python + selenium
selenium 窗口切换:
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
driver = webdriver.Firefox()
driver.get("http://bj.ganji.com/")
time.sleep(3)
# 获取句柄
handle = driver.current_window_handle
print("获取到当前的handle:%s" % handle)
# 获取点击后新开页面的handle名字
driver.find_elements_by_class_name("dt-t")[0].click()
handle1 = driver.current_window_handle
print("获取到当前的handle:%s" % handle1)
# 切换到最后一个窗口
driver.switch_to_window(handles[-1])
# 判断是否切换成功:
# 可根据title判断
print(driver.title)
# 可根据页面唯一元素判断
# 新页面的元素操作完了,回到第一个页面
driver.close() # 关闭当前窗口
driver.switch_to_window(handle)
print(driver.title)
# 关闭全部窗口,退出进程
driver.quit()
下拉框,select :
from selenium import webdriver
from selenium.webdriver.common.action_chains import ActionChains
import time
driver = webdriver.Firefox()
url = "https://www.baidu.com"
driver.get(url)
time.sleep(3)
# 1、下拉框
mouse = driver.find_element("link text", "设置")
ActionChains(driver).move_to_element(mouse).perform()
time.sleep(0.5)
driver.find_element("link text", "搜索设置").click()
time.sleep(1)
# 方法一:直接定位
# 选择下拉框选项的第三项
driver.find_element_by_xpath(".//*[@id='nr']/option[3]").click()
# 若此时点击后,下拉选项未收回,可点击整个下拉框,收回下拉选项
driver.find_element_by_xpath(".//*[@id='nr']").click()
# 方法二:二次定位
# 第一步:定位下拉框
parent = driver.find_element_by_id("nr")
