最近做了测试抓取XX时报的数据,由于需要事先登录,并且有验证码,关于验证码解决有两个途径:一是利用打码平台,其原理是把验证码的图片上传发送给打码平台,
然后返回其验证码。二就是自己研究验证码技术问题。这个有时间再研究。
目前主要是测试从XX时报抓取数据,目前暂时用了笨方法,利用人工介入,输入验证码。
登录界面:
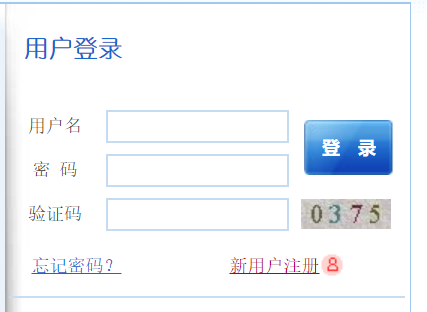
具体代码如下:


#coding=utf-8 import os import re from selenium import webdriver from selenium.webdriver.common.keys import Keys import time from selenium.webdriver.common.action_chains import ActionChains import collections import mongoDbBase import numpy import imagehash from PIL import Image,ImageFile import datetime class finalNews_IE: def __init__(self,strdate,logonUrl,firstUrl,keyword_list,exportPath,codedir): self.iniDriver() self.db = mongoDbBase.mongoDbBase() self.date = strdate self.firstUrl = firstUrl self.logonUrl = logonUrl self.keyword_list = keyword_list self.exportPath = exportPath self.codedir = codedir self.hash_code_dict ={} def iniDriver(self): # 通过配置文件获取IEDriverServer.exe路径 IEDriverServer = "C:Program FilesInternet ExplorerIEDriverServer.exe" os.environ["webdriver.ie.driver"] = IEDriverServer self.driver = webdriver.Ie(IEDriverServer) def WriteData(self, message, fileName): fileName = os.path.join(os.getcwd(), self.exportPath + '/' + fileName) with open(fileName, 'a') as f: f.write(message) # 获取图片文件的hash值 def get_ImageHash(self,imagefile): hash = None if os.path.exists(imagefile): with open(imagefile, 'rb') as fp: hash = imagehash.average_hash(Image.open(fp)) return hash # 点降噪 def clearNoise(self, imageFile, x=0, y=0): if os.path.exists(imageFile): image = Image.open(imageFile) image = image.convert('L') image = numpy.asarray(image) image = (image > 135) * 255 image = Image.fromarray(image).convert('RGB') # save_name = "D:workpython36_crawlVeriycodemode_5590.png" # image.save(save_name) image.save(imageFile) return image #切割验证码 # rownum:切割行数;colnum:切割列数;dstpath:图片文件路径;img_name:要切割的图片文件 def splitimage(self, imagePath,imageFile,rownum=1, colnum=4): img = Image.open(imageFile) w, h = img.size if rownum <= h and colnum <= w: print('Original image info: %sx%s, %s, %s' % (w, h, img.format, img.mode)) print('开始处理图片切割, 请稍候...') s = os.path.split(imageFile) if imagePath == '': dstpath = s[0] fn = s[1].split('.') basename = fn[0] ext = fn[-1] num = 1 rowheight = h // rownum colwidth = w // colnum file_list =[] for r in range(rownum): index = 0 for c in range(colnum): # (left, upper, right, lower) # box = (c * colwidth, r * rowheight, (c + 1) * colwidth, (r + 1) * rowheight) if index < 1: colwid = colwidth + 6 elif index < 2: colwid = colwidth + 1 elif index < 3: colwid = colwidth box = (c * colwid, r * rowheight, (c + 1) * colwid, (r + 1) * rowheight) newfile = os.path.join(imagePath, basename + '_' + str(num) + '.' + ext) file_list.append(newfile) img.crop(box).save(newfile, ext) num = num + 1 index += 1 return file_list def compare_image_with_hash(self, image_hash1,image_hash2, max_dif=5): """ max_dif: 允许最大hash差值, 越小越精确,最小为0 推荐使用 """ dif = image_hash1 - image_hash2 # print(dif) if dif < 0: dif = -dif if dif <= max_dif: return True else: