第1章Spark Streaming概念
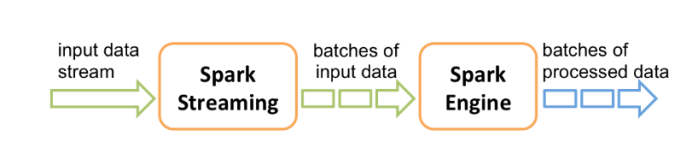
Spark Streaming 是核心Spark API的扩展,可实现实时数据的可扩展,高吞吐量,容错处理。数据可以从许多来源(如Kafka,Flume,Kinesis,或TCP套接字)中获取,并可以使用高级函数进行处理,处理完后的数据可以推送到文件系统,数据库和实时仪表板。

在内部,他的工作原理如下,Spark Streaming接收实时输入数据流并将数据分成批处理,然后由Spark引擎处理以批处理生成最终结果流。
第2章 项目需求及架构设计
2.1 项目需求分析
一、数据采集平台搭建
二、Kafka、Zookeeper中间件准备
三、下游Spark Streaming对接Kafka接收数据,实现vip个数统计、栏目打标签功能、做题正确率与掌握度的实时计算功能。
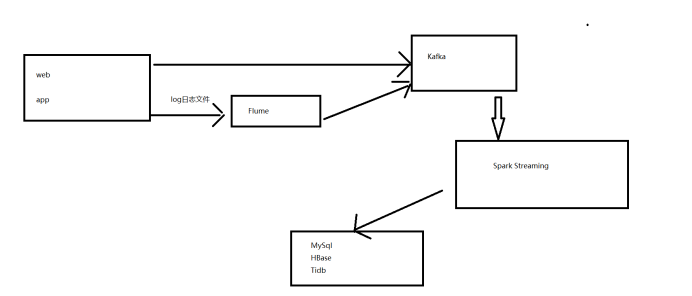
2.2 项目框架
2.2.1 技术选型
一、数据存储:Kafka、MySql
二、数据处理:Spark
三、其他组件:Zookeeper
2.2.2 流程设计
第3章 需求
3.0原始数据格式及对应topic
3.01实时统计注册人数
kafka对应 topic: register_topic
数据格式:
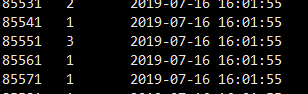
85571 1 2019-07-16 16:01:55
用户id 平台id 1:PC 2:APP 3:Ohter 创建时间
3.0.2做题正确率数与知识点掌握度数据格式
Kafka 对应topic: qz_log
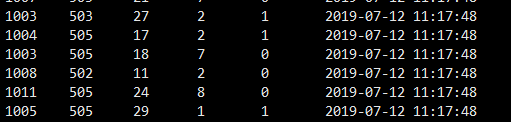
数据格式:

字段含义:
1005 505 29 1 1 2019-09-12 11:17:48
(用户id) (课程id) (知识点id) (题目id) (是否正确 0错误 1正确)(创建时间)
3.0.3商品页面到订单页,订单页到支付页数据格式
Kafka 对应topic: page_topic
数据格式
{"app_id":"1","device_id":"102","distinct_id":"5fa401c8-dd45-4425-b8c6-700f9f74c532","event_name":"-","ip":"121.76.152.135","last_event_name":"-","last_page_id":"0","next_event_name":"-","next_page_id":"2","page_id":"1","server_time":"-","uid":"245494"}
uid:用户id app_id:平台id deviceid:设备id disinct_id:唯一标识
Ip:用户ip地址
last_page_id :上一页面id
page_id:当前页面id 0:首页 1:商品课程页 2:订单页面 3:支付页面
next_page_id:下一页面id
3.0.4实时统计学员播放视频各时长
Kafka 对应topic: course_learn
数据格式:

