传统web请求流程
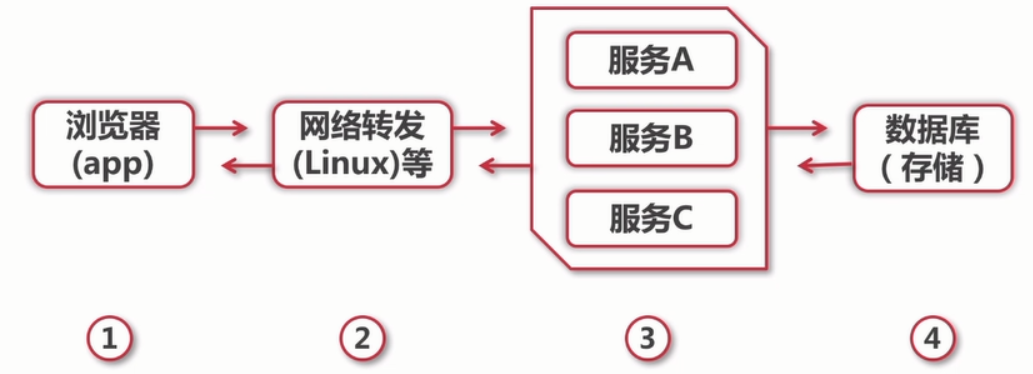
一般来说,现在的互联网应用网站或者APP,它的整体流程可以用我们这个图里展示的来表示,用户请求开始,从这个界面是最里面的浏览器和APP,到网络转发,再到应用服务,最后到存储,这纯属可能是数据库文件系统,然后再返回到界面呈现内容。
随着互联网的普及,内容信息越来越复杂,用户数和访问量越来越大,我们的应用需要支撑更多的并发量,同时,我们的应用服务器和数据库服务器所做的计算也越来越多,但是,往往我们的应用服务器的资源是有限的,而且技术变革是缓慢的,所以每秒能接收请求次数也是有限的,或者说文件的读写也是有限的。
如何能有效利用有限的资源来提供尽可能大的吞吐量呢?一个有效的办法就是引入缓存,打破图中的标准的流程,每个环节中请求可以从缓存中直接获取目标数据并返回,从而减少他们的计算量,来有效提升响应速度,让有限的资源服务更多的用户,像我们这个图里展示的缓存的使用,它其实可以出现在1到4的各个环节中。
缓存的特征
1.命中率:命中数/(命中数+没有命中数)
首先是命中,命中的还可以简单的理解为直接通过缓存获得到需要的数据,有了命中就有不命中,无法通过缓存的获取想要的数据,需要再次查询数据库,或者执行其他操作,原因可能是缓存中根本不存在,或者缓存已经过期了。
通常 命中率=命中数/(命中数+没有命中数) 来表达,能力越高,表示我们使用缓存的收益越高,应用的性能越好,这时候响应的时间会越短,吞吐量越来越高,抗并发的能力也越强,由此可见在高并发的互联网系统中,命中率是至关重要的一个指标。
2.最大元素(空间)
它代表的是缓存中可以存放的最大元素的数量,一旦缓存数量超过这个值,或则所占的空间,超过了最大支持的空间,就会促发缓存清空策略,根据不同的场景合理的设置最大元素值,往往可以一定程度上提高缓存的命中率,从而更有效的使用缓存。
