目录
指令格式及操作数解析归类
对于不同类别如何处理
MOD=0
MOD=1/2/3
SIB解析
前缀解析
关于ESP和EBP为什么被用来特殊寻址
指令格式及操作数解析归类
指令格式一般是按照intel给出的指令格式作为基础,然后再扩充一些反编译过程中会用到的元素,诸如源和目的操作数的顺序,反编译时候的地址等信息。
至于操作数类别,还是按照intel手册上的分类来的,诸如E、G、I等种类。对于不同种类需要做不同的处理。

图1指令格式及操作数解析归类
至于右上角那个数组,是为了方便编程。因为最后要用汇编语言来表示结果,恰好各个寄存器也是顺序编号的,就用数组来索引了。
对于不同类别如何处理
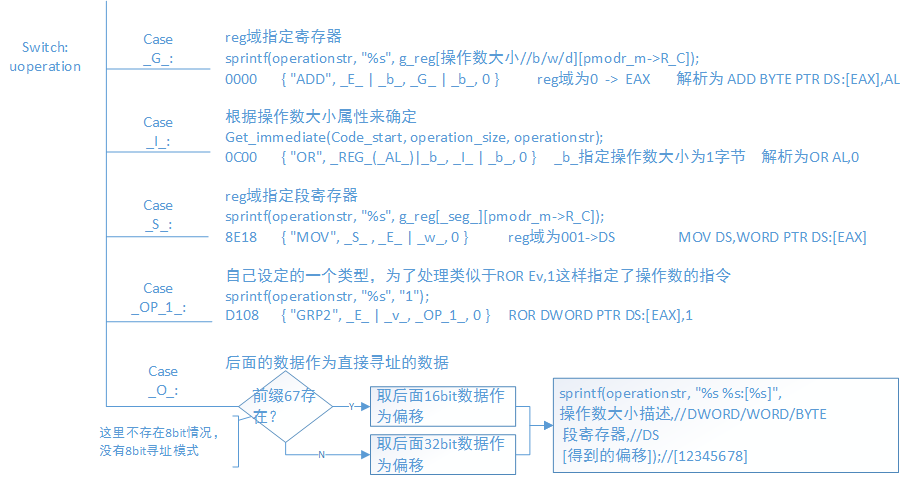
图2 对于不同类别如何处理1

图3 对于不同类别如何处理2
对于不同的操作数类别做不同的处理,流程图中应该很详细了。
如果有的操作数需要MODR/M和SIB域该怎么处理呢?像E这个类别
MOD=0

图4 MOD=0如何处理
根据是否有前缀做分类处理
根据R/M的值做分类,比较特殊的是R/M==4和R/M==5的,也就是轮到esp和ebp了,要搞特殊化了。后面会说原因的。
MOD=1/2/3

图5 MOD=1/2/3如何处理
还是根据前缀是否存在和R/M的特殊值来做处理。比较奇怪的是R/M==5,也就是ebp这个时候倒正常了。
SIB解析

图6 SIB解析
可以看到SIB的处理里面特殊的情况比较多,只能一条条慢慢实现了。
前缀解析
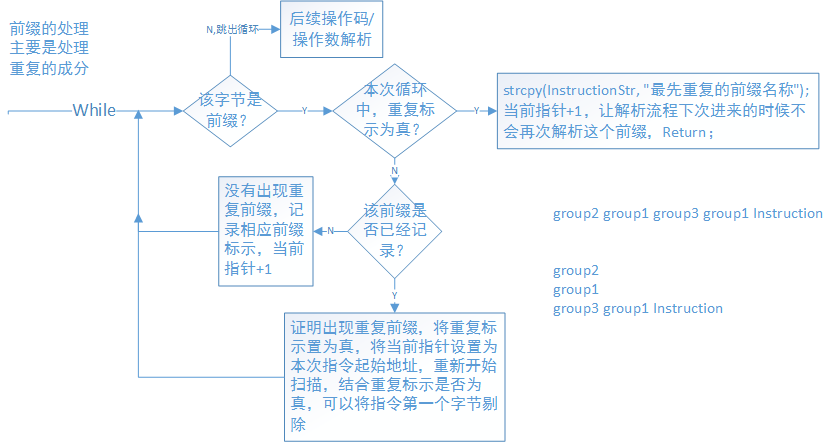
图7 前缀解析
前缀的处理出要要关注两点,一个是前缀不可能无限多,第二个就是要处理重复的前缀。像右下角的例子,group1出现了两次,那么重复的前缀及其之前的前缀都无效了。
关于ESP和EBP为什么被用来特殊寻址

图8 关于ESP和EBP为什么被用来特殊寻址
这个是我在邓志的个人主站上找到答案的。非常感谢。膜拜大神。
对ebp做的特殊处理就是ebp不能单独以[ebp]形式参与寻址,要么用立即数取代,要么用[ebp+disp]形式。
而关于esp做的特殊处理,我想完全是因为找不到合适的寄存器了,才让[esp]这种形式承担SIB的义务。但是[esp]这种形式承担了SIB的义务,那么编译器就想用[esp]这种形式怎么办,你说不给我[ebp]这种形式,是因为他是基址寄存器,不让单独用,我接受这个理由了。难道[esp]你还来一个规定吗?intel没有做特殊规定,为了表示出[esp]这种形式,让index==4(即ESP)时,scale*index=0,这样base==4(ESP)时候,就存在[esp]这样的形式了。
比较low的opcode map表

图9 opcode_map表
其实上面说了那么多,就是为了这一张表,按照intel的map表转化为自己的程序能识别的格式,我这个比较low,完全是照着intel的表格抄了一份。