-
Scala介绍
Scala是一门综合了面向对象和函数式编程的语言, 运行在JVM之上, 能够和Java语言互操作
-
Scala的特点
-
语法简洁
-
开发速度快/运行速度快
-
兼容Java
-
很多大数据框架的源码或编程接口都支持Scala
-
运用广泛
-
Scala开发环境
运行环境
1.安装JDK
2.下载ScalaSDK:https://www.scala-lang.org/download/2.12.12.html
3.安装ScalaSDK
直接双击scala-2.12.11.msi或解压scala-2.12.11.zip到指定目录,如C:developsoftscala-2.12.11,要求纯英文目录
4.检查或配置环境变量:
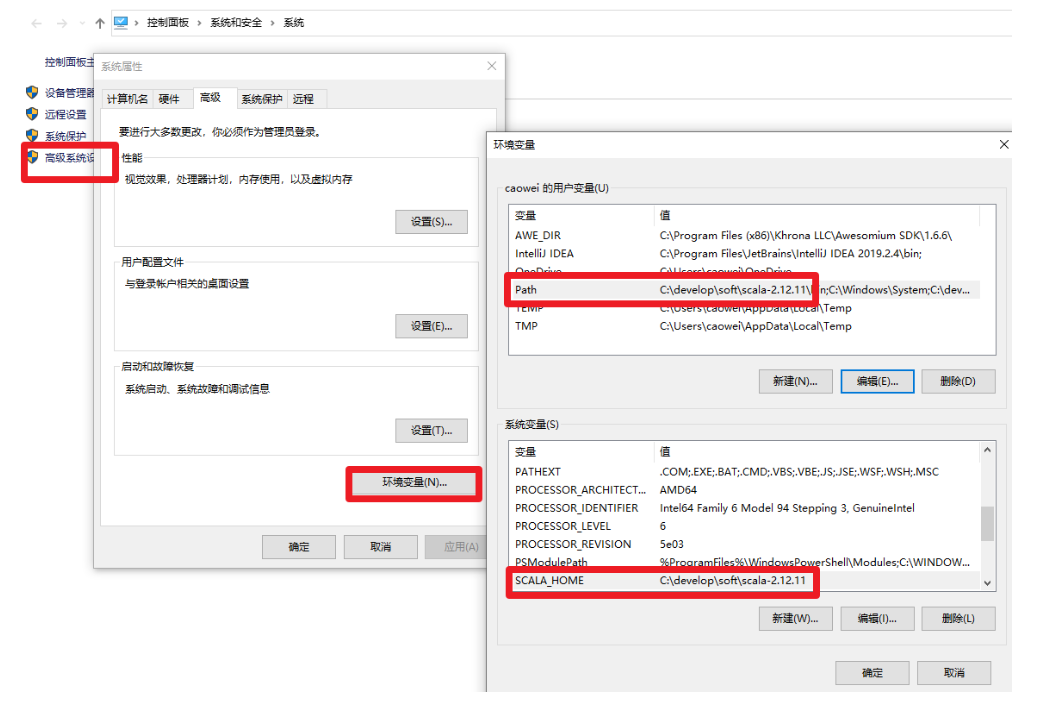
5.检验是否安装成功
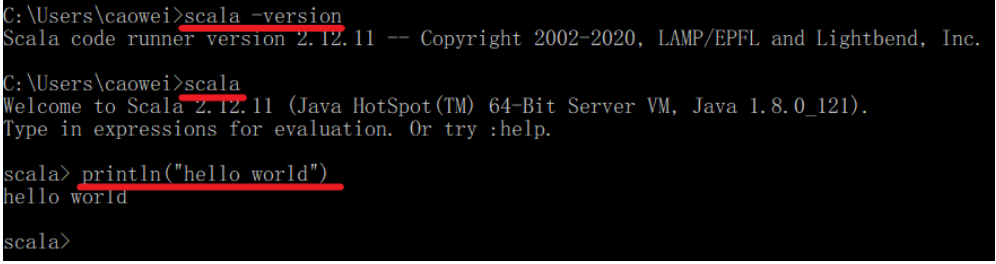
6.验证Scala是运行在JVM之上的
-
在txt里面编写HelloWorld.scala
object HelloWorld {
def main(args: Array[String]): Unit = {
println("Hello World!")
