三、InfluxQL 查询语言详解
1,基本查询
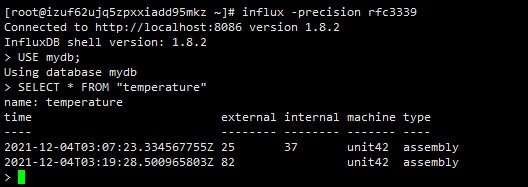
SELECT "machine"::tag, "external"::field, "internal"::field FROM "temperature"
(3)从单个 measurement 中选择特定的 tag 和 field,并提供其标识符类型
提示:通过指定标识符的类型,可以区分具有相同名称的 field key 和 tag key。
SELECT "machine"::tag, "external"::field, "internal"::field FROM "temperature"
(4)从单个 measurement 查询所有 field:
SELECT *::field FROM "temperature"
(5)从 measurement 中选择一个特定的 field 并执行基本计算:
SELECT ("temperature" * 2) + 4 FROM "temperature"
2,FROM 子句
SELECT * FROM "temperature","temperature2"
(2)一个完全指定的 measurement(<database_name>.<retention_policy_name>.<measurement_name>)中返回数据,这个完全指定是指指定了数据库和存储策略:
SELECT * FROM "mydb"."autogen"."temperature"
(3)从特定数据库中查询 measurement 的所有数据(跟上面完全指定相比,少了存储策略):
SELECT * FROM "mydb".."temperature"
3,WHERE 子句
支持的操作符: = 等于 <> 不等于 != 不等于 > 大于 >= 大于等于 < 小于 <= 小于等于
// 查询有特定field的key value为字符串的数据 SELECT * FROM "temperature" WHERE "xxx" = '25' // 查询有特定field的key value并且带计算的数据 SELECT * FROM "temperature" WHERE "external" + 2 > 1
(2)而 tag value 只能是字符串,因此需要用单引号来把 tag value 引起来:
支持的操作符: = 等于 <> 不等于 != 不等于
(3)还可以根据时间戳来过滤数据:
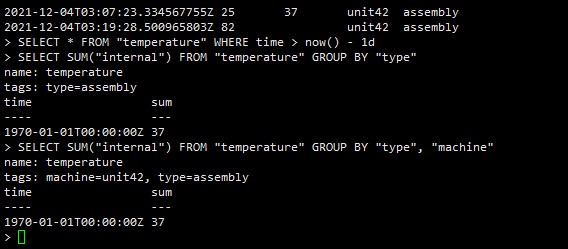
SELECT * FROM "temperature" WHERE time > now() - 7d SELECT * FROM "temperature" WHERE time >= '2015-08-18T00:00:00Z' AND time <= '2015-08-18T00:30:00Z'
4,根据 Tag 进行 GROUP BY
(1)对单个 tag 作 group by:
SELECT SUM("internal") FROM "temperature" GROUP BY "type"
(2)对多个 tag 作 group by:
SELECT SUM("internal") FROM "temperature" GROUP BY "type", "machine"
 (3)对所有 tag 作 group by:
(3)对所有 tag 作 group by:
SELECT SUM("internal") FROM "temperature" GROUP BY *
5,根据时间戳进行 GROUP BY
(1)GROUP BY time(time_interval) 返回结果按指定的时间间隔 group by:
// 时间间隔为30分钟并且还对tag key作group by SELECT MAX("external") FROM "temperature" WHERE time >= '2020-08-01T20:00:00Z' AND time < '2020-08-02T00:00:00Z' GROUP BY time(30m),"type"

(2)GROUP BY time(time_interval, offset_interval) 与上面相比多了个 offset_interval 参数,offset_interval 是一个持续时间。它向前或向后移动 InfluxDB 的预设时间界限。offset_interval 可以为正或负。
// 时间间隔为30分钟并且还对tag key作group by,并将预设时间边界向前移动 25 分钟 SELECT MAX("external") FROM "temperature" WHERE time >= '2020-08-01T20:00:00Z' AND time < '2020-08-02T00:00:00Z' GROUP BY time(30m,15m),"type"

(3)fill(<fill_option>)是可选的,它会更改不含数据的时间间隔的返回值:
SELECT MAX("external") FROM "temperature" WHERE time >= '2020-08-01T20:00:00Z' AND time < '2020-08-02T00:00:00Z' GROUP BY time(30m) fill(0)