# 第二步:在下拉框中,定位子元素,并操作
parent.find_element_by_xpath('.//option[@value="20"]').click()
# select用法:
from selenium.webdriver.support.select import Select
# 先定位到下拉框
s = driver.find_element_by_id("nr")
# 第一种:根据索引定位(从0开始)
Select(s).select_by_index(0)
# 收回下拉选项
s.click()
# 第二种:根据value属性定位
# 如:value = 50
Select(s).select_by_value("50")
# 收回下拉选项
s.click()
# 第三种:根据选项内容定位
Select(s).select_by_visible_text("每页显示20条")
# 收回下拉选项
s.click()
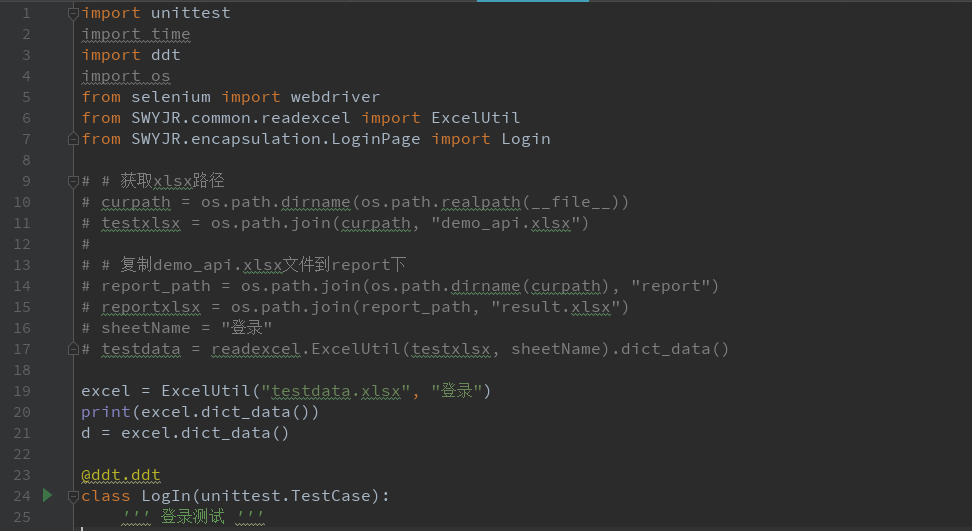
登录测试:
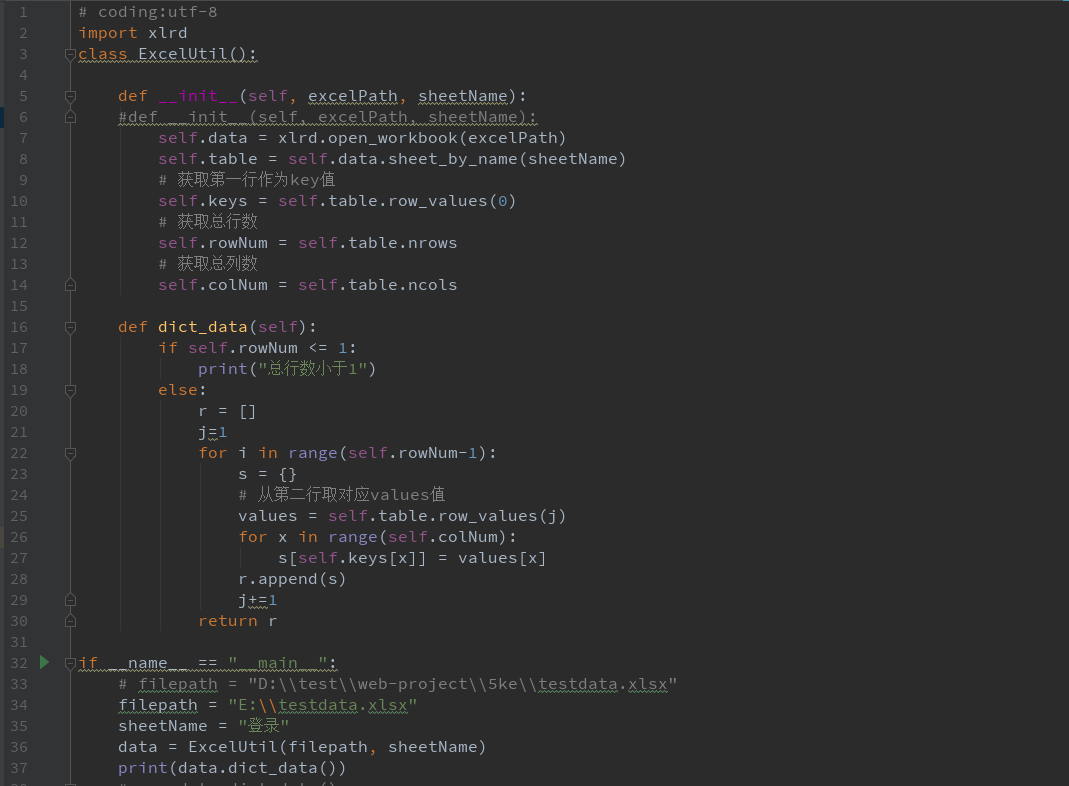
import xlrd
class ExcelUtil():
def __init__(self, excelPath, sheetName):
#def __init__(self, excelPath, sheetName):
self.data = xlrd.open_workbook(excelPath)
self.table = self.data.sheet_by_name(sheetName)
# 获取第一行作为key值
self.keys = self.table.row_values(0)
# 获取总行数
self.rowNum = self.table.nrows
# 获取总列数
self.colNum = self.table.ncols
def dict_data(self):
if self.rowNum <= 1:
print("总行数小于1")
else:
r = []
j=1
for i in range(self.rowNum-1):
s = {}
# 从第二行取对应values值
values = self.table.row_values(j)
for x in range(self.colNum):
s[self.keys[x]] = values[x]
r.append(s)
j+=1
return r
if __name__ == "__main__":
# filepath = "D:\test\web-project\5ke\testdata.xlsx"
filepath = "E:\testdata.xlsx"
sheetName = "登录"
data = ExcelUtil(filepath, sheetName)
print(data.dict_data())