Scala数据结构
主要的集合特质
Scala同时支持可变集合和不可变集合,优先采用不可变集合。集合主要分为三大类:序列(List),集(set),映射(map)。所有的集合都扩展自Iterable特质。对几乎所有的集合类,Scala都同时提供了可变和不可变版本。
- Seq是一个有先后次序的值的序列。IndexedSeq能够通过整形下表快速访问
- Set是一个没有先后顺序的集合。
- Map是一组键值对偶,SortedMap按照键的排序访问其中的实体。
数组
定长数组
val nums = new Array[Int](10)
变长数组
var b = ArrayBuffer[Int]()
Array与ArrayBuffer的互转
ArrayBuffer = Array.toBuffer
Array = ArrayBuffer.toArray
//遍历数组
for (i <- nums) println(i)
for (i <- 0 to nums.length - 1) println(nums(i))
for (i <- 0 until nums.length) println(nums(i))
数组转换
转换动作不会修改原数组,而是产生一个新的数组
多维数组
和java一样,多维数组通过数组的数组来实现,可以使用ofDim方法实现
val array = Array.ofDim[Int](2, 3)
//赋值
array(0)(0)=10
array(0)(1)=11
array(0)(2)=12
array(1)(0)=20
array(1)(1)=21
array(1)(2)=22
//遍历
for (i <- array; j <- i) println(j)
和java数组的互操作
Scala数组是通过java进行实现的,所以可以进行互相转换操作,使用AsJavaConverters 或者 AsScalaConverters 进行转换
import scala.collection.mutable.ArrayBuffer
import scala.collection.JavaConverters._
val a = ArrayBuffer("hello", "world")
//转为Java对象 b.command()可以调用java的方法
val b = new ProcessBuilder(a.asJava)
//转为Scala
val sb = b.command().asScala
映射
映射就是KV的集合,类似于Java中的Map
映射操作
import scala.collection.mutable
//不可变的构造映射
val map = Map("name" -> "upuptop", "age" -> 10)
//可变映射
val map2 = scala.collection.mutable.Map("name" -> "upuptop", "age" -> 10)
//空映射
val map3 = new mutable.HashMap[String, Int]()
//对偶
"name" -> "upuptop"
//对偶元组
var map4 = Map(("name" -> "upuptop"), ("age" -> 10))
//获取值
println(map("name"))
//遍历值
for (i <- map) println(i)
//同时遍历键值对
for ((k, v) <- map) println(s"key:${k},value:${v}")
//遍历所有的键
for (k <- map.keys) println(k)
