,Kafka 会把一条消息路由到组中的某一个服务。
kafka中消费者组有两个概念:
队列:消费者组(consumer group)允许同名的消费者组成员瓜分处理。
发布订阅:允许你广播消息给多个消费者组(不同名),kafka的每个topic都具有这两种模式。
图2,仅仅是保证Topic的一个分区顺序处理,不能保证跨分区的消息先后处理顺序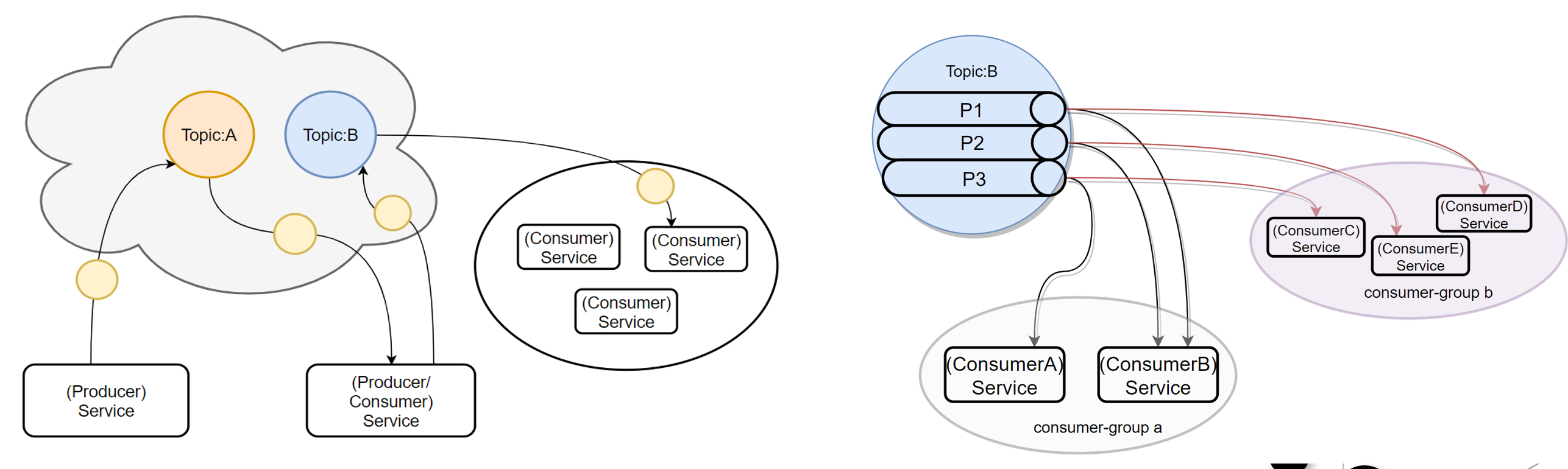
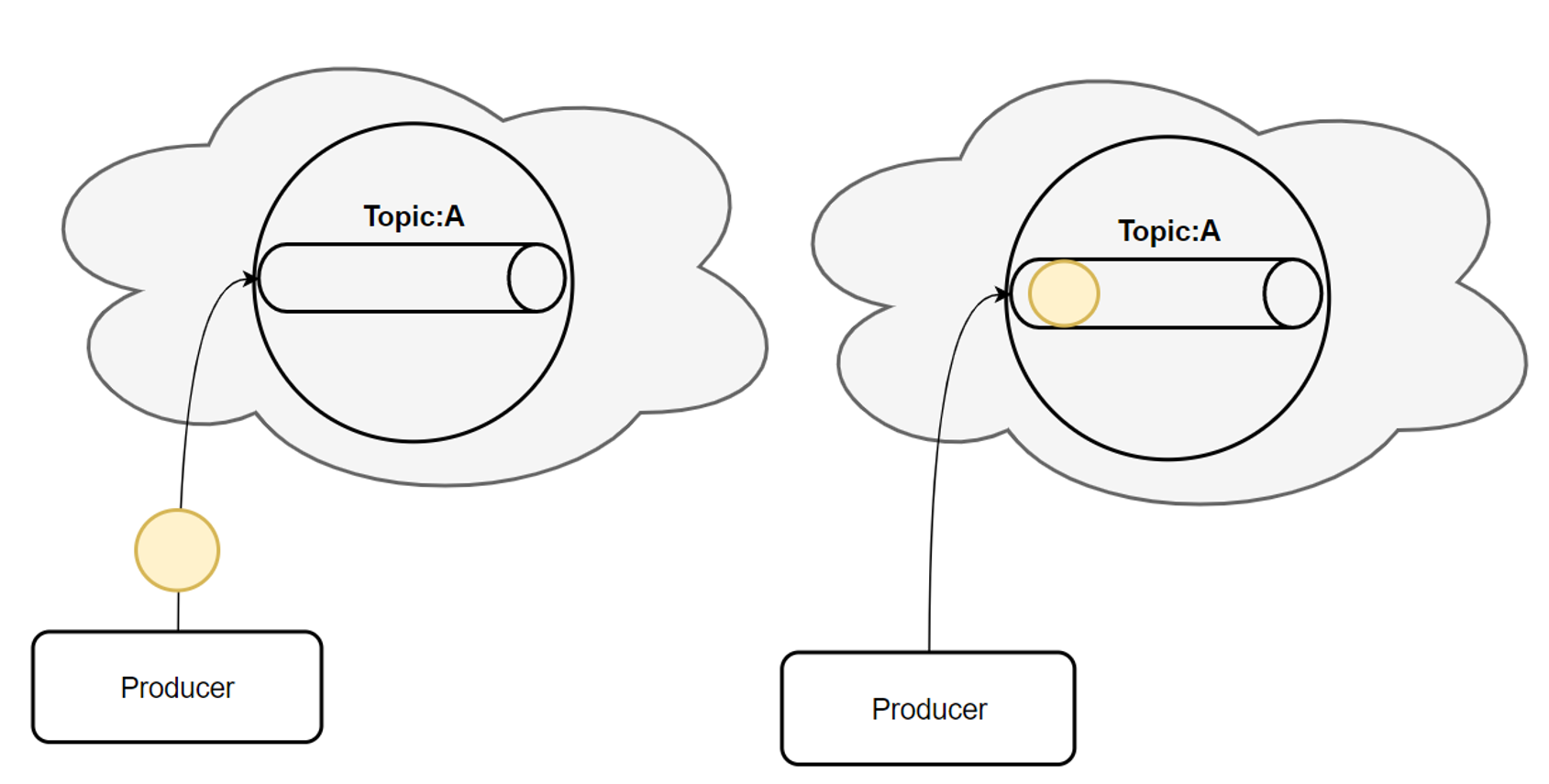
Kafka的基础讲解-Topic-消费过程
首先,一条消息发送了。
然后,这条消息被记录和存储在这个队列中,不允许被修改。
接下来,消息会被发送给此 Topic 的消费者。
但是,这条消息并不会被删除,会继续保留在队列中。
(消息在队列中能呆多久,可以修改 Kafka 的配置)
Kafka的基础讲解-Topic-Partitions-1
上面 Topic 的描述中,把 Topic 看做了一个队列,实际上,一个 Topic 是由多个队列组成的,被称为【Partition(分区)】,这样可以便于 Topic 的扩展。
生产者发送消息的时候,这条消息会被路由到此 Topic 中的某一个 Partition。
消费者监听的是所有分区。
生产者发送消息时,默认是面向 Topic 的,由 Topic 决定放在哪个 Partition,默认使用轮询策略。