return False # 截取验证码图片 def savePicture(self): # self.driver.get(self.logonUrl) # self.driver.maximize_window() # time.sleep(2) self.driver.save_screenshot(self.codedir +"Temp.png") checkcode = self.driver.find_element_by_id("checkcode") location = checkcode.location # 获取验证码x,y轴坐标 size = checkcode.size # 获取验证码的长宽 rangle = (int(location['x']), int(location['y']), int(location['x'] + size['width']), int(location['y'] + size['height'])) # 写成我们需要截取的位置坐标 i = Image.open(self.codedir +"Temp.png") # 打开截图 result = i.crop(rangle) # 使用Image的crop函数,从截图中再次截取我们需要的区域 filename = datetime.datetime.now().strftime("%M%S") filename =self.codedir +"Temp_code.png" result.save(filename) self.clearNoise(filename) file_list = self.splitimage(self.codedir,filename) time.sleep(3) verycode ='' for f in file_list: imageHash = self.get_ImageHash(f) if imageHash: for h, code in self.hash_code_dict.items(): flag = self.compare_image_with_hash(imageHash, h, 0) if flag: # print(code) verycode += code break print(verycode) return verycode # print(verycode) # self.driver.close() def getVerycode(self, txtFile="verycode.txt"): f = open(txtFile, 'r') result = f.read() return result def longon(self): for f in range(0,10): for l in range(1,5): file = os.path.join(self.codedir, "codeLibrarycode" + str(f) + '_'+str(l) + ".png") # print(file) hash = self.get_ImageHash(file) self.hash_code_dict[hash]= str(f) flag = True try: self.driver.get(self.logonUrl) self.driver.maximize_window() time.sleep(2) verycode = self.savePicture() if len(verycode)==4: accname = self.driver.find_element_by_id("username") # accname = self.driver.find_element_by_id("//input[@id='username']") accname.send_keys('ctrchina') accpwd = self.driver.find_element_by_id("password") # accpwd.send_keys('123456') # code = self.getVerycode() checkcode = self.driver.find_element_by_name("checkcode") checkcode.send_keys(verycode) submit = self.driver.find_element_by_name("button") submit.click() else: flag = False except Exception as e1: message = str(e1.args) flag = False return flag # 获取版面链接及关键字 def saveUrls(self): error = '' while True: flag = self.longon() time.sleep(2) if flag: try: codefault = self.driver.find_element_by_xpath("//table[@class='table_login']/tbody/tr/td/font") if codefault: continue except Exception as e1: pass break try: time.sleep(2) self.driver.get(self.firstUrl) self.driver.maximize_window() # urllb = "//div[@id='pageLink']/ul/div/div/a" urllb = "//a[@id='pageLink']" time.sleep(2) elements = self.driver.find_elements_by_xpath(urllb) url_layout_dict = collections.OrderedDict() for element in elements: layout = element.text # print(layout) if len(layout) == 0: continue # layout = txt[txt.find(":") + 1:] link = element.get_attribute("href") print(link) if link not in url_layout_dict: url_layout_dict[link] = layout index = 0 for sub_url,layout in url_layout_dict.items(): if index==0: sub_url="" print(index) self.getArticleLink(sub_url,layout) index+=1 except Exception as e1: print("saveUrlsException") print("saveUrlsException:Exception" + str(e1.args)) def getArticleLink(self, url,layout): error = '' try: if url: self.driver.get(url) self.driver.maximize_window() time.sleep(2) dt = datetime.datetime.now().strftime("%Y.