//遍历所有的值
for (v <- map.values) println(v)
//简便操作
map.foreach(println(_))
注意:
- 根据键获取值,如没有键会抛异常,可以通过
contains方法进行判断是否存在键 - 不可变映射不能更新
和Java的互操作
与数组相同
元组
元组是不同类型值的聚集,元组使用_1、_2进行访问
元组的下标识从1开始,不是从0开始
//定义元组
var aa = ("app", 123, false)
//访问元组
aa._1
aa._2
aa._3
//打印结果
aa: (String, Int, Boolean) = (app,123,false)
res0: String = app
res1: Int = 123
res2: Boolean = false
注意
- 元组的下标识从1开始,不是从0开始
aa._1可以写成aa _1(把点换成空格),不能省略空格- 元组可用于函数需要返回不止一个值的情况
- 可以把多个值绑在一起以便他们以后能够被一起处理
队列
队列是一个先进先出的结构
import scala.collection.mutable
var q = new mutable.Queue[Int]()
q += 1
q +=2
q ++= List(3,4,5)
//出队 删除 1
q.dequeue()
//入队 新加6
q.enqueue(6)
q
//获取第一个元素
q.head
//获取除了第一元素之外的其他元素
q.tail
打印结果:
import scala.collection.mutable
q: scala.collection.mutable.Queue[Int] = Queue()
res0: scala.collection.mutable.Queue[Int] = Queue(1)
res1: scala.collection.mutable.Queue[Int] = Queue(1, 2)
res2: scala.collection.mutable.Queue[Int] = Queue(1, 2, 3, 4, 5)
res3: Int = 1
res4: Unit = ()
res5: scala.collection.mutable.Queue[Int] = Queue(2, 3, 4, 5, 6)
res6: Int = 2
res7: scala.collection.mutable.Queue[Int] = Queue(3, 4, 5, 6)
堆栈
Stack 是一个先进后出的结构
import scala.collection.mutable
val s = new mutable.Stack[Int]();
//入栈
s.push(1,2,3,4)
//出栈
s.pop()
s
//取栈顶上的元素 但不出栈
s.top
//取除了栈顶的其他元素
s.tail
打印:
import scala.collection.mutable
s: scala.collection.mutable.Stack[Int] = Stack()
res0: scala.collection.mutable.Stack[Int] = Stack(4, 3, 2, 1)
res1: Int = 4
res2: scala.collection.mutable.Stack[Int] = Stack(3, 2, 1)
res3: Int = 3
res4: scala.collection.mutable.Stack[Int] = Stack(2, 1)
