推荐一个可以下线联系SQL的网站(https://sqlbolt.com/),闯关式,适合新手。
一、SELECT
SELECT DISTINCT column, AGG_FUNC(column_or_expression), …
FROM mytable
JOIN another_table
ON mytable.column = another_table.column
WHERE constraint_expression
GROUP BY column
HAVING constraint_expression
ORDER BY column ASC/DESC
LIMIT count OFFSET COUNT;
查询的执行顺序
1、FROM和JOINs
首先执行该FROM子句和后续JOINs,以确定要查询的数据的总工作集。这包括此子句中的子查询,并且可能导致在包含要连接的表的所有列和行的后台创建临时表。
2、WHERE
一旦有了全部的工作数据集,就将首过WHERE约束应用于各个行,不满足约束的行将被丢弃。每个约束只能直接从FROM子句中请求的表中访问列。SELECT在大多数数据库中,查询部分中的别名 无法访问,因为它们可能包含依赖于尚未执行的查询部分的表达式。
3、GROUP BY
WHERE然后,将根据GROUP BY子句中指定列中的公共值对应用约束后的其余行进行分组。分组的结果是,该列中的行数与唯一值的数目一样多。隐式地,这意味着仅在查询中具有聚合函数时才需要使用它。
4、HAVING
如果查询中有一个GROUP BY子句,则该HAVING子句中的约束将应用于已分组的行,丢弃不满足约束的已分组的行。像该WHERE 子句一样,大多数数据库中的此步骤也无法访问别名。
5、SELECT
SELECT最后,查询部分中的所有表达式都会被计算。
6、DISTINCT
在其余的行中,将删除列中标记为的重复值的行DISTINCT。
7、ORDER BY
如果ORDER BY子句指定了顺序,则将按指定的数据以升序或降序对行进行排序。由于SELECT查询部分中的所有表达式均已计算,因此您可以在此子句中引用别名。
8、LIMIT/OFFSET
最后,落入由所指定的范围之外的行LIMIT和OFFSET从查询返回的被丢弃,在离开最后行的集合。
难点总结
HAVING理解
HAVING用于group by 之后对分组后的数据进行过滤
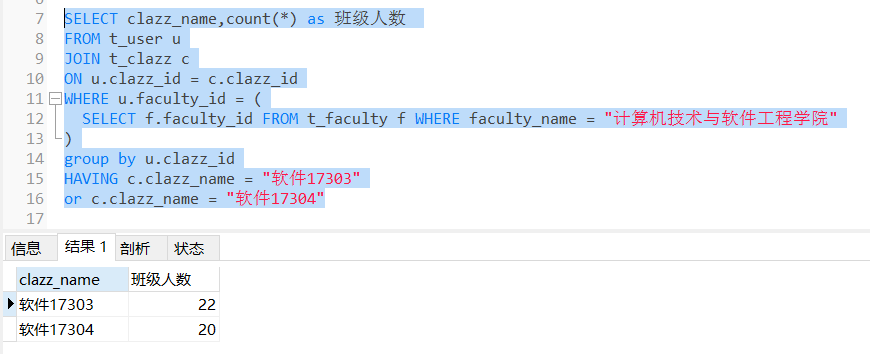
例如:查询计算机学院软件34班的人数
SELECT clazz_name,count(*) as 班级人数
FROM t_user u
JOIN t_clazz c
ON u.clazz_id = c.clazz_id
WHERE u.faculty_id = (
SELECT f.faculty_id FROM t_faculty f WHERE faculty_name = "计算机技术与软件工程学院"
)
group by u.clazz_id
HAVING c.clazz_name = "软件17303"
or c.clazz_name = "软件17304"
JOIN、LEFT JOIN、RIGHT JOIN、FULL JOIN
join(INNER JOIN)是最为常用的取俩表的交集
LEFT JOIN左边表取全集,右表没有匹配的用null替代
RIGHT JOIN右表取全集,左表没有匹配的用null替代
FULL JOIN 两表取全集,左右两边没有匹配的用null替代
详情参考:https://www.cnblogs.com/reaptomorrow-flydream/p/8145610.html