在我之前的文章中:《高效排序之——堆排序,归并排序、快速排序》中初步介绍了堆排序的过程,但是认真的说,自己并没有叙述的十分清楚,这篇博客,我将持续更新,表明堆排序的一个过程和核心思想。
系列博客将按照下面三个问题展开:
- 什么是堆?
- 为何堆结构可以用来排序?
- 怎么利用堆结构进行排序?
- 堆排序的算法性能如何?
- 总结堆的特性
本文将先回答前两个问题:
- 什么是堆结构?
堆结构是一棵完全二叉树,这是堆结构最为根本的性质;当然,我们通常会讨论最大堆结构和最小堆结构。这里以最大堆结构为例,说明最大堆的特点: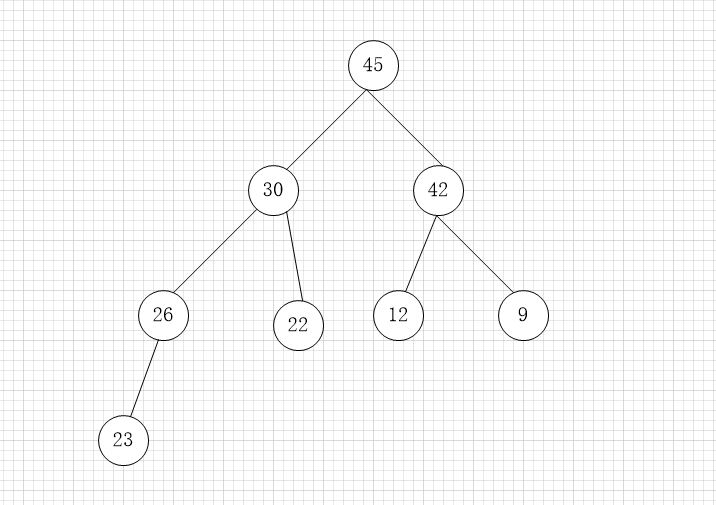
上图所示为一个最大堆结构,很明显需要满足以下两点:1 必须满足堆结构的定义:完全二叉树;2 任何一个子节点的值都不大于其父节点的值
第一个问题回答完毕,再来回答第二个问题:为何堆结构可以用来排序?
那么这个问题就要说到优先队列事情了。队列结构——先进先出,而优先队列呢,满足优先级别高的先出。等等,这和堆结构有何关系呢?,
我们来看看上述最大堆结构:最大堆结构 和优先队列联系起来的 纽带是:越上层的父节点,其优先级越高,我们将上述最大堆直接写成一个数组结构:
 如果把该数组看成队列结构,那么优先出队列的则是元素“45”。最大堆的性质导致了堆的一个很重要的特性:根节点是堆里面数值最大的元素。所以,当元素45出堆后,剩下的元素中最大的元素必然要上浮到根节点的位置。因此,根据堆结构的这一出堆的性质,将一个堆结构所有元素全部出堆,就构成了一个有序列,即完成了排序的功能。
如果把该数组看成队列结构,那么优先出队列的则是元素“45”。最大堆的性质导致了堆的一个很重要的特性:根节点是堆里面数值最大的元素。所以,当元素45出堆后,剩下的元素中最大的元素必然要上浮到根节点的位置。因此,根据堆结构的这一出堆的性质,将一个堆结构所有元素全部出堆,就构成了一个有序列,即完成了排序的功能。
因此堆排序的核心其实是两步:将待排序数组构建为一个堆结构;2 将根节点出堆
仔细思考上面的两个步骤,本质上是两个相反的过程:将n个元素插入一个空堆;将这n个元素按照出堆原则出堆
在此,给出两个基本结论:将n个元素逐个插入到一个空堆中,算法复杂度是O(nlogn)。当然也可以采用heapify算法,将建堆过程的复杂度降低到O(n),该算法的核心思想是:直接对原数组进行结构调整,而且我们开始调整的位置从n/2-1.
至此,博客回答了前两个问题,后续问题会定期更新!