Kafka的基础讲解-Topic-Partitions-2
也可以配置 Topic,让同类型的消息都在同一个 Partition。
例如,处理用户消息,可以让某一个用户所有消息都在一个 Partition。
例如,用户1发送了3条消息:A、B、C,默认情况下,这3条消息是在不同的 Partition 中(如 P1、P2、P3)。
在配置之后,可以确保用户1的所有消息都发到同一个分区中(如 P1)。

Kafka的基础讲解-Topic-Partitions-3
图1有2个 Topic,各自有2个 Partition,这是逻辑上的形式
图2 Topic A 和 Topic B 的所有 Partition 分布可能就是这样的

Kafka的基础讲解-offset
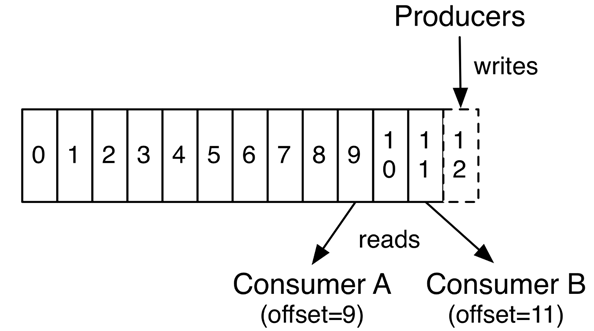
Offset偏移量:他是由消费者来控制:正常情况当消费者消费消息的时候,偏移量也线性的的增加。但是实际偏移量由消费者控制,消费者可以将偏移量重置为更早的位置,重新读取消息。
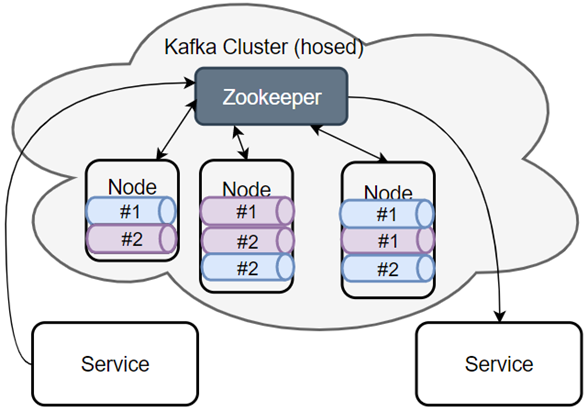
Offset存储:在旧版本的实现是在zookeeper上有个节点存放consumer的offset,后面考虑性能问题,kafka改到了topic里。可以自由配置是使用zookeeper还是topic。
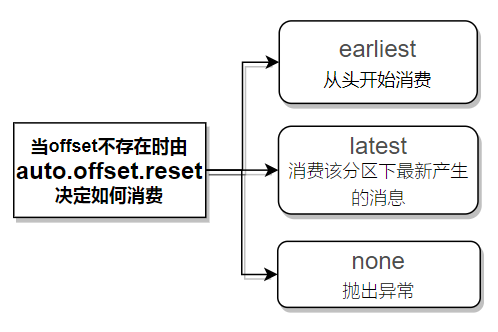
auto.offset.reset:kafka会根据该consumer记录的offset,传递对应消息消费,当offset不存在时,根据配置的值auto.offset.reset来决策消费方式。
Kafka的基础讲解-常见问题
kafka消息数据积压,kafka消费能力不足怎么处理
1) 如果是kafka消费能力不足,则可以考虑增加topic的分区数,并且同时提升消费者组的消费者数量,消费者数=分区数(两者缺一不可)
2)如果是下游的数据处理不及时:提高每批次拉取的数量,批次拉取数据过少(拉取数据/处理时间<生产速度),使处理的数据小于生产的数据,也会造成数据积压
