调用关系说明:
· 0. 服务容器负责启动,加载,运行服务提供者。
· 1. 服务提供者在启动时,向注册中心注册自己提供的服务。
· 2. 服务消费者在启动时,向注册中心订阅自己所需的服务。
· 3. 注册中心返回服务提供者地址列表给消费者,如果有变更,注册中心将基于长连接推
送变更数据给消费者。
· 4. 服务消费者,从提供者地址列表中,基于软负载均衡算法,选一台提供者进行调用,
如果调用失败,再选另一台调用。
· 5. 服务消费者和提供者,在内存中累计调用次数和调用时间,定时每分钟发送一次统计
数据到监控中心。
Zookeeper 介绍
官方推荐使用 zookeeper 注册中心。注册中心负责服务地址的注册与查找,相当于目录服务,服务提供者和消费者只在启动时与注册中心交互,注册中心不转发请求,压力较小。
Zookeeper 是 Apacahe Hadoop 的子项目,是一个树型的目录服务,支持变更推送,适合作为Dubbox 服务的注册中心,工业强度较高,可用于生产环境。
(5)编写配置文件
在src/main/resources下创建applicationContext-service.xml ,内容如下:
|
<?xml version="1.0" encoding="UTF-8"?> <beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:p="http://www.springframework.org/schema/p" xmlns:context="http://www.springframework.org/schema/context" xmlns:dubbo="http://code.alibabatech.com/schema/dubbo" xmlns:mvc="http://www.springframework.org/schema/mvc" xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd http://www.springframework.org/schema/mvc http://www.springframework.org/schema/mvc/spring-mvc.xsd http://code.alibabatech.com/schema/dubbo http://code.alibabatech.com/schema/dubbo/dubbo.xsd http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context.xsd">
<dubbo:application name="dubboxdemo-service"/> <dubbo:registry address="zookeeper://192.168.200.128:2181"/> <dubbo:annotation package="cn.itcast.dubboxdemo.service" /> </beans> |
注意:dubbo:annotation用于扫描@Service注解。
|
<?xml version="1.0" encoding="UTF-8"?> <beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:p="http://www.springframework.org/schema/p" xmlns:context="http://www.springframework.org/schema/context" xmlns:dubbo="http://code.alibabatech.com/schema/dubbo" xmlns:mvc="http://www.springframework.org/schema/mvc" xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd http://www.springframework.org/schema/mvc http://www.springframework.org/schema/mvc/spring-mvc.xsd http://code.alibabatech.com/schema/dubbo http://code.alibabatech.com/schema/dubbo/dubbo.xsd http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context.xsd"> <mvc:annotation-driven> <mvc:message-converters register-defaults="true"> <bean class="com.alibaba.fastjson.support.spring.FastJsonHttpMessageConverter"> <property name="supportedMediaTypes" value="application/json"/> <property name="features"> <array> <value>WriteMapNullValue</value> <value>WriteDateUseDateFormat</value> </array> </property> </bean> </mvc:message-converters> </mvc:annotation-driven> <!-- 引用dubbo 服务 --> <dubbo:application name="dubboxdemo-web" /> <dubbo:registry address="zookeeper://192.168.200.128:2181"/> <dubbo:annotation package="cn.itcast.dubboxdemo.controller" /> </beans> |
(6)测试运行
tomcat7:run
在浏览器输入http://localhost:8082/user/showName.do,查看浏览器输出结果
Dubbo 和 webservice 区别?
webservice :不同公司可以调用
服务调用方和提供方 语言可以不同
协议:soap+http协议 网络第七层 应用层
需要通过jdk的命令 wsimport 生成接口代码
Dubbox:只能是同一个公司调用.
语言必须相同. 服务提供和消费方必须都是java
协议:TCP协议 网络第四层 socket连接 效率更高
dubbo只需要把接口拷贝过来即可
相同点: 都是远程调用的框架
网络模型七层?
7应用层 6表示层 5会话层 4传输层(TCP协议) 3网络层(IP/tcp协议) 2数据链路层(网卡和网线连接这块) 物理层(网线,光纤)
默认使用的是什么通信框架,还有别的选择吗?
默认也推荐使用netty框架,还有mina。
2、服务调用是阻塞的吗?