像我们刚才所描述的,缓存的存储空间是有限制的,当缓存空间满时,如何保证在稳定服务的同时有效的提高命中率呢?这就有缓存的清空策略来处理,适合自身数据特征的清空策略,能有效的提高命中率。常见的清空策略为下面所示
3.清空策略:FIFO,LFU,LRU,过期时间,随机等
FIFO(First In First out)先进先出策略:是指最先进入缓存的数据,在缓存空间不够的情况下,或者超出最大源头限制的时候,会优先被清除掉,以腾出新的空间来接受新的数据,这个策略算法主要是比较缓存元素的创建时间,在数据实时性要求严格下,可以选择该类策略,优先保障最新数据可用。
LFU(Least frequently used):是指无论是否过期,根据元素的被使用次数来判断,清除使用次数最少的元素来释放空间,这个策略的算法主要比较的元素的命中次数,在保证高频率场景下,可以选择这里策略。
LRU(Least recently used): 是指无论是否过期,根据元素最后一次被使用的时间戳,清除最原始用时间戳的元素释放空间,主要比较元素的最近一次被get使用时间,在热点数据场景下优先保证热点数据的有效性
除此之外呢,还有一些简单的策略,比如根据过期时间来判断,清理过期时间最长的元素,还可以根据过期时间判断清理最近要过期的元素,以及随机清理等等。
4.影响缓存命中率的因素
a.业务场景和业务需求
缓存适合读多写少的业务场景,反之使用缓存的意义并不大,命中率还会很低,业务需求也决定了对实时性的要求,直接影响到缓存的过期时间和更新策略,实时性要求越低,就越适合缓存,在相同key和相同请求数的情况下,缓存时间越长命中率就会越高,我们目前遇到的互联网应用,大多数的业务场景下都是很适合使用缓存的。
b.缓存的设计(粒度和策略)
通常情况下呢,缓存的粒度越小,命中率就会越高,当换成单个对象的时候,比如单个用户信息,只有当该对象的对应的数据发生变化时后,我们才需要更新缓存或者移除缓存,而当缓存一个集合的时候,我们要获得所有用户数据,其中任何一个对象对应的数据发生变化时,我们都需要更新或移除缓存,还有另一个情况,假设其他地方也需要获取该对象对应的数据时,比如说其他地方也需要获取单个用户信息,如果缓存的是单个对象,那么就可以直接命中缓存,否则的话就无法直接命中。