%m.%d") urllb = "//div[@id='titleList']/ul/li/a" elements = self.driver.find_elements_by_xpath(urllb) url_layout_dict = {} for element in elements: txt = element.text txt = txt[txt.rfind(")") + 1:len(txt)] if txt.find("无标题") > -1 or txt.find("公 告") > -1 or txt.find("FINANCIAL NEWS") > -1 or txt.find(dt) > -1: continue link = element.get_attribute("href") print(link) url_layout_dict[link] = layout self.db.SavefinalUrl(url_layout_dict,self.date) except Exception as e1: print("getArticleLink:Exception") print("getArticleLink:Exception" + str(e1.args)) error = e1.args def catchdata(self): rows = self.db.GetfinalUrl(self.date) lst = [] for row in rows: lst.append(row) print("rowcount:"+str(len(lst))) count =1 for row in lst: url = row['url'] layout = row['layout'] try: self.driver.get(url) self.driver.maximize_window() time.sleep(1) title = "" # t1 = doc("div[class='text_c']") element = self.driver.find_element_by_class_name("text_c") title = element.find_element_by_css_selector("h3").text st = element.find_element_by_css_selector("h1").text if st: title += " " + st st = element.find_element_by_css_selector("h2").text if st: title += " " + st st = element.find_element_by_css_selector("h4").text if st: if st.find("记者") == -1: title += " " + st # else: # author = st.replace("记者","").replace("本报","").strip() elements = self.driver.find_elements_by_xpath("//div[@id='ozoom']/p") content = "" key = "" index = 0 author = '' for element in elements: txt = element.text.strip().replace(" ", "") content += txt if index == 0: if txt.find("记者") > 0 and txt.find("报道") > 0: author = txt[txt.find("记者") + 2:txt.find("报道")] elif txt.find("记者") > 0 and txt.find("报道") == -1: author = txt[txt.find("记者") + 2:len(txt)] elif txt.find("记者") == -1 and txt.find("报道") == -1: author = txt.strip() index += 1 for k in self.keyword_list: if content.find(k)>-1 or title.find(k)>-1: key+=k+"," if key: key = key[0:len(key)-1] author = author.replace("记者", "").strip() if len(author)>6: author = "" print(count) print(layout) print(url) print(title) print(author) count+=1 # print(content) self.db.updatefinalUrl(url) self.db.SavefinalData(self.date,layout,url,title,author,key,content) except Exception as e1: error = e1.args self.driver.close() def export(self): rows = self.db.GetfinalData(self.date) lst = [] for dataRow1 in rows: lst.append(dataRow1) count =1 # dt = datetime.datetime.now().strftime("%Y-%m-%d") fileName = '金融时报_' + self.date + '.csv' header = "发表日期,关键字,作者,全文字数,标题,版面,链接,正文" if len(lst)>0: self.WriteData(header, fileName) for dataRow in lst: date = str(dataRow['date']) layout = str(dataRow['layout']) url = str(dataRow['url']) title = str(dataRow['title']).replace(",",",").replace(" "," ") author = str(dataRow['author']).replace(",",",") key = str(dataRow['key']).replace(",",",") wordcount = str(dataRow['wordcount']) content = str(dataRow['content']).replace(",",",").replace(" "," ") # txt = " %s,%s,%s,%s,%s,%s" % ( # date, key, title, author, wordcount, url) txt = " %s,%s,%s,%s,%s,%s,%s,%s" % ( date, key, author, wordcount, title,layout, url, content) try: self.WriteData(txt, fileName) except Exception as e1: print(str(e1)) print(count) count += 1 # # dt = datetime.datetime.now().strftime("%Y-%m-%d") # ym = datetime.datetime.now().strftime("%Y-%m") # day = datetime.datetime.now().strftime("%d") # # codepath='E:/python36_crawl/mediaInfo/verycode.txt' # # logonUrl="http://epaper.financialnews.com.cn/dnis/client/jrsb/index.jsp" # # firsturl="http://epaper.financialnews.com.cn/jrsb/html/2018-09/18/node_2.htm" # firsturl="http://epaper.financialnews.com.cn/jrsb/html/"+ym+"/"+day+"/node_2.htm" # # print(firsturl) # keyword_list ="银保监会,央行,中国银行,中行,中银".split(",") # exportPath="E:/News" # codedir='E:python36_crawlVeriycode' # obj = finalNews_IE(dt,logonUrl,firsturl,keyword_list,exportPath,codedir) # # obj.saveUrls() # obj.catchdata() # obj.export() # # obj.savePicture()
采集时报2
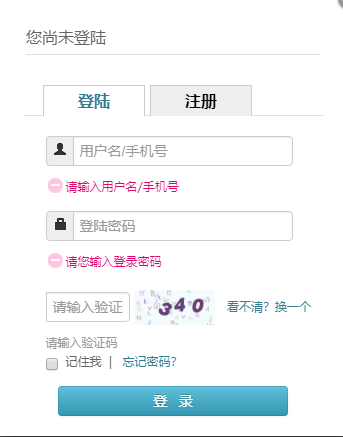

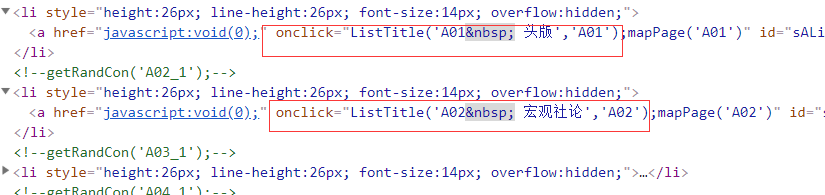
layoutElement.get_attribute("onclick")
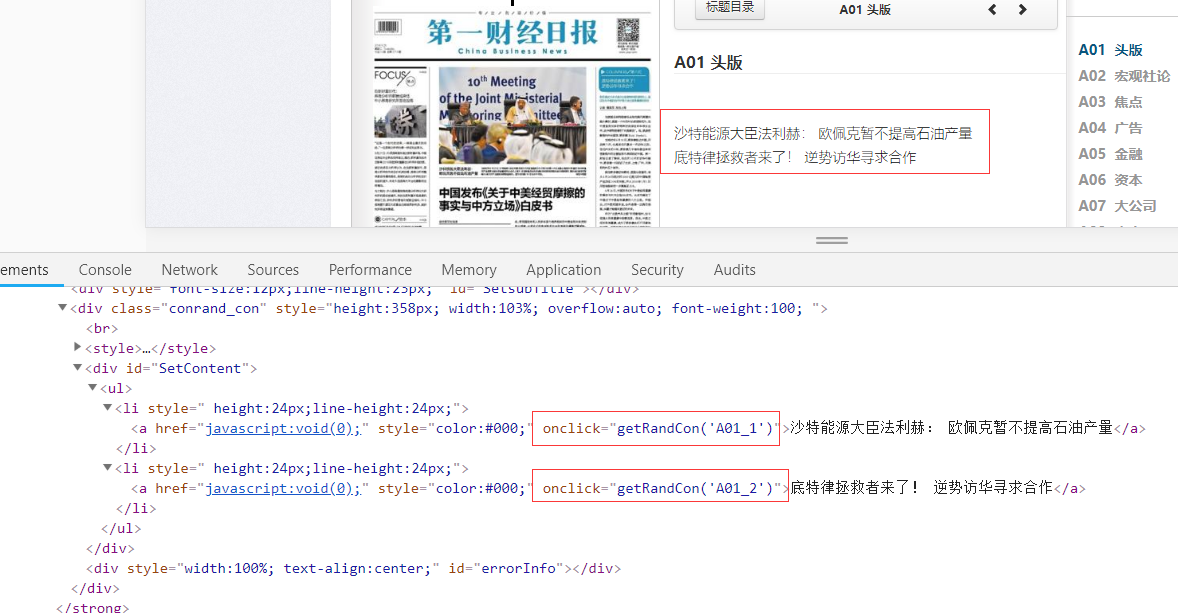
layoutLink = layoutElement.get_attribute("onclick")
#coding=utf-8 import os import re from selenium import webdriver from selenium.webdriver.common.keys import Keys import time from selenium.webdriver.common.action_chains import ActionChains import collections import mongoDbBase import datetime import numpy from PIL import Image import RClient class firstfinal: def __init__(self, strdate, firstUrl, keyword_list, exportPath,dirpath): self.db = mongoDbBase.mongoDbBase() self.date = strdate self.firstUrl = firstUrl self.keyword_list = keyword_list self.exportPath = exportPath self.dirpath = dirpath self.rclient = RClient.RClient() def iniDriver(self): # 通过配置文件获取IEDriverServer.exe路径 IEDriverServer = "C:Program Filesinternet explorerIEDriverServer.exe" os.environ["webdriver.ie.driver"] = IEDriverServer self.driver = webdriver.Ie(IEDriverServer) def WriteData(self, message, fileName): fileName = os.path.join(os.getcwd(), self.exportPath + '/' + fileName) with open(fileName, 'a') as f: f.write(message) def getVerycode(self, txtFile="verycode.txt"): f = open(txtFile, 'r') result = f.read() return result # 点降噪 def clearNoise(self, imageFile, x=0, y=0): if os.path.exists(imageFile): image = Image.open(imageFile) image = image.convert('L') image = numpy.asarray(image) image = (image > 135) * 255 image = Image.fromarray(image).convert('RGB') # save_name = "D:workpython36_crawlVeriycodemode_5590.png" # image.save(save_name) image.save(imageFile) return image def savePicture(self): # self.iniDriver() # self.driver.get(self.firstUrl) # self.driver.maximize_window() logon = self.driver.find_element_by_xpath("//div[@class='topMenu']/div[2]/a") # 索引从1开始 # href = logon.get_attribute("href") # self.driver.execute_script(href) logon.click() # self.driver.maximize_window() time.sleep(2) checkcode = self.driver.find_element_by_id("Verify") temppng = "E:python36_crawlVeriycodeTemp.png" self.driver.save_screenshot("E:python36_crawlVeriycodeTemp.png") location = checkcode.location # 获取验证码x,y轴坐标 size = checkcode.size # 获取验证码的长宽 rangle = (int(location['x']), int(location['y']), int(location['x'] + size['width']), int(location['y'] + size['height'])) # 写成我们需要截取的位置坐标 # i = Image.open("D:workpython36_crawlVeriycodecodeTemp.png") # 打开截图 i = Image.open(temppng) result = i.crop(rangle) # 使用Image的crop函数,从截图中再次截取我们需要的区域 # imagefile = datetime.datetime.now().strftime("%Y%m%d%H%M%S")+".png" # imagefile = os.path.join("D:workpython36_crawlVeriycodecode",imagefile) result.save(temppng) # self.driver.close() # time.sleep(2) return temppng def longon(self): self.iniDriver() self.driver.get(self.firstUrl) self.driver.maximize_window() logon = self.driver.find_element_by_xpath("//div[@class='topMenu']/div[2]/a")#索引从1开始 # href = logon.get_attribute("href") # self.driver.execute_script(href) logon.click() self.driver.maximize_window() time.sleep(2) # if os.path.exists(self.codepath): # os.system(self.codepath) # code = self.getVerycode() accname = self.driver.find_element_by_name("username") # accname = self.driver.find_element_by_id("//input[@id='username']") accname.send_keys('ctrchina') # time.sleep(15) accpwd = self.driver.find_element_by_name("password") # 在服务器上浏览器记录密码了,就不需要设置了 accpwd.send_keys('123456') checkcode = self.driver.find_element_by_name("code") temppng = self.savePicture() code = self.rclient.test(temppng) checkcode.send_keys(code) submit = self.driver.find_element_by_xpath("//div[@class='UserFrom']/div[8]/button") submit.click() time.sleep(4) # self.driver.refresh() # 获取版面链接及关键字 def catchData(self): flag = True try: layoutlb = "//ul[@class='BNameList']/li/a" artclelb = "//div[@id='SetContent']/ul/li/a" contentlb = "//div[@id='SetContent']/ul/li/a" layoutElements = self.driver.find_elements_by_xpath(layoutlb) layoutCount = len(layoutElements) layoutIndex = 0 layout = '' # 版面循环 print("layoutCount="+str(layoutCount)) while layoutIndex<layoutCount: if layoutIndex >0: self.driver.get(self.firstUrl) self.driver.maximize_window() layoutElements = self.driver.find_elements_by_xpath(layoutlb) layoutElement = layoutElements[layoutIndex] layoutLink = layoutElement.get_attribute("onclick") self.driver.execute_script(layoutLink) else: layoutElement = layoutElements[layoutIndex] layout = layoutElement.text print(layout) articleElements = self.driver.find_elements_by_xpath(artclelb) articleCount = len(articleElements) print("articleCount=" + str(articleCount)) articleIndex = 0 # 每个版面中文章列表循环 while articleIndex < articleCount: if articleIndex > 0 : self.driver.get(self.firstUrl) self.driver.maximize_window() layoutElements = self.driver.find_elements_by_xpath(layoutlb) layoutElement = layoutElements[layoutIndex] layoutLink = layoutElement.get_attribute("onclick") self.driver.execute_script(layoutLink) elements = self.driver.find_elements_by_xpath(contentlb) sublink = elements[articleIndex].get_attribute("onclick") # title = elements[articleIndex].text print(title) self.driver.execute_script(sublink) author = self.driver.find_element_by_id("Setauthor").text subE = self.driver.find_elements_by_xpath("//div[@id='SetContent']/p") content = '' for se in subE: content += se.text key = '' for k in self.keyword_list: if content.find(k) > -1 or title.find(k) > -1: key += k + "," if key: key = key[0:len(key) - 1] print(author) # print(content) print(key) print(' ') articleIndex += 1 self.db.SaveFirsFinalData(self.date, layout, self.firstUrl, title, author, key, content) layoutIndex+=1 except Exception as e1: error = e1.args flag = True def export(self): try: rows = self.db.GetFirsFinalData(self.date) lst = [] for dataRow1 in rows: lst.append(dataRow1) count = 1 dt = datetime.datetime.now().strftime("%Y-%m-%d") fileName = '第一财经日报_' + self.date + '.csv' header = "发表日期,关键字,作者,全文字数,标题,版面,链接,正文" if len(lst)>0: self.WriteData(header, fileName) # 所有的文章链接都是一样的 url = 'http://buy.yicai.com/read/index/id/5.html' for dataRow in lst: date = str(dataRow['date']) layout = str(dataRow['layout']) # url = str(dataRow['url']) title = str(dataRow['title']).replace(",", ",").replace(" ", " ") author = str(dataRow['author']).replace(",", ",") key = str(dataRow['key']).replace(",", ",") wordcount = str(dataRow['wordcount']) content = str(dataRow['content']).replace(",", ",").replace(" ", " ") # txt = " %s,%s,%s,%s,%s,%s" % ( # date, key, title, author, wordcount, url) txt = " %s,%s,%s,%s,%s,%s,%s,%s" % ( date, key, author, wordcount, title, layout, url, content) try: self.WriteData(txt, fileName) except Exception as e1: print(str(e1)) print(count) count += 1 except Exception as e1: error = e1.args def test(self): dt = datetime.datetime.now().strftime("%Y-%m-%d") # dt="2018-10-08" dirpath = "E:python36_crawl" # codepath= os.path.join(dirpath,"mediaInfoVerycode.txt") # codepath='E:/python36_crawl/mediaInfo/verycode.txt' # file_list = os.listdir("D:workpython36_crawlVeriycodecode") # firsturl="http://buy.yicai.com/read/index/id/5.html" firsturl = 'http://buy.yicai.com/read/index/id/5.html' keyword_list = "银保监会,央行,中国银行,中行,中银".split(",") exportPath = "E:/News" obj = firstfinal(dt, firsturl, keyword_list, exportPath, dirpath) obj.longon() obj.catchData() obj.export() # dt = datetime.datetime.now().strftime("%Y-%m-%d") # # dt="2018-10-08" # dirpath ="E:python36_crawl" # # codepath= os.path.join(dirpath,"mediaInfoVerycode.txt") # # codepath='E:/python36_crawl/mediaInfo/verycode.txt' # # file_list = os.listdir("D:workpython36_crawlVeriycodecode") # # firsturl="http://buy.yicai.com/read/index/id/5.html" # firsturl='http://buy.yicai.com/read/index/id/5.html' # keyword_list = "银保监会,央行,中国银行,中行,中银".split(",") # exportPath = "E:/News" # obj = firstfinal(dt, firsturl, keyword_list, exportPath,dirpath) # obj.longon() # obj.catchData() # # while True: # # obj.savePicture() # obj.export()