因为用的是缺省协议 长连接 和NIO的模式. 非阻塞的
http是短连接 数据传输完毕断开. http1.1采用的是长连接 通过tcp协议 传输完毕 不断开连接 如果下次访问相同的域名 不需要重新连接
(1)NIO和IO的区别
NIO是非阻塞的 IO是阻塞的.
NIO是采用缓冲的 数据可以在稍后处理的缓冲区中前后移动. IO
NIO可以通过一个线程通过选择器控制多个数据通道.
3、一般使用什么注册中心?还有别的选择吗?
推荐使用zookeeper注册中心,还有redis等不推荐
4、默认使用什么序列化框架,你知道的还有哪些?
默认使用Hessian序列化, 优点:跨语言, 缺点:慢 还有Duddo、FastJson、Java自带序列化。
5、服务提供者能实现失效踢出是什么原理?
服务失效踢出基于zookeeper的临时节点原理。
敲黑板画重点
zookeeper中节点是有生命周期的.具体的生命周期取决于节点的类型.节点主要分为持久节点(Persistent)和临时节点(Ephemeral),但是更详细的话还可以加上时序节点(Sequential),创建节点中往往组合使用,因此也就是4种.
- 持久节点
- 持久顺序节点
- 临时节点
- 临时顺序节点
持久节点
所谓持久节点,是指在节点创建后,就一直存在,直到有删除操作来主动清除这个节点,也就是说不会因为创建该节点的客户端会话失效而消失
临时节点
临时节点的生命周期和客户端会话绑定,也就是说,如果客户端会话失效,那么这个节点就会自动被清除掉
应用场景 怎么判断zookeeper中的机器是否可用
zookeeper常用的应用场景我在上周已经画了思维导图,这里就不重复展示了.就拿分布式协调/通知来举例(这个例子既是在回答第一个面试题,也是在回答第二个面试题).
在分布式系统中,我们常常需要知道某个机器是否可用,传统的开发中,可以通过Ping某个主机来实现,Ping得通说明对方是可用的,相反是不可用的,因为zookeeper是一个树形结构.ZK 中我们让所有的机其都注册一个临时节点,我们判断一个机器是否可用,我们只需要判断这个节点在ZK中是否存在就可以了,不需要直接去连接需要检查的机器,降低系统的复杂度
6、服务上线怎么不影响旧版本?
采用多版本开发,不影响旧版本。
7、如何解决服务调用链过长的问题?
可以结合zipkin实现分布式服务追踪。
8、说说核心的配置有哪些?
服务方消费方 zookeeper注册中心
9、dubbo推荐用什么协议?
Dubbo通讯协议
第一、dubbo
Dubbo 缺省协议采用单一长连接和 NIO 异步通讯,适合于小数据量大并发的服务调用,以及服务消费者机器数远大于服务提供者机器数的情况。
反之,Dubbo 缺省协议不适合传送大数据量的服务,比如传文件,传视频等,除非请求量很低。
特性
缺省协议,使用基于 mina 1.1.7 和 hessian 3.2.1 的 tbremoting 交互。