c.缓存容量和基础设施
缓存容量有限就会引起缓存失效和淘汰,目前多个缓存中间件多采用LRU算法。技术选型也很重要,建议采用分布式缓存。
5.缓存分类和应用场景
a.本地缓存
实现方式:编程实现(成员变量、局部变量、静态变量)、Guava Cache
优点:是应用进程的cache是在同一个进程中内部请求缓存非常的快速,没有过多的网络开销。
缺点:是各个应用要单独维护自己的缓存,无法共享。在单应用中使用较为好。
b.分布式缓存
实现方式:Memcache, Redis
优点:是自身是一个独立的应用,与本地应用是隔离的,多个应用可以共享。
Guava Cache

Memcache

Redis
更多redis知识参阅:https://www.cnblogs.com/shamo89/tag/redis/
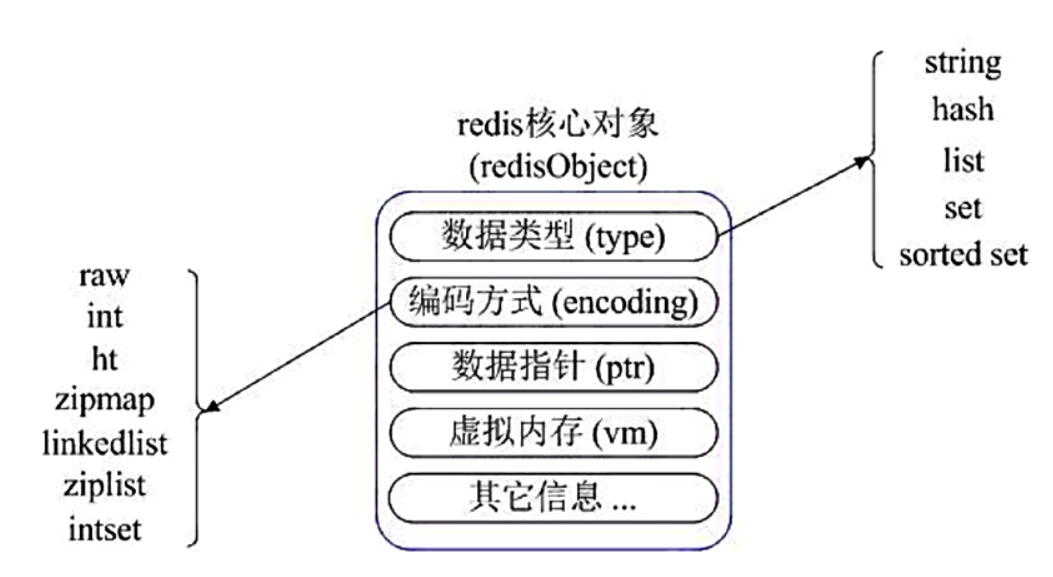
高并发场景下缓存常见问题
1.缓存一致性
当数据时效性要求很高时,需要保证缓存中的数据与数据库中的保持一致,而且需要保证缓存节点和副本中的数据也保持一致,不能出现差异现象。这就比较依赖缓存的过期和更新策略。一般会在数据发生更改的时,主动更新缓存中的数据或者移除对应的缓存。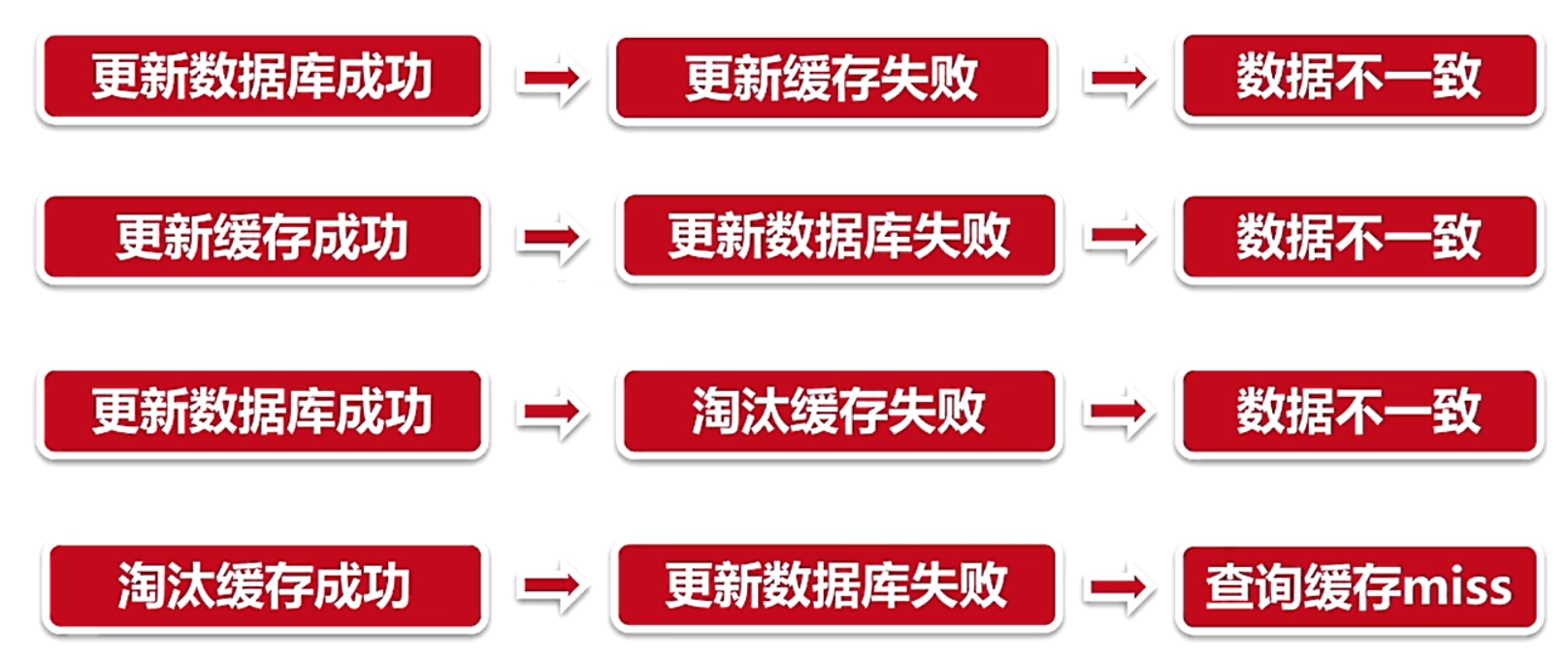
2.缓存并发问题
缓存过期后将尝试从后端数据库获取数据,这是一个看似合理的流程。但是,在高并发场景下,有可能多个请求并发的去从数据库获取数据,对后端数据库造成极大的冲击,甚至导致 “雪崩”现象。此外,当某个缓存key在被更新时,同时也可能被大量请求在获取,这也会导致一致性的问题。那如何避免类似问题呢?我们会想到类似“锁”的机制,在缓存更新或者过期的情况下,先尝试获取到锁,当更新或者从数据库获取完成后再释放锁,其他的请求只需要牺牲一定的等待时间,即可直接从缓存中继续获取数据。
