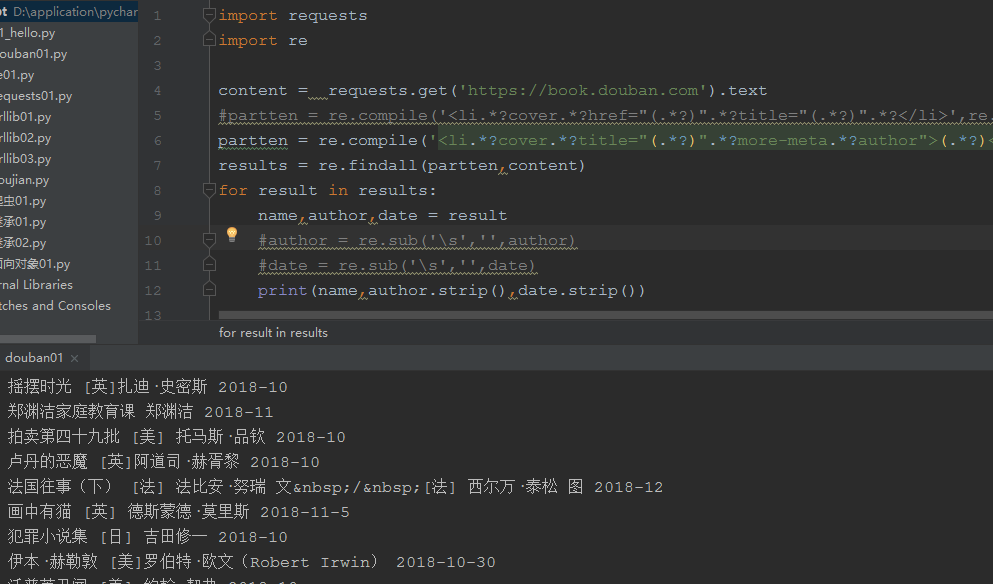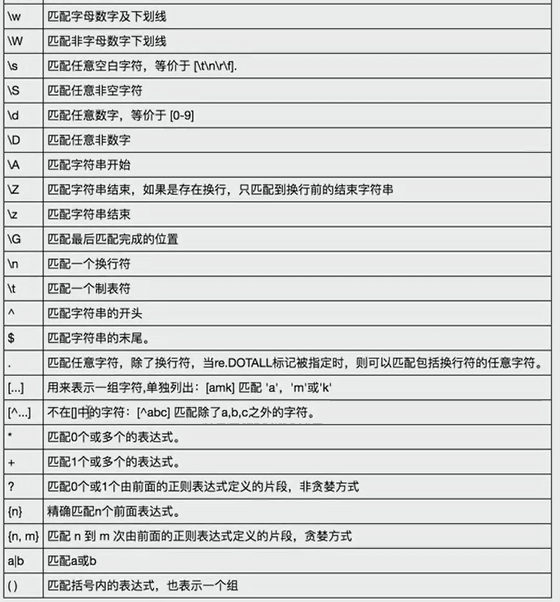
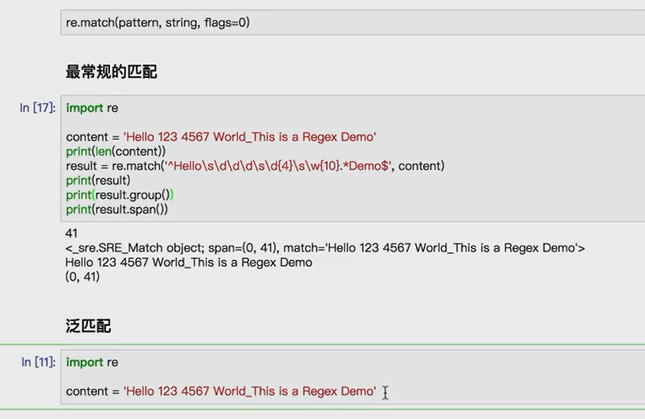
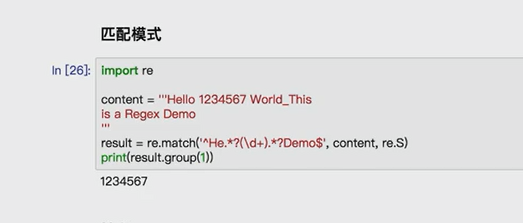


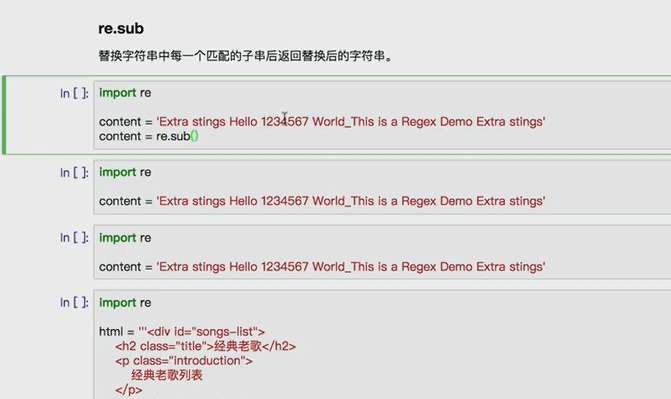
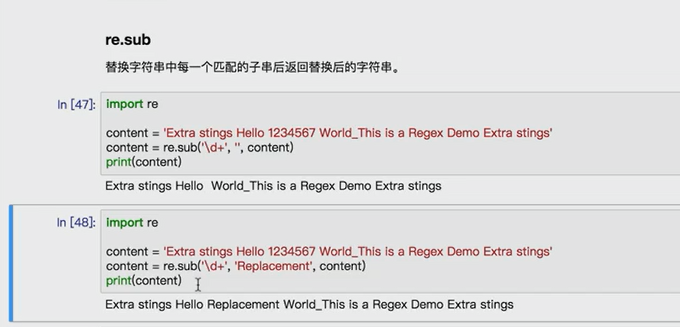
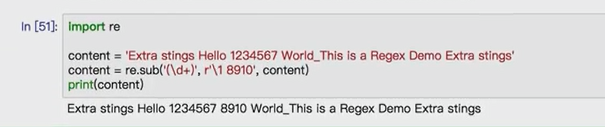
import requests import re content = requests.get('https://book.douban.com').text #partten = re.compile('<li.*?cover.*?href="(.*?)".*?title="(.*?)".*?</li>',re.S) partten = re.compile('<li.*?cover.*?title="(.*?)".*?more-meta.*?author">(.*?)</span>.*?year">(.*?)</span>.*?</li>',re.S) results = re.findall(partten,content) for result in results: name,author,date = result #author = re.sub('s','',author) #date = re.sub('s','',date) print(name,author.strip(),date.strip())