列表
如果List为空,用Nil来表示
val list1 = List(1, 2, 3)
//第一个元素
list1.head
//除了第一个元素的之后元素
list1.tail
//将9 放到list1这个列表的最前面
var list2 = 9 :: list1
list2
//组成9,4,2一个列表
var list3 = 9 :: (4 :: (2 :: Nil))
list3
打印结果:
list1: List[Int] = List(1, 2, 3)
res0: Int = 1
res1: List[Int] = List(2, 3)
list2: List[Int] = List(9, 1, 2, 3)
res2: List[Int] = List(9, 1, 2, 3)
list3: List[Int] = List(9, 4, 2)
res3: List[Int] = List(9, 4, 2)
集
- 元素不重复
- 无顺序,默认哈希
- 有需集(SortedSet,红黑树实现)
val set = Set(1, 2, 3, 3)
val set2 = set + 5
set
set.head
set.tail
打印结果:
set: scala.collection.immutable.Set[Int] = Set(1, 2, 3)
res0: scala.collection.immutable.Set[Int] = Set(1, 2, 3, 5)
res1: scala.collection.immutable.Set[Int] = Set(1, 2, 3)
res2: Int = 1
res3: scala.collection.immutable.Set[Int] = Set(2, 3)
添加去除元素的操作符
- 向后
:+或向前+:追加元素到序列中 - 添加
+元素到无先后次序的集合中 - 用
-移除元素(map只能加不能减) - 用
++或--来批量添加和移除元素 - 对于列表,优先使用
::和::: - 改值操作有
+=,++=,-=,--= - 集合可以使用
&求交集,|并集 - 优先使用
++、&、|、尽量不用++:、+=:、++=:
val set = Set(1, 2, 3, 3)
val set1 = Set(2, 3, 4)
//并集 1, 2, 3, 4
set | set1
//交集 2, 3
set & set1
常用方法
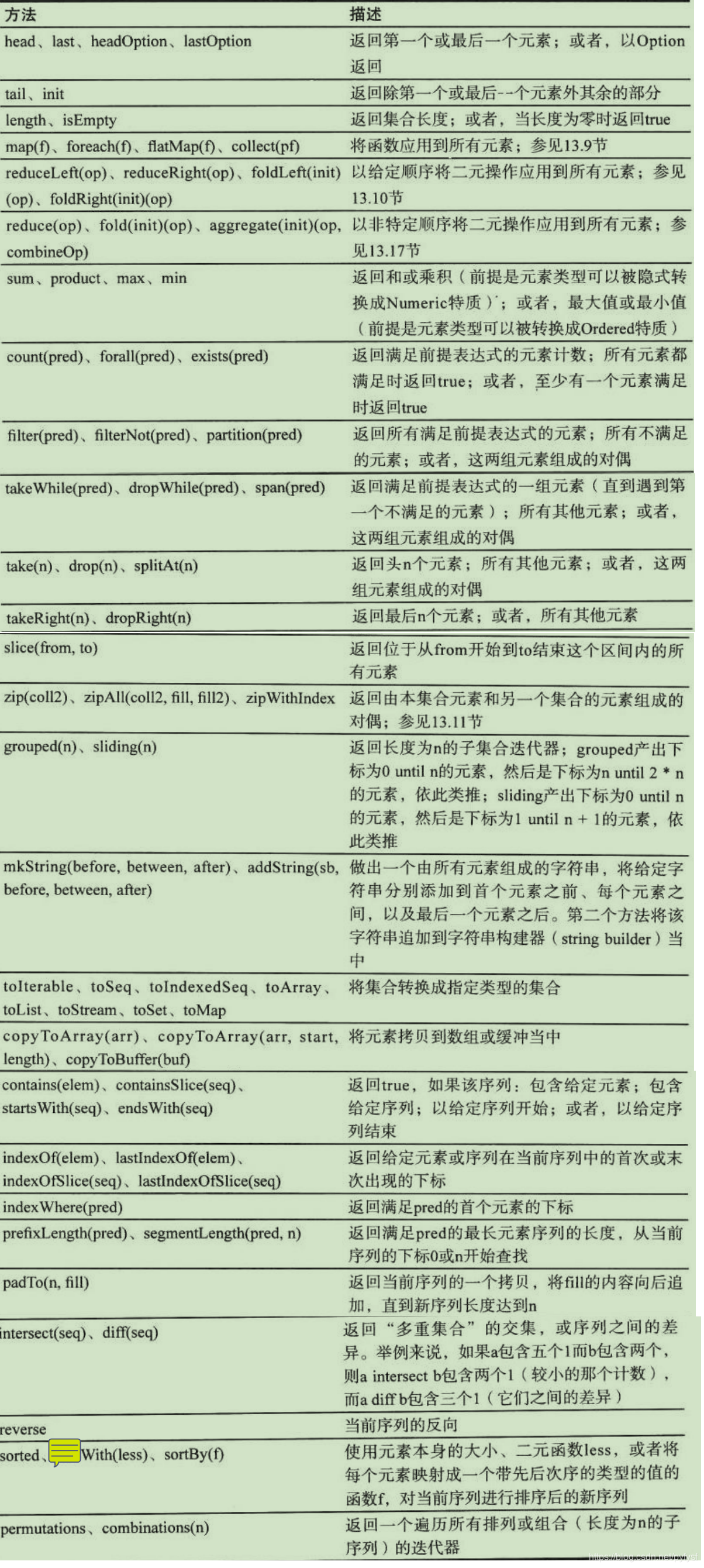
这些方法从不改变原有集合。他们返回一个与原集合类型相同的新集合
将函数映射到集合
将一元函数应用到集合中的每一个元素。
map应用于集合中的每一个元素,并产生转换后的一个新元素。
val names = List("peter", "Bob", "Mary")
//List(peter, bob, mary) 通过map方法,传入函数应用到每个元素上
names.map(_.toLowerCase)
flatMap方法同样应用于集合的每一个元素,对于每一个元素产生的一个集合,并将集合中的元素串接在一起。
val names = List("peter", "Bob", "Mary")
def ulcase(s: String) = Vector(s.toLowerCase(), s.toUpperCase())
//peter, PETER, bob, BOB, mary, MARY
names.flatMap(ulcase(_))
化简、折叠、扫描
将二元函数应用到集合中的元素
例如:
化简操作:
val list = List(1, 2, 3, 4, 5)
//(((1-2)-3)-4)-5 = -13
list.reduceLeft(_ - _)
//1-(2-(3-(4-5))) = 3
list.reduceRight(_ - _)
折叠操作
val list = List(1, 2, 3, 4, 5)
//0-1-2-3-4-5
list.foldLeft(0)(_ - _)
//1-(2-(3-(4-(5-0))))
list.foldRight(0)(_ - _)
求字符出现的次数
/*
getOrElse
第一个参数是key,如果该key存在,那么返回key对应的值
第二个参数是默认值,如果key不存在,那么返回默认值
freq += ('a' -> 0)
//i: Int = 1
val i = freq.getOrElse('u', 1)
//a: Int = 0
val a = freq.getOrElse('a', 1)
*/
val line = "upuptop"
var freq = scala.collection.mutable.Map[Char, Int]()
//循环赋值 如果字符存在那么拿到存储的值进行加1操作 如果没有存储 k为字符 v为1
for (i <- line) freq(i) = freq.getOrElse(i, 0) + 1
println(freq)
扫描操作:
扫描就是化简和折叠的结合。可以得到包含所有中间结果的集合:
var list = List(1, 2, 3, 4, 5)
list.scanLeft(0)(_ - _)
list.scanRight(0)(_ - _)
打印结果
list: List[Int] = List(1, 2, 3, 4, 5)
res0: List[Int] = List(0, -1, -3, -6, -10, -15)
res1: List[Int] = List(3, -2, 4, -1, 5, 0)
拉链操作
作用于两个集合,将对应的元素合并成一个元组。
var list = List(1, 2, 3, 4, 5)
var list2 = List(2, 3, 4, 5, 6)
//List((1,2), (2,3), (3,4), (4,5), (5,6))
list.zip(list2)
//List((1,0), (2,1), (3,2), (4,3), (5,4))
list.zipWithIndex
迭代器
使用迭代器进行集合遍历
var list = List(1, 2, 3, 4, 5)
val iterator = list.iterator
while (iterator.hasNext) {
println(iterator.next())
}
或者:
for (i <- iterator) println(i)
流(不可变列表)
流Stream只有在需要的时候才会去计算下一个元素,是一个尾部被懒计算的不可变列表。
#::操作符用于返回流。
// #:: 返回一个流
def numsForm(n: BigInt) : Stream[BigInt] = n #:: numsForm( n + 1 )
val tenOrMore = numsForm(10)
tenOrMore.tail
tenOrMore.head
// 获取最后一个元素
tenOrMore.tail.tail.tail
var squares = numsForm(5).map(x => x * x)
squares.take(5).force