- 连接个数:单连接
- 连接方式:长连接
- 传输协议:TCP
- 传输方式:NIO 异步传输
- 序列化:Hessian 二进制序列化
- 适用范围:传入传出参数数据包较小(建议小于100K),消费者比提供者个数多,单一消费者无法压满提供者,尽量不要用 dubbo 协议传输大文件或超大字符串。
- 适用场景:常规远程服务方法调用
第三、hessian
Hessian 1 协议用于集成 Hessian 的服务,Hessian 底层采用 Http 通讯,采用 Servlet 暴露服务,Dubbo 缺省内嵌 Jetty 作为服务器实现。
Dubbo 的 Hessian 协议可以和原生 Hessian 服务互操作,即:
- 提供者用 Dubbo 的 Hessian 协议暴露服务,消费者直接用标准 Hessian 接口调用
- 或者提供方用标准 Hessian 暴露服务,消费方用 Dubbo 的 Hessian 协议调用。
特性
- 连接个数:多连接
- 连接方式:短连接
- 传输协议:HTTP
- 传输方式:同步传输
- 序列化:Hessian二进制序列化
- 适用范围:传入传出参数数据包较大,提供者比消费者个数多,提供者压力较大,可传文件。
- 适用场景:页面传输,文件传输,或与原生hessian服务互操作
第四、Http
基于 HTTP 表单的远程调用协议,采用 Spring 的 HttpInvoker 实现 1
特性
- 连接个数:多连接
- 连接方式:短连接
- 传输协议:HTTP
- 传输方式:同步传输
- 序列化:表单序列化
- 适用范围:传入传出参数数据包大小混合,提供者比消费者个数多,可用浏览器查看,可用表单或URL传入参数,暂不支持传文件。
- 适用场景:需同时给应用程序和浏览器 JS 使用的服务。
第五、WebService
基于 WebService 的远程调用协议,基于 Apache CXF 1 的 frontend-simple 和 transports-http 实现 2。
可以和原生 WebService 服务互操作,即:
rmi://
RMI 协议采用 JDK 标准的 java.rmi.* 实现,采用阻塞式短连接和 JDK 标准序列化方式。
注意:如果正在使用 RMI 提供服务给外部访问 1,同时应用里依赖了老的 common-collections 包 2 的情况下,存在反序列化安全风险 3。
特性
- 连接个数:多连接
- 连接方式:短连接
- 传输协议:TCP
- 传输方式:同步传输
- 序列化:Java 标准二进制序列化
- 适用范围:传入传出参数数据包大小混合,消费者与提供者个数差不多,可传文件。
- 适用场景:常规远程服务方法调用,与原生RMI服务互操作
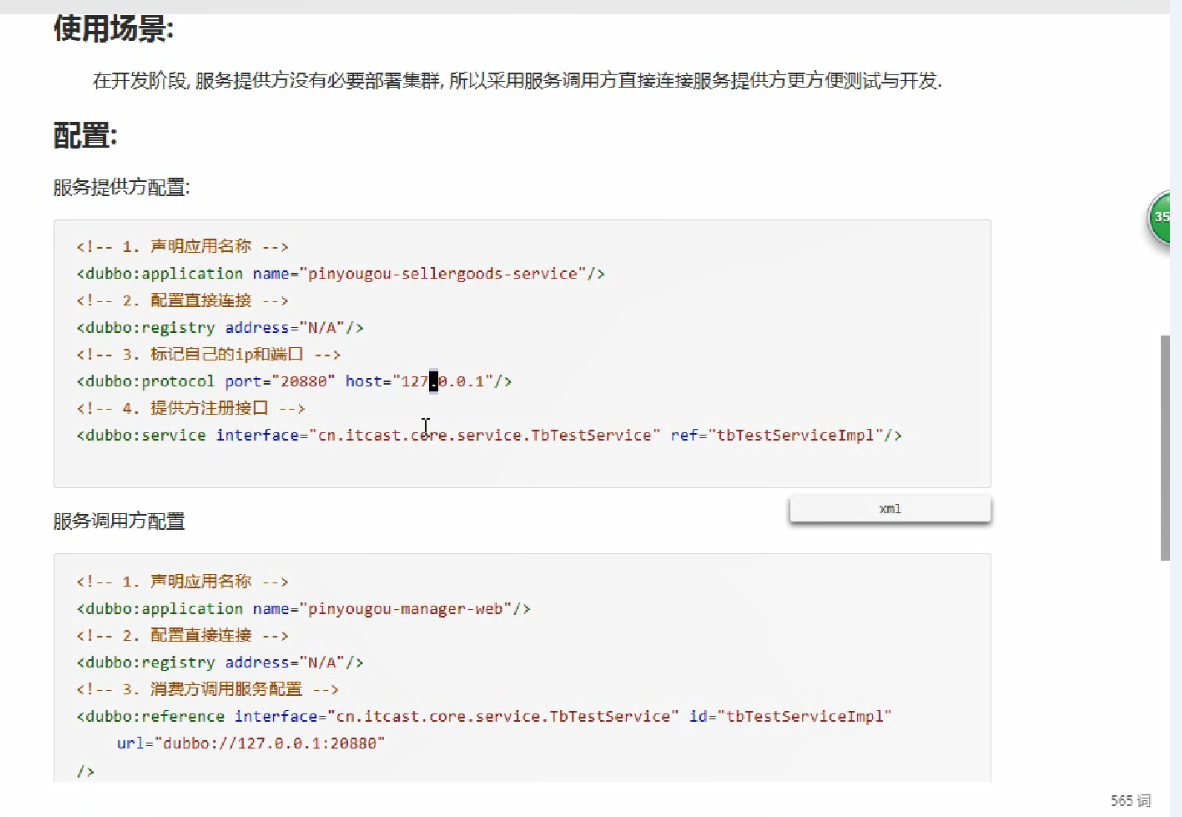
10、同一个服务多个注册的情况下可以直连某一个服务吗?