3.缓存穿透问题
缓存穿透在有些地方也称为“击穿”。很多朋友对缓存穿透的理解是:由于缓存故障或者缓存过期导致大量请求穿透到后端数据库服务器,从而对数据库造成巨大冲击。
这其实是一种误解。真正的缓存穿透应该是这样的:
在高并发场景下,如果某一个key被高并发访问,没有被命中,出于对容错性考虑,会尝试去从后端数据库中获取,从而导致了大量请求达到数据库,而当该key对应的数据本身就是空的情况下,这就导致数据库中并发的去执行了很多不必要的查询操作,从而导致巨大冲击和压力。
可以通过下面的几种常用方式来避免缓存穿透问题:
a.缓存空对象
对查询结果为空的对象也进行缓存,如果是集合,可以缓存一个空的集合(非null),如果是缓存单个对象,可以通过字段标识来区分。这样避免请求穿透到后端数据库。同时,也需要保证缓存数据的时效性。这种方式实现起来成本较低,比较适合命中不高,但可能被频繁更新的数据。
b.单独过滤处理
对所有可能对应数据为空的key进行统一的存放,并在请求前做拦截,这样避免请求穿透到后端数据库。这种方式实现起来相对复杂,比较适合命中不高,但是更新不频繁的数据。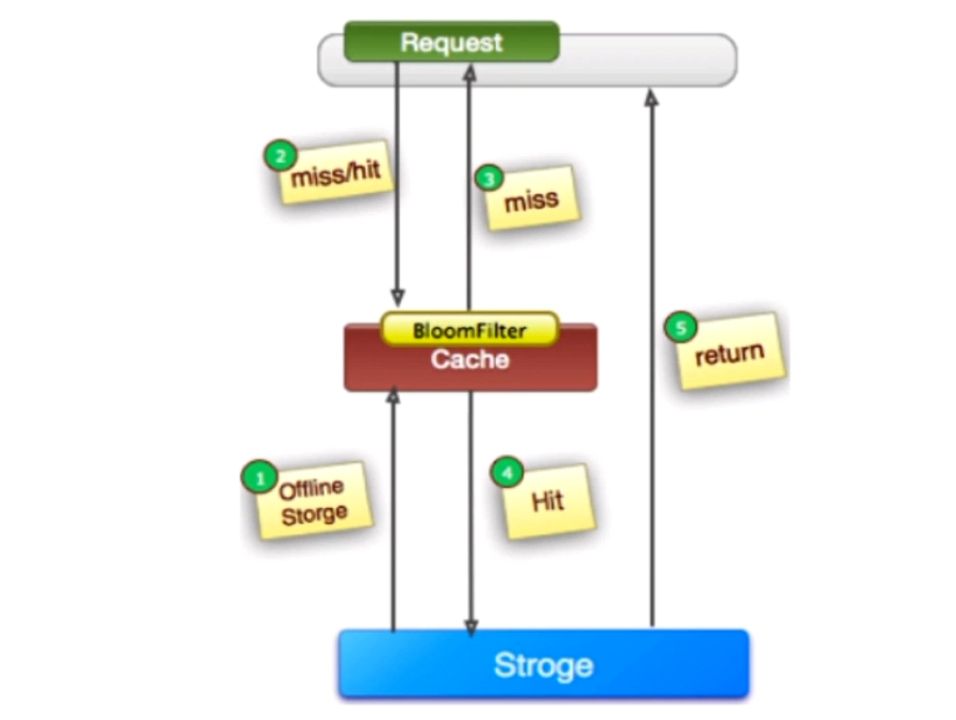
4.缓存的雪崩现象
缓存雪崩就是指由于缓存的原因,导致大量请求到达后端数据库,从而导致数据库崩溃,整个系统崩溃,发生灾难。导致这种现象的原因有很多种,上面提到的“缓存并发”,“缓存穿透”,“缓存颠簸”等问题,其实都可能会导致缓存雪崩现象发生。这些问题也可能会被恶意攻击者所利用。还有一种情况,例如某个时间点内,系统预加载的缓存周期性集中失效了,也可能会导致雪崩。为了避免这种周期性失效,可以通过设置不同的过期时间,来错开缓存过期,从而避免缓存集中失效。
从应用架构角度,我们可以通过限流、降级、熔断等手段来降低影响,也可以通过多级缓存来避免这种灾难。此外,从整个研发体系流程的角度,应该加强压力测试,尽量模拟真实场景,尽早的暴露问题从而防范。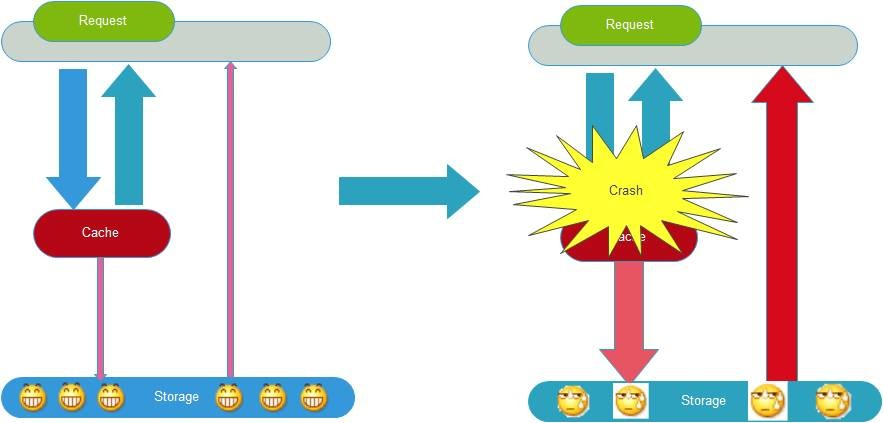