//squares.force 不要尝试对一个无穷流的成员进行求值,OutOfMemoryError
懒视图
可以对其他集合使用view方法是集合具有懒执行的行为,该方法产出一个器方法总是被懒执行的集合、但是view不会缓存数据,每次都要重新计算
// 通过View的懒执行
val palindromicSquares = (1 to 100).view.map(x => {
println(x);
x * x
})
// Evaluates the first eleven
palindromicSquares.take(10).mkString(",")
// Contrast with streams
def squares(x: Int): Stream[Int] = {
println(x);
x * x
} #:: squares(x + 1)
val palindromicSquareStream = squares(0)
palindromicSquareStream(10)
// Caution
// Evaluates only the first ten
palindromicSquares.take(10).last
// Evaluates all elements
palindromicSquares(10)
与java集合互操作的总结
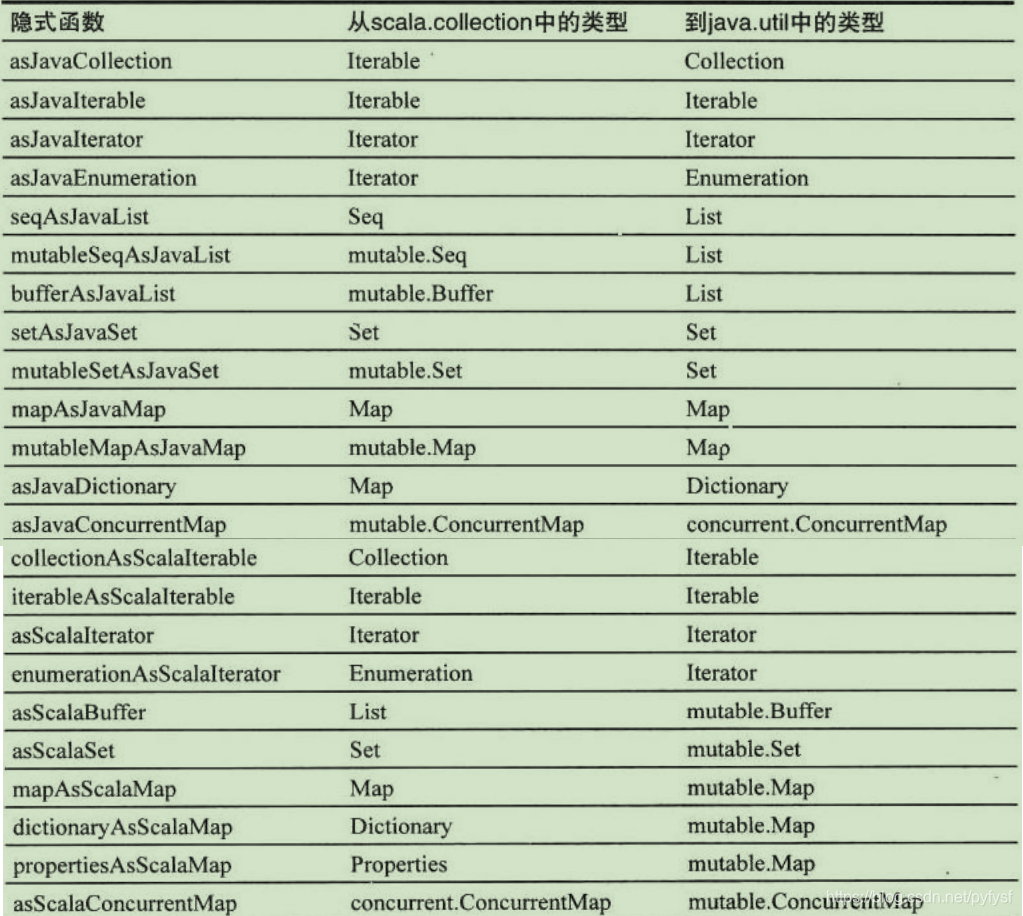
线程安全的集合
- SynchronizedBuffer
- SynchronizedMap
- SynchronizedPriorityQueue
- SynchronizedQueue
- SynchronizedSet
- SynchronizedStack
var scores = new mutable.HashMap[String,Int]() with mutable.SynchronizedMap[String,Int]
并行集合
Scala为了充分利用多核CPU,提供了并行集合(有别于前面的串行集合),用于多核环境的并行计算。
主要用的算法有:
divide and conquer:分治算法
Scala通过splitters,combiners等抽象层来实现。主要原理是将计算工作分解很多任务,分发给一些处理器去完成,并将它们处理结果合并返回
work stealing:Work Stealing算法
主要用于任务调度负载均衡。
并行集合位于scala.collection.parallel,跟不同集合一样
主要的实现类:
- ParArray
- ParHashMap
- ParHashSet
- ParRange
- ParHashMap
- ParHashSet
- ParVector
通过
par关键字将集合转为一个并行集合,并行集合的扩展自ParSeq、ParSet、ParMap特质的类型,所有的特质都是ParIterable的子类型,但并不是Iterable的子类型。所以不能将并行集合传递为预期的Iterable、Seq、Map的方法。可以通过ser方法将并行集合转为串行集合
注意:在并行任务中,不要同时更新一个共享变量
操作符概述
1.如果想在变量名、类名、等定义中使用保留字,可以使用反引号:
val `val` = 42
2.A 操作符 B 等同于 A.操作符(B) 这种形式叫中置操作符
3.后置操作符:A 操作符等同于 A.操作符 ,如果操作符定义的时候不带() 则调用的时候不能加()
4.前置操作符,=、-、!、~等 操作符 A 等同于 A.unary_操作符
5.赋值操作符, A操作符= B 等同于 A = A 操作符 B