有时候我们在使用sql数据库的时候,想去掉重复数据,怎么去掉呢,下面来分享一下方法
我们在这里使用的数据库是 mysql
创建表
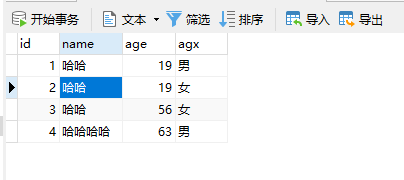
首先我们创建一个 student 表
DROP TABLE IF EXISTS `student`; CREATE TABLE `student` ( `id` int(0) NOT NULL, `name` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL, `age` int(0) NULL DEFAULT NULL, `agx` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL, PRIMARY KEY (`id`) USING BTREE ) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
插入数据
INSERT INTO `student` VALUES (1, '哈哈', 19, '男'); INSERT INTO `student` VALUES (2, '哈哈', 19, '女'); INSERT INTO `student` VALUES (3, '哈哈', 56, '女'); INSERT INTO `student` VALUES (4, '哈哈哈哈', 63, '男');
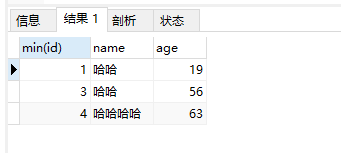
使用sql找出需要保留的数据
我们保留 name 和 age 重复的数据(id 值最小的)
SELECT min(id),name,age FROM `student` GROUP BY `name`,age
删除重复的数据
DELETE FROM student WHERE id NOT IN (SELECT min_id FROM (SELECT min(id) as min_id FROM `student` GROUP BY `name`,age) as a)


注:
如果使用
DELETE FROM student WHERE id NOT IN (SELECT min(id) as min_id FROM `student` GROUP BY `name`,age)
在语法上看是没问题的,但是在 MySQL中会出先 1093 - You can't specify target table 'student' for update in FROM clause 错误,但是在 mssql与oracle都没有这个问题。