6,ORDER BY TIME DESC
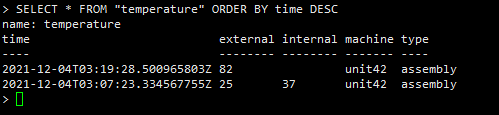
(1)默认情况下,InfluxDB 以升序的顺序返回结果:返回的第一个点具有最早的时间戳,返回的最后一个点具有最新的时间戳。
(2)ORDER BY time DESC 反转该顺序,使得 InfluxDB 首先返回具有最新时间戳的点:
SELECT * FROM "temperature" ORDER BY time DESC
7,LIMIT 和 SLIMIT 子句
// 限制返回的点数 SELECT * FROM "temperature" LIMIT 2
(2)SLIMIT <M>:M 指定从指定 measurement 返回的 series 数。如果 M 大于 measurement 中 series 联数,InfluxDB 将从该 measurement 中返回所有 series。
// 限制返回的series的数目 SELECT * FROM "temperature" SLIMIT 2
(3)LIMIT 和 SLIMIT 可以同时使用:
// 限制数据点数和series数并且包括一个GROUP BY time()子句 SELECT * FROM "temperature" WHERE time >= '2015-08-18T00:00:00Z' AND time <= '2015-08-18T00:42:00Z' GROUP BY *,time(12m) LIMIT 2 SLIMIT 1
8,OFFSET 和 SOFFSET子句
// 从下标4开始的第5、6、7行总共3行显示了出来 SELECT * FROM "temperature" LIMIT 3 OFFSET 4
(2)SOFFSET 将从查询结果的第 N 个 series 开始进行分页。
SELECT count(external) FROM "temperature" GROUP BY * SLIMIT 1 SOFFSET 1
9,时间语法
// 对RFC3339格式的时间戳的基本计算 SELECT * FROM "temperature" WHERE time > '2021-12-04T03:04:00Z' + 6m // 对epoch时间戳的基本计算 SELECT * FROM "temperature" WHERE time > 24043524m - 6m
(2)使用 now() 查询时间戳相对于服务器当前时间戳的的数据,同样也支持基本算术。
// 用相对时间指定时间间隔 SELECT * FROM "temperature" WHERE time > now() - 1h // 用绝对和相对时间指定时间间隔 SELECT * FROM "temperature" WHERE time > '2015-09-18T21:18:00Z' AND time < now() + 1000d
10,正则表达式
=~ 匹配 !~ 不匹配
(2)InluxDB 支持在以下场景使用正则表达式:
注意:目前,InfluxQL 不支持在 WHERE 中使用正则表达式去匹配不是字符串的 field value,以及数据库名和 retention policy。
在 SELECT 中的 field key 和 tag key 在 FROM 中的 measurement 在 WHERE 中的 tag value 和字符串类型的 field value 在 GROUP BY 中的 tag key
(3)下面一些使用正则表达式的样例:
注意:正则表达式比精确的字符串更加耗费计算资源; 具有正则表达式的查询比那些没有的性能要低一些。
// 在SELECT中使用正则表达式指定field key和tag key SELECT /a/ FROM "temperature" LIMIT 1 //在FROM中使用正则表达式指定measurement SELECT MEAN("internal") FROM /temperature/ // 在WHERE中使用正则表达式指定tag value SELECT MEAN(internal) FROM "temperature" WHERE "machine" =~ /[u]/ // 在WHERE中使用正则表达式指定无值的tag SELECT * FROM "temperature" WHERE "machine" !~ /./ // 在WHERE中使用正则表达式指定有值的tag SELECT MEAN("internal") FROM "temperature" WHERE "machine" =~ /./
11,子查询
子查询相关说明: InfluxDB 首先执行子查询,再次执行主查询。 主查询围绕子查询,至少需要 SELECT 和 FROM 子句。主查询支持本文档中列出的所有子句。 子查询显示在主查询的 FROM 子句中,它需要附加的括号。子查询支持本文档中列出的所有子句。 InfluxQL 每个主要查询支持多个嵌套子查询。
(2)下面是子查询样例:
// 计算多个`MAX()`值的`SUM()` SELECT SUM("max") FROM (SELECT MAX("internal") FROM "temperature" GROUP BY "machine") // 计算两个field的差值的`MEAN()` SELECT MEAN("difference") FROM (SELECT "external" - "internal" AS "difference" FROM "temperature")