{"biz":"bdfb58e5-d14c-45d2-91bc-1d9409800ac3","chapterid":"1","cwareid":"3","edutypeid":"3","pe":"55","ps":"41","sourceType":"APP","speed":"2","subjectid":"2","te":"1563352166417","ts":"1563352159417","uid":"235","videoid":"2"}
biz:唯一标识 chapterid:章节id cwareid:课件id edutypeid:辅导id ps:视频播放时间区间 pe:视频播放结束区间 sourceType:播放平台 speed:播放倍速 ts:视频播放开始时间(时间戳) te:视频播放结束时间(时间戳) videoid:视频id
3.1环境准备
在本机三台虚拟机上分别搭建好zookeeper 和kafka
创建所需topic
[atguigu@hadoop102 kafka]$ bin/kafka-topics.sh --zookeeper hadoop102:2181/kafka_2.4 --create --replication-factor 2 --partitions 10 --topic qz_log
[atguigu@hadoop102 kafka]$ bin/kafka-topics.sh --zookeeper hadoop102:2181/kafka_2.4 --create --replication-factor 2 --partitions 10 --topic page_topic
[atguigu@hadoop102 kafka]$ bin/kafka-topics.sh --zookeeper hadoop102:2181/kafka_2.4 --create --replication-factor 2 --partitions 10 --topic register_topic
[atguigu@hadoop102 kafka]$ bin/kafka-topics.sh --zookeeper hadoop102:2181/kafka_2.4 --create --replication-factor 2 --partitions 10 --topic course_learn
3.2模拟数据采集
模拟数据采集 将准备好的log文件使用kafka生产者代码发送信息到topic
注册日志数据 register.log日志文件 对应topic: register_topic
做题数据 qz_log 日志文件 对应topic :qz_log
商品页面数据page_log 日志文件 对应topic:page_topic
视频播放时长数据course_learn.log日志文件 对应topic: course_learn
如果windows下没有安装hadoop环境先配置环境
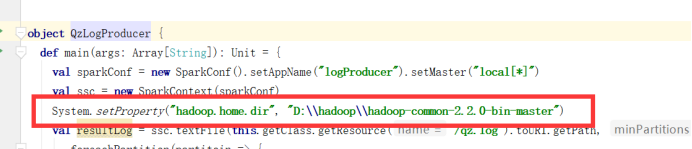
Ip解析工具
Ip解析本地库:


3.3.实时统计注册人员信息
用户使用网站或APP进行注册,后台实时收集数据传输Kafka,Spark Streaming进行对接统计,实时统计注册人数。
需求1:实时统计注册人数,批次为3秒一批,使用updateStateBykey算子计算历史数据和当前批次的数据总数,仅此需求使用updateStateBykey,后续需求不使用updateStateBykey。
需求2:每6秒统统计一次1分钟内的注册数据,不需要历史数据 提示:reduceByKeyAndWindow算子
需求3:观察对接数据,尝试进行调优。
3.4实时计算学员做题正确率与知识点掌握度
mysql建表语句:
用户在网站或APP进行做题,做完题点击交卷按钮,程序将做题记录提交,传输到Kafka中,下游Spark Streaming对接kafka实现实时计算做题正确率和掌握度,将正确率和掌握度存入mysql中,用户点击交卷后刷新页面能立马看到自己做题的详情。
需求1:要求Spark Streaming 保证数据不丢失,每秒1000条处理速度,需要手动维护偏移量
需求2:同一个用户做在同一门课程同一知识点下做题需要去重,并且需要记录去重后的做题id与个数。
需求3:计算知识点正确率 正确率计算公式:做题正确总个数/做题总数 保留两位小数
需求4:计算知识点掌握度 去重后的做题个数/当前知识点总题数(已知30题)*当前知识点的正确率
3.5实时统计商品页到订单页,订单页到支付页转换率
mysql建表语句:
用户浏览课程首页点击下订单,跳转到订单页面,再点击支付跳转到支付页面进行支付,收集各页面跳转json数据,解析json数据计算各页面点击数和转换率,计算top3点击量按地区排名(ip字段,需要根据历史数据累计)
需求1:计算首页总浏览数、订单页总浏览数、支付页面总浏览数
需求2:计算商品课程页面到订单页的跳转转换率、订单页面到支付页面的跳转转换率
需求3:根据ip得出相应省份,展示出top3省份的点击数,需要根据历史数据累加
3.6实时统计学员播放视频各时长
建表语句:
用户在线播放视频进行学习课程,后台记录视频播放开始区间和结束区间,及播放开始时间和播放结束时间,后台手机数据传输kafka需要计算用户播放视频总时长、有效时长、完成时长,及各维度总播放时长。
需求1:计算各章节下的播放总时长(按chapterid聚合统计播放总时长)
需求2:计算各课件下的播放总时长(按cwareid聚合统计播放总时长)
需求3:计算各辅导下的播放总时长(按edutypeid聚合统计播放总时长)
需求4:计算各播放平台下的播放总时长(按sourcetype聚合统计播放总时长)
需求5:计算各科目下的播放总时长(按subjectid聚合统计播放总时长)
需求6:计算用户学习视频的播放总时长、有效时长、完成时长,需求记录视频播历史区间,对于用户多次学习的播放区间不累计有效时长和完成时长。
播放总时长计算:(te-ts)/1000 向下取整 单位:秒
完成时长计算: 根据pe-ps 计算 需要对历史数据进行去重处理
有效时长计算:根据te-ts 除以pe-ts 先计算出播放每一区间需要的实际时长 * 完成时长
第4章 思考
(1)Spark Streaming 下每个stage的耗时由什么决定
(2)Spark Streaming task发生数据倾斜如何解决
(3)Spark Streaming下如何正确操作mysql(如何正确使用连接)
(4)Spark Streaming操作mysql时,相同维度的数据如何保证线程安全问题
(5)如何保证kill Spark Streaming任务的时候不丢失数据
(6)如何保证Spark Streaming的第一次启动和kill后第二次启动时据不丢失数据
(7)MySql建表时 索引注意