可以直连,修改配置即可,也可以通过telnet直接某个服务。
开发阶段就是直连的
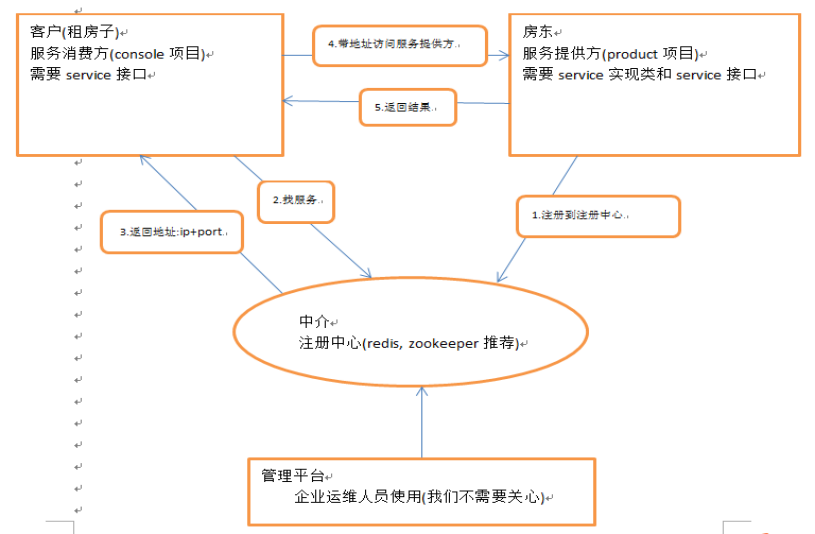
11、画一画服务注册与发现的流程图
12、集群容错怎么做?
读操作建议使用Failover失败自动切换,默认重试两次其他服务器。写操作建议使用Failfast快速失败,发一次调用失败就立即报错。
13、在使用过程中都遇到了些什么问题?
14、dubbo和dubbox之间的区别?
15、你还了解别的分布式框架吗?
1 面试题:Dubbo中zookeeper做注册中心,如果注册中心集群都挂掉,发布者和订阅者之间还能通信么?
可以的,启动dubbo时,消费者会从zk拉取注册的生产者的地址接口等数据,缓存在本地。每次调用时,按照本地存储的地址进行调用
注册中心对等集群,任意一台宕掉后,会自动切换到另一台
注册中心全部宕掉,服务提供者和消费者仍可以通过本地缓存通讯
服务提供者无状态,任一台 宕机后,不影响使用
服务提供者全部宕机,服务消费者会无法使用,并无限次重连等待服务者恢复
2 dubbo连接注册中心和直连的区别
在开发及测试环境下,经常需要绕过注册中心,只测试指定服务提供者,这时候可能需要点对点直连,
点对点直联方式,将以服务接口为单位,忽略注册中心的提供者列表,
服务注册中心,动态的注册和发现服务,使服务的位置透明,并通过在消费方获取服务提供方地址列表,实现软负载均衡和Failover, 注册中心返回服务提供者地址列表给消费者,如果有变更,注册中心将基于长连接推送变更数据给消费者。
服务消费者,从提供者地址列表中,基于软负载均衡算法,选一台提供者进行调用,如果调用失败,再选另一台调用。注册中心负责服务地址的注册与查找,相当于目录服务,服务提供者和消费者只在启动时与注册中心交互,注册中心不转发请求,服务消费者向注册中心获取服务提供者地址列表,并根据负载算法直接调用提供者,注册中心,服务提供者,服务消费者三者之间均为长连接,监控中心除外,注册中心通过长连接感知服务提供者的存在,服务提供者宕机,注册中心将立即推送事件通知消费者
注册中心和监控中心全部宕机,不影响已运行的提供者和消费者,消费者在本地缓存了提供者列表
注册中心和监控中心都是可选的,服务消费者可以直连服务提供者
3、Dubbo在安全机制方面是如何解决的
Dubbo通过Token令牌防止用户绕过注册中心直连,然后在注册中心上管理授权。Dubbo还提供服务黑白名单,来控制服务所允许的调用方
Dubbo简介
Dubbo |ˈdʌbəʊ|是一个由阿里巴巴开源的、分布式的RPC(Remote Procedure Call Protocol-远程过程调用)和微服务框架,现为Apache顶级项目。
Dubbo提供了三个关键功能:基于接口的远程调用,容错与负载均衡,服务自动注册与发现。
