一、介绍
本例子用Selenium +phantomjs 利用 pyquery通过搜狗搜索引擎数据()的资讯信息,输入给定关键字抓取资讯信息。
给定关键字:数字;融合;电视
抓取信息内如下:
1、资讯标题
2、资讯链接
3、资讯时间
4、资讯来源
二、网站信息
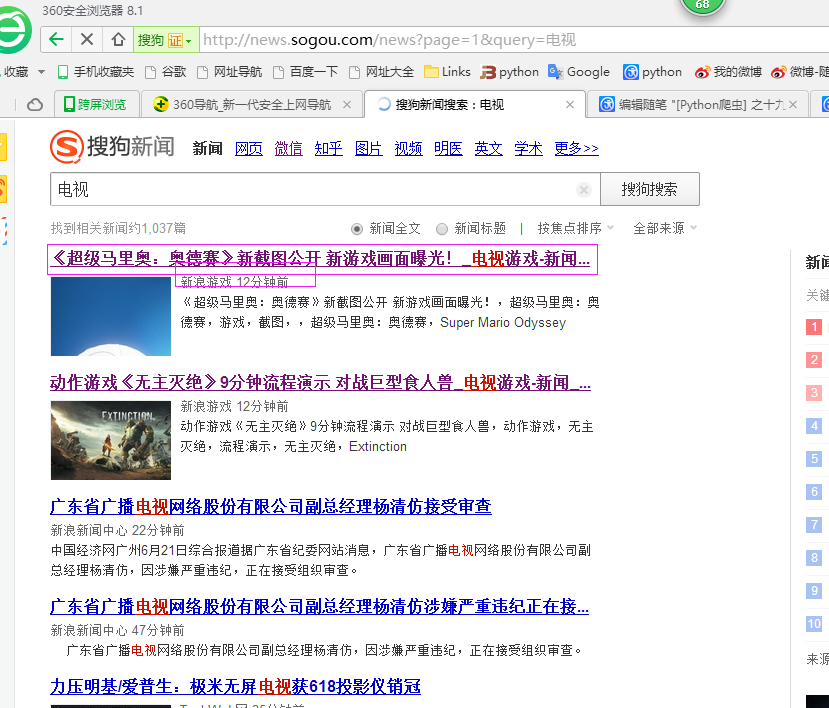

三、数据抓取
针对上面的网站信息,来进行抓取
1、首先抓取信息列表
抓取代码:Elements = doc('div[class="news151102"]')
2、抓取标题
抓取代码:title = element('h3[class="vrTitle"]').find('a').text().encode('utf8').strip()
3、抓取链接
抓取代码:url = element('h3[class="vrTitle"]').find('a').attr('href')
4、抓取日期
抓取代码:strdate = element('p[class="news-from"]').text().encode('utf8').strip()
5、抓取来源
抓取代码:strSources = dochtml('span[class="wzof"]').text().encode('utf8').strip().split(':')
四、完整代码
# coding=utf-8 import os import re from selenium import webdriver import selenium.webdriver.support.ui as ui import time from datetime import datetime import IniFile # from threading import Thread from pyquery import PyQuery as pq import LogFile import mongoDB import urllib class sogouSpider(object): def __init__(self): logfile = os.path.join(os.path.dirname(os.getcwd()), time.strftime('%Y-%m-%d') + '.txt') self.log = LogFile.LogFile(logfile) configfile = os.path.join(os.path.dirname(os.getcwd()), 'setting.conf') cf = IniFile.ConfigFile(configfile) self.webSearchUrl_list = cf.GetValue("sogou", "webSearchUrl").split(';') self.keyword_list = cf.GetValue("section", "information_keywords").split(';') self.db = mongoDB.mongoDbBase() self.start_urls = [] for word in self.keyword_list: keyword = urllib.quote(word) for url in self.webSearchUrl_list: self.start_urls.append(url + keyword) self.driver = webdriver.PhantomJS() self.wait = ui.WebDriverWait(self.driver, 2) self.driver.maximize_window() def Comapre_to_days(self,leftdate, rightdate): ''' 比较连个字符串日期,左边日期大于右边日期多少天 :param leftdate: 格式:2017-04-15 :param rightdate: 格式:2017-04-15 :return: 天数 ''' l_time = time.mktime(time.strptime(leftdate, '%Y-%m-%d')) r_time = time.mktime(time.strptime(rightdate, '%Y-%m-%d')) result = int(l_time - r_time) / 86400 return result def date_isValid(self, strDateText): ''' 判断日期时间字符串是否合法:如果给定时间大于当前时间是合法,或者说当前时间给定的范围内 :param strDateText: 四种格式 '慧聪网 7小时前'; '新浪游戏 29分钟前' ; '中国行业研究网 2017-6-13' :return: True:合法;False:不合法 ''' currentDate = time.strftime('%Y-%m-%d') source = strDateText.split(' ')[0] if strDateText.find('分钟前') > 0: return True, source, currentDate elif strDateText.find('小时前') > 0: datePattern = re.compile(r'd{1,2}') ch = int(time.strftime('%H')) # 当前小时数 strDate = re.findall(datePattern, strDateText) if len(strDate) == 1: if int(strDate[0]) <= ch: # 只有小于当前小时数,才认为是今天 return True, source, currentDate else: datePattern = re.compile(r'd{4}-d{1,2}-d{1,2}') strDate = re.findall(datePattern, strDateText) if len(strDate) == 1: if self.Comapre_to_days(currentDate, strDate[0]) == 0: return True, source, currentDate return False, '', '' def log_print(self, msg): ''' # 日志函数 # :param msg: 日志信息 # :return: # ''' print '%s: %s' % (time.strftime('%Y-%m-%d %H-%M-%S'), msg) def scrapy_date(self): strsplit = '------------------------------------------------------------------------------------' for link in self.start_urls: self.driver.get(link) selenium_html = self.driver.execute_script("return document.documentElement.outerHTML") doc = pq(selenium_html) infoList = [] self.log.WriteLog(strsplit) self.log_print(strsplit) Elements = doc('div[class="news151102"]') for element in Elements.items(): strdate = element('p[class="news-from"]').text().encode('utf8').strip() flag, source, date = self.date_isValid(strdate) if flag: title = element('h3[class="vrTitle"]').find('a').text().encode('utf8').strip() for keyword in self.keyword_list: if title.find(keyword) > -1: url = element('h3[class="vrTitle"]').find('a').attr('href') dictM = {'title': title, 'date': date, 'url': url, 'keyword': keyword, 'introduction': title, 'source': source} infoList.append(dictM) self.log.WriteLog('title:%s' % title) self.log.WriteLog('url:%s' % url) self.log.WriteLog('source:%s' % source) self.log.WriteLog('kword:%s' % keyword) self.log.WriteLog(strsplit) self.log_print('title:%s' % dictM['title']) self.log_print('url:%s' % dictM['url']) self.log_print('date:%s' % dictM['date']) self.log_print('source:%s' % dictM['source']) self.log_print('kword:%s' % dictM['keyword']) self.log_print(strsplit) break if len(infoList)>0: self.db.SaveInformations(infoList) self.driver.close() self.driver.quit() obj = sogouSpider() obj.scrapy_date()