# coding=utf-8 import datetime import finalNews_IE import firstfinal import Mail import time import os # def WriteData(message, fileName): # fileName = os.path.join(os.getcwd(), 'mailflag.txt') # with open(fileName) as f: # f.write(message) def run(): attachmentFileDir ="E:\News" mailflagfile = os.path.join(os.getcwd(), 'mailflag.txt') while True: date = datetime.datetime.now() strtime = datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S") print(strtime + " 正常循环") dt = datetime.datetime.now().strftime("%Y-%m-%d") ym = datetime.datetime.now().strftime("%Y-%m") day = datetime.datetime.now().strftime("%d") fileName = '金融时报_' + dt + '.csv' fileName = os.path.join(attachmentFileDir, fileName) firstfileName = '第一财经日报_' + dt + '.csv' firstfileName = os.path.join(attachmentFileDir, firstfileName) if not os.path.exists(fileName): # 采集金融时报数据 logonUrl = "http://epaper.financialnews.com.cn/dnis/client/jrsb/index.jsp" # firsturl="http://epaper.financialnews.com.cn/jrsb/html/2018-09/18/node_2.htm" firsturl = "http://epaper.financialnews.com.cn/jrsb/html/" + ym + "/" + day + "/node_2.htm" # print(firsturl) keyword_list = "银保监会,央行,中国银行,中行,中银".split(",") exportPath = "E:/News" codedir = 'E:python36_crawlVeriycode' obj = finalNews_IE.finalNews_IE(dt, logonUrl, firsturl, keyword_list, exportPath, codedir) obj.saveUrls() obj.catchdata() obj.export() if not os.path.exists(firstfileName): # 采集第一采集日报数据 dirpath = "E:python36_crawl" firsturl = 'http://buy.yicai.com/read/index/id/5.html' keyword_list = "银保监会,央行,中国银行,中行,中银".split(",") exportPath = "E:/News" obj = firstfinal.firstfinal(dt, firsturl, keyword_list, exportPath, dirpath) obj.longon() obj.catchData() obj.export() if date.strftime('%H:%M')=="08:50": # 发送邮件 obj = Mail.Mail() obj.test() # WriteData(dt,mailflagfile) time.sleep(100) else: time.sleep(10) run() # try: # dt = datetime.datetime.now().strftime("%Y-%m-%d") # ym = datetime.datetime.now().strftime("%Y-%m") # day = datetime.datetime.now().strftime("%d") # # 采集金融时报数据 # logonUrl = "http://epaper.financialnews.com.cn/dnis/client/jrsb/index.jsp" # # firsturl="http://epaper.financialnews.com.cn/jrsb/html/2018-09/18/node_2.htm" # firsturl = "http://epaper.financialnews.com.cn/jrsb/html/" + ym + "/" + day + "/node_2.htm" # # print(firsturl) # keyword_list = "银保监会,央行,中国银行,中行,中银".split(",") # exportPath = "E:/News" # codedir = 'E:python36_crawlVeriycode' # obj = finalNews_IE.finalNews_IE(dt, logonUrl, firsturl, keyword_list, exportPath, codedir) # obj.saveUrls() # obj.catchdata() # obj.export() # # # 采集第一采集日报数据 # dirpath = "E:python36_crawl" # firsturl = 'http://buy.yicai.com/read/index/id/5.html' # keyword_list = "银保监会,央行,中国银行,中行,中银".split(",") # exportPath = "E:/News" # obj = firstfinal.firstfinal(dt, firsturl, keyword_list, exportPath, dirpath) # obj.longon() # obj.catchData() # obj.export() # 发送邮件 # obj = Mail.Mail() # obj.test() # except Exception as e1: # print(str(e1))