Dubbo使得调用远程服务就像调用本地java服务一样简单。
下图为Dubbo的结构图: 关于Dubbo的使用可以参考官方文档http://dubbo.apache.org ,本文不作赘述。
关于Dubbo的使用可以参考官方文档http://dubbo.apache.org ,本文不作赘述。
2. Dubbo服务暴露与消费过程
先来看下面问题:
1) Dubbo服务提供者发布服务的流程
2) Dubbo服务消费者消费服务的流程
3) 什么是本地暴露和远程暴露,他们的区别
Dubbo服务提供者发布服务过程:
先来看dubbo的启动日志: 图中从上到下框起来的日志分别是:
图中从上到下框起来的日志分别是:
1) 暴露服务到本地
2) 暴露服务到远程
3) 启动netty服务
4) 连接zookeeper
5) 注册服务到zookeeper
6) 监听zookeeper中消费服务
关于这个过程的实现细节可以参考Dubbo官方文档->实现细节->远程调用细节->服务提供者暴露一个服务的详细过程。截图如下: Dubbo服务消费者消费服务过程:
Dubbo服务消费者消费服务过程:
关于这个过程的实现细节可以参考Dubbo官方文档->实现细节->远程调用细节->服务消费者消费一个服务的详细过程。截图如下: 下面来看本地暴露于远程暴露的区别:
下面来看本地暴露于远程暴露的区别:
本地暴露是暴露在本机JVM中,调用本地服务不需要网络通信.
远程暴露是将ip,端口等信息暴露给远程客户端,调用远程服务时需要网络通信.
3. Dubbo相关协议
Dubbo 允许配置多协议,在不同服务上支持不同协议或者同一服务上同时支持多种协议。
不同服务在性能上适用不同协议进行传输,比如大数据用短连接协议,小数据大并发用长连接协议。
Dubbo支持的协议主要有:
dubbo:
Dubbo 缺省协议是dubbo协议,采用单一长连接和 NIO 异步通讯,适合于小数据量大并发的服务调用,以及服务消费者机器数远大于服务提供者机器数的情况。
反之,Dubbo 缺省协议不适合传送大数据量的服务,比如传文件,传视频等,除非请求量很低。rmi:
RMI协议采用阻塞式(同步)短连接和 JDK 标准序列化方式。适用范围:传入传出参数数据包大小混合,消费者与提供者个数差不多,可传文件。
hessian:
Hessian底层采用Http通讯(同步),采用Servlet暴露服务。适用于传入传出参数数据包较大,提供者比消费者个数多,提供者压力较大,可传文件。
dubbo还支持的其他协议有:http, webservice, thrift, memcached, redis
4. Dubbo相关配置
先看下面问题:
Dubbo主要的配置项有哪些,作用是什么?
如果Dubbo的服务端未启动,消费端能起来吗?