}
}
-
scalac 进行编译
-
scala运行编译之后的字节码
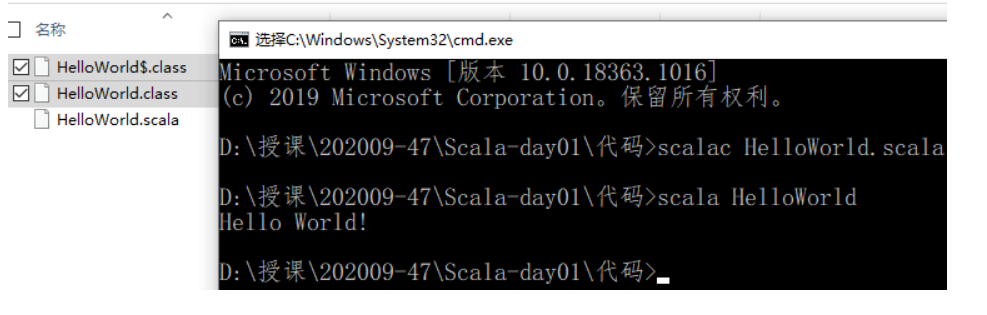
开发环境
idea插件在线安装
离线安装
1.查看版本
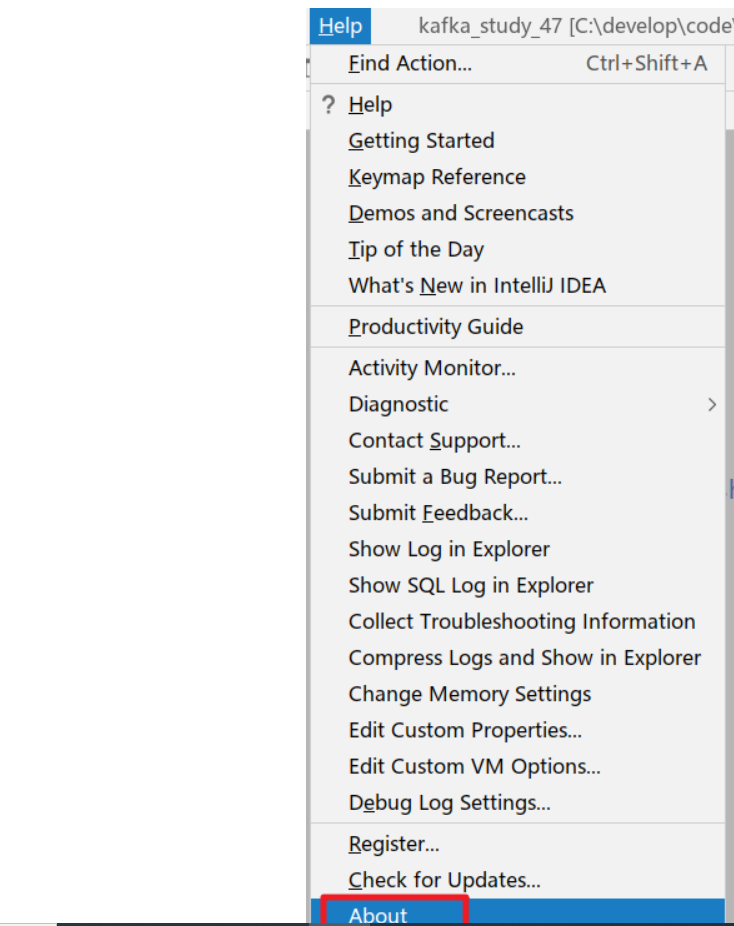
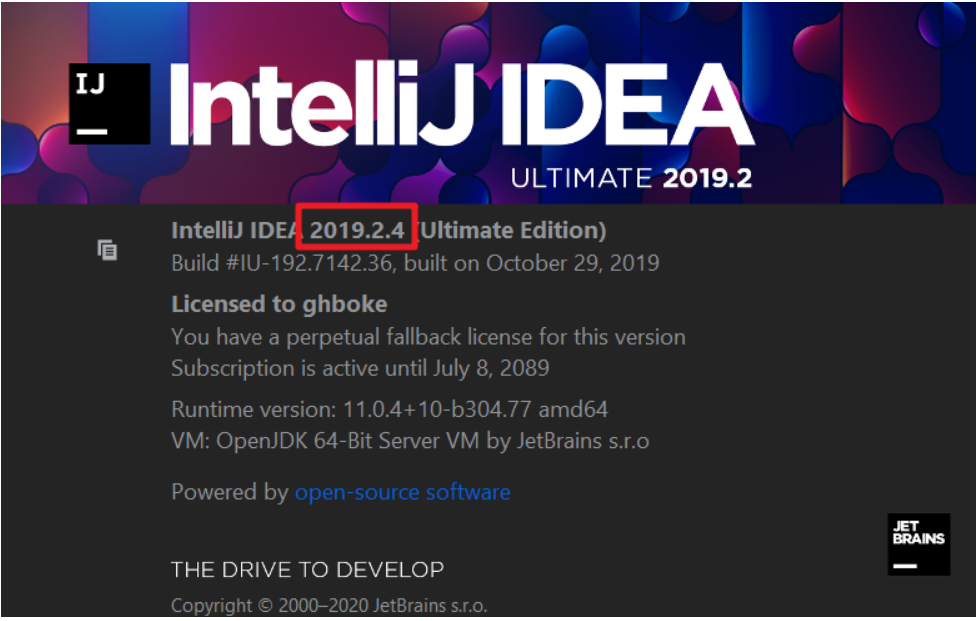
2.下载对应版本的插件
https://plugins.jetbrains.com/plugin/1347-scala/versions
3.导入本地插件

4.重启idea
5.后续就可以使用idea进行scala项目开发
6.注意: 新建项目的时候还是建maven的项目(方便后续引入java相关依赖)
7.在项目中关联本地的Scala的SDK + 插件的支持 就可以去新建Scala相关的类了
Scala初体验
创建项目
1.创建maven项目
2.添加本地的ScalaSDK支持
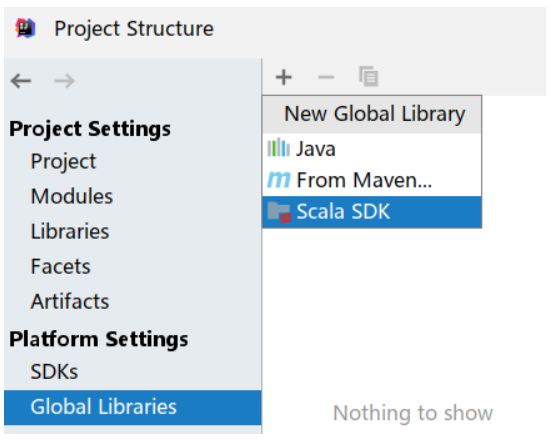
3.添加mavne的pom依赖