今天在使用Selenuim+PhantomJS动态抓取网页时,出现如下报错信息:
C:Python36libsite-packagesselenium-3.11.0-py3.6.eggseleniumwebdriverphantomjswebdriver.py:49: UserWarning: Selenium support for PhantomJS has been deprecated, please use headless versions of Chrome or Firefox instead warnings.warn('Selenium support for PhantomJS has been deprecated, please use headless '
意思就是Selenuim已经放弃PhantomJS,了,建议使用火狐或者谷歌无界面浏览器。

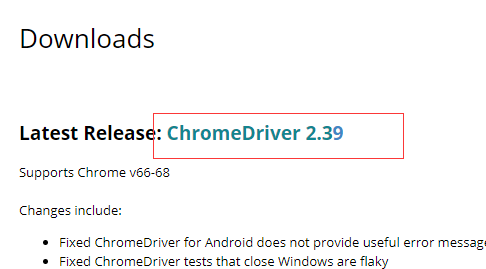
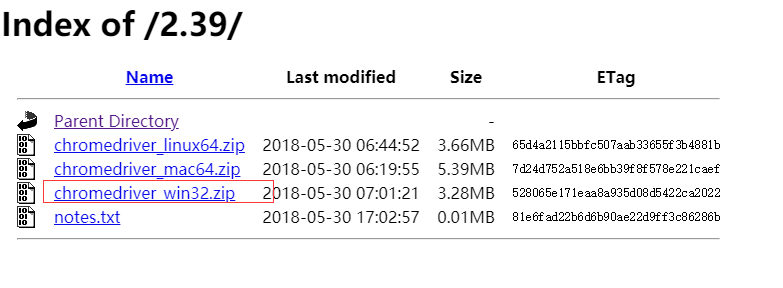
要确保机器上安装谷歌浏览器
把chromedriver.exe放在C:Python27Scripts路径下
Chrome-headless 模式, Google 针对 Chrome 浏览器 59版 新增加的一种模式,可以让你不打开UI界面的情况下使用 Chrome 浏览器,所以运行效果与 Chrome 保持完美一致。
火狐驱动:https://github.com/mozilla/geckodriver/releases
https://github.com/mozilla/geckodriver/releases/download/v0.19.1/geckodriver-v0.19.1-linux64.tar.gz
Geckodriver版本与Firefox版本映射关系
https://blog.csdn.net/u013250071/article/details/78803230
下载驱动后,可以放在python27/scrpts目录下,也可以放在某个目录,设置在环境变量path里面
具体实现代码:
chrome_options = Options()
#Chrome-headless 模式, Google 针对 Chrome 浏览器 59版 新增加的一种模式,可以让你不打开UI界面的情况下使用 Chrome 浏览器,所以运行效果与 Chrome 保持完美一致。 chrome_options.add_argument('--headless') chrome_options.add_argument('--disable-gpu') self.driver = webdriver.Chrome(chrome_options=chrome_options) self.driver.set_page_load_timeout(10) self.driver.maximize_window()
其它使用同 phantomjs 一样
完整python代码


# coding=utf-8 import os import re from selenium import webdriver from selenium.webdriver.chrome.options import Options from datetime import datetime,timedelta import time from pyquery import PyQuery as pq import re import datetime class consumer: def __init__(self): #通过配置文件获取IEDriverServer.exe路径 # IEDriverServer ='C:Program FilesInternet ExplorerIEDriverServer.exe' # self.driver = webdriver.Ie(IEDriverServer) # self.driver.maximize_window() # self.driver = webdriver.PhantomJS(service_args=['--load-images=false']) # self.driver = driver = webdriver.Chrome() # chrome_options = Options() # chrome_options.add_argument('--headless') # chrome_options.add_argument('--disable-gpu') # self.driver = webdriver.Chrome(chrome_options=chrome_options) options = webdriver.FirefoxOptions() options.set_headless() # options.add_argument('-headless') options.add_argument('--disable-gpu') self.driver = webdriver.Firefox(firefox_options=options) self.driver.set_page_load_timeout(10) self.driver.maximize_window() def WriteLog(self, message,date): fileName = os.path.join(os.getcwd(), 'consumer/' + date + '.txt') with open(fileName, 'a') as f: f.write(message) # http://search.cctv.com/search.php?qtext=消费主张&type=video def CatchData(self,url='http://search.cctv.com/search.php?qtext=%E6%B6%88%E8%B4%B9%E4%B8%BB%E5%BC%A0&type=video'): error = '' try: self.driver.get(url) selenium_html = self.driver.execute_script("return document.documentElement.outerHTML") doc = pq(selenium_html) filename = datetime.datetime.now().strftime('%Y-%m-%d') message = '{0},{1}'.format( '标题', '时间') filename = datetime.datetime.now().strftime('%Y-%m-%d') self.WriteLog(message, filename) pages = doc("div[class='page']").find("a") # 2018-06-05 00:12:21 pattern = re.compile("d{4}-d{2}-d{2}sd{2}:d{2}:d{2}") for index in range(1,6): url = "get_data('{0}', '消费主张', 'relevance', 'video', '-1', '1', '', '20', '1')".format(index) self.driver.execute_script(url) selenium_html = self.driver.execute_script("return document.documentElement.outerHTML") doc = pq(selenium_html) print(index) try: Elements = doc("div[class='jvedio']").find("a") for sub in Elements.items(): title = sub.attr('title') print(title) ts = pattern.findall(title) strtime = '' if ts and len(ts) == 1: strtime = ts[0] if strtime: index1 = title.index(strtime) title = str(title[0:index1]).replace("•","") title = ' {0},{1}'.format(title, strtime) self.WriteLog(title, filename) except Exception as e: print("OS error: {0}".format(e)) except Exception as e1: error = "ex" # python "C:Program Files (x86)JetBrainsPyCharm 2016.2.3helperspydevsetup_cython.py" build_ext --inplace obj = consumer() obj.CatchData() # obj.CatchContent('') # obj.export('')