Dubbo主要配置项:
配置应用信息:
<dubbo:application name="app-provider" />
配置注册中心相关信息:
<dubbo:registryid="zk" protocol="zookeeper" address="127.0.0.1:2181" />
配置服务协议:
<dubbo:protocol name="dubbo" port="20880" threadpool="cached" threads="80" />
配置所有暴露服务缺省值:
<dubbo:provider registry="zk" protocol="dubbo" retries="0" version="1.0.0" timeout="3000" threadpool="cached" threads="4"/>
配置暴露服务:
<dubbo:service interface="" ref="" />
配置所有引用服务缺省值:
<dubbo:consumer check="false" timeout="1000" version="1.0" retries="0" async="false" />
配置引用服务:
<dubbo:reference id="" interface="" />
备注:其中reference的check默认=true,启动时会检查引用的服务是否已存在,不存在时报错
注解配置:
com.alibaba.dubbo.config.annotation.Service 配置暴露服务
com.alibaba.dubbo.config.annotation.Reference配置引用服务
第二篇


zookeeper 注册中心
Zookeeper 是 Apacahe Hadoop 的子项目,是一个树型的目录服务,支持变更推送,适合作为 Dubbo 服务的注册中心,工业强度较高,可用于生产环境,并推荐使用 1。

流程说明:
- 服务提供者启动时: 向
/dubbo/com.foo.BarService/providers目录下写入自己的 URL 地址 - 服务消费者启动时: 订阅
/dubbo/com.foo.BarService/providers目录下的提供者 URL 地址。并向/dubbo/com.foo.BarService/consumers目录下写入自己的 URL 地址 - 监控中心启动时: 订阅
/dubbo/com.foo.BarService目录下的所有提供者和消费者 URL 地址。
支持以下功能:
- 当提供者出现断电等异常停机时,注册中心能自动删除提供者信息
- 当注册中心重启时,能自动恢复注册数据,以及订阅请求
- 当会话过期时,能自动恢复注册数据,以及订阅请求
- 当设置
<dubbo:registry check="false" />时,记录失败注册和订阅请求,后台定时重试 - 可通过
<dubbo:registry username="admin" password="1234" />设置 zookeeper 登录信息 - 可通过
<dubbo:registry group="dubbo" />设置 zookeeper 的根节点,不设置将使用无根树 - 支持
*号通配符<dubbo:reference group="*" version="*" />,可订阅服务的所有分组和所有版本的提供者
3)Redis 注册中心

使用 Redis 的 Key/Map 结构存储数据结构:
- 主 Key 为服务名和类型
- Map 中的 Key 为 URL 地址
- Map 中的 Value 为过期时间,用于判断脏数据,脏数据由监控中心删除 3
使用 Redis 的 Publish/Subscribe 事件通知数据变更:
- 通过事件的值区分事件类型:
register,unregister,subscribe,unsubscribe - 普通消费者直接订阅指定服务提供者的 Key,只会收到指定服务的
register,unregister事件 - 监控中心通过
psubscribe功能订阅/dubbo/*,会收到所有服务的所有变更事件
调用过程:
- 服务提供方启动时,向
Key:/dubbo/com.foo.BarService/providers下,添加当前提供者的地址 - 并向
Channel:/dubbo/com.foo.BarService/providers发送register事件 - 服务消费方启动时,从
Channel:/dubbo/com.foo.BarService/providers订阅register和unregister事件 - 并向
Key:/dubbo/com.foo.BarService/providers下,添加当前消费者的地址 - 服务消费方收到
register和unregister事件后,从Key:/dubbo/com.foo.BarService/providers下获取提供者地址列表 - 服务监控中心启动时,从
Channel:/dubbo/*订阅register和unregister,以及subscribe和unsubsribe事件 - 服务监控中心收到
register和unregister事件后,从Key:/dubbo/com.foo.BarService/providers下获取提供者地址列表 - 服务监控中心收到
subscribe和unsubsribe事件后,从Key:/dubbo/com.foo.BarService/consumers下获取消费者地址列表
4)Simple 注册中心
Simple 注册中心本身就是一个普通的 Dubbo 服务,可以减少第三方依赖,使整体通讯方式一致。
三、集群容错
Failover Cluster
失败自动切换,当出现失败,重试其它服务器 1。通常用于读操作,但重试会带来更长延迟。可通过 retries="2" 来设置重试次数(不含第一次)。
重试次数配置如下:
<dubbo:service retries="2" />
或
<dubbo:reference retries="2" />
或
-
<dubbo:reference>
-
<dubbo:method name="findFoo" retries="2" />
-
</dubbo:reference>
Failfast Cluster
快速失败,只发起一次调用,失败立即报错。通常用于非幂等性的写操作,比如新增记录。
Failsafe Cluster
失败安全,出现异常时,直接忽略。通常用于写入审计日志等操作。
Failback Cluster
失败自动恢复,后台记录失败请求,定时重发。通常用于消息通知操作。
Forking Cluster
并行调用多个服务器,只要一个成功即返回。通常用于实时性要求较高的读操作,但需要浪费更多服务资源。可通过 forks="2" 来设置最大并行数。
Broadcast Cluster
广播调用所有提供者,逐个调用,任意一台报错则报错 2。通常用于通知所有提供者更新缓存或日志等本地资源信息