1、介绍
集群健康 就像是光谱的一端——对集群的所有信息进行高度概述。 而 节点统计值 API 则是在另一端。它提供一个让人眼花缭乱的统计数据的数组,包含集群的每一个节点统计值。
节点统计值 提供的统计值如此之多,在完全熟悉它之前,你可能都搞不清楚哪些指标是最值得关注的。我们将会高亮那些最重要的监控指标(但是我们鼓励你记录接口提供的所有指标——
或者用 Marvel ——因为你永远不知道何时需要某个或者另一个值)。
2、节点统计值命令
GET _nodes/stats
3、结果介绍
1、开头部分
在输出内容的开头,我们可以看到集群名称和我们的第一个节点:
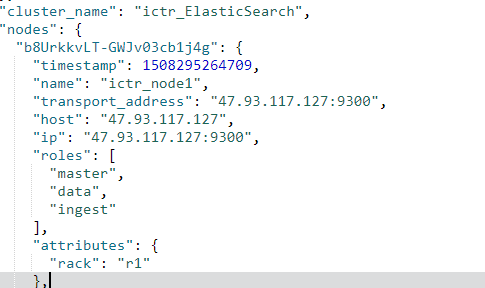
节点是排列在一个哈希里,以节点的 UUID 作为键名。还显示了节点网络属性的一些信息(比如传输层地址和主机名)。这些值对调试诸如节点未加入集群这类自动发现问题很有用。
通常你会发现是端口用错了,或者节点绑定在错误的 IP 地址/网络接口上了。
2、索引部分
索引(indices) 部分列出了这个节点上所有索引的聚合过的统计值 :
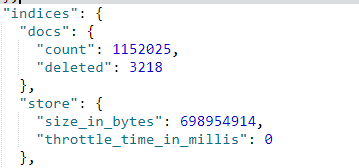
返回的统计值被归入以下部分:
docs 展示节点内存有多少文档,包括还没有从段里清除的已删除文档数量。
store 部分显示节点耗用了多少物理存储。这个指标包括主分片和副本分片在内。如果限流时间很大,那可能表明你的磁盘限流设置得过低(在段和合并里讨论过)。
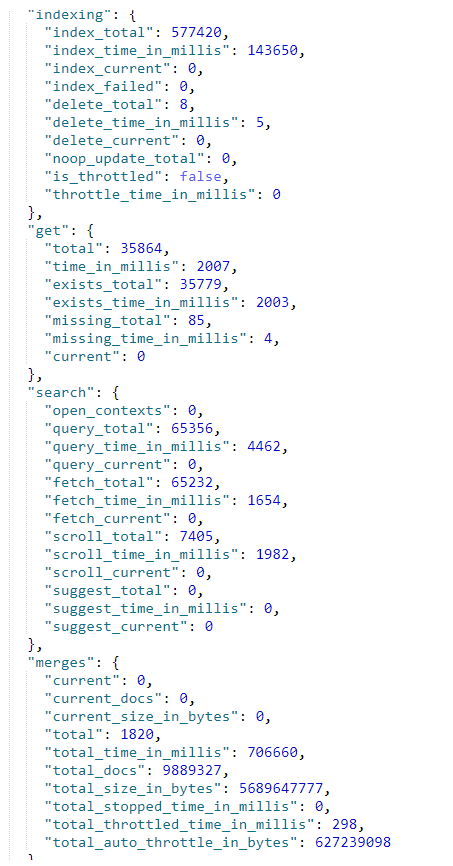
1、 indexing 显示已经索引了多少文档。这个值是一个累加计数器。在文档被删除的时候,数值不会下降。还要注意的是,在发生内部 索引 操作的时候,这个值也会增加,比如说文档更新。
还列出了索引操作耗费的时间,正在索引的文档数量,以及删除操作的类似统计值。
2、get 显示通过 ID 获取文档的接口相关的统计值。包括对单个文档的 GET 和 HEAD 请求。
3、search 描述在活跃中的搜索( open_contexts )数量、查询的总数量、以及自节点启动以来在查询上消耗的总时间。用 query_time_in_millis / query_total 计算的比值,
可以用来粗略的评价你的查询有多高效。比值越大,每个查询花费的时间越多,你应该要考虑调优了。fetch 统计值展示了查询处理的后一半流程(query-then-fetch 里的 fetch )。
如果 fetch 耗时比 query 还多,说明磁盘较慢,或者获取了太多文档,或者可能搜索请求设置了太大的分页(比如, size: 10000 )。
4、merges 包括了 Lucene 段合并相关的信息。它会告诉你目前在运行几个合并,合并涉及的文档数量,正在合并的段的总大小,以及在合并操作上消耗的总时间。
在你的集群写入压力很大时,合并统计值非常重要。合并要消耗大量的磁盘 I/O 和 CPU 资源。如果你的索引有大量的写入,同时又发现大量的合并数,一定要去阅读索引性能技巧。
注意:文档更新和删除也会导致大量的合并数,因为它们会产生最终需要被合并的段 碎片 。