5.缓存无底洞现象
该问题由 facebook 的工作人员提出的, facebook 在 2010 年左右,memcached 节点就已经达3000 个,缓存数千 G 内容。他们发现了一个问题—memcached 连接频率,效率下降了,于是加 memcached 节点,添加了后,发现因为连接频率导致的问题,仍然存在,并没有好转,称之为”无底洞现象”。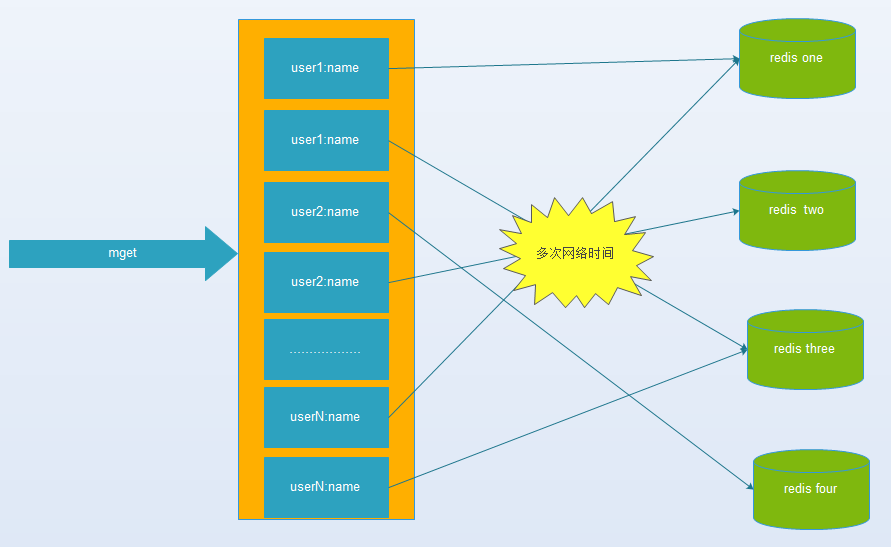
目前主流的数据库、缓存、Nosql、搜索中间件等技术栈中,都支持“分片”技术,来满足“高性能、高并发、高可用、可扩展”等要求。有些是在client端通过Hash取模(或一致性Hash)将值映射到不同的实例上,有些是在client端通过范围取值的方式映射的。当然,也有些是在服务端进行的。但是,每一次操作都可能需要和不同节点进行网络通信来完成,实例节点越多,则开销会越大,对性能影响就越大。
主要可以从如下几个方面避免和优化:
- 数据分布方式:有些业务数据可能适合Hash分布,而有些业务适合采用范围分布,这样能够从一定程度避免网络IO的开销。
- IO优化:可以充分利用连接池,NIO等技术来尽可能降低连接开销,增强并发连接能力。
- 数据访问方式:一次性获取大的数据集,会比分多次去获取小数据集的网络IO开销更小。
当然,缓存无底洞现象并不常见。在绝大多数的公司里可能根本不会遇到。
Redis在股票分时K线图计算的实践
来公司第一个比较大的业务需求,便是换了新的行情提供商,需要把所有K线的处理都重新倒腾一遍。这里说说重写分时K线图的一点心得。
先交代一下数据提供商的情况:
1)股票分时数据采用订阅的方式,可以订阅历史数据
2)每分钟每只股票可能会接收到多条分时数据,也可能一条不推。有些股票在开市过程中每分钟都会有分时数据,有些股票则一个交易日只有几条数据,甚至没有,差别很大
3)推送的分时数据有延迟,从监控获得数据,开市期间大约在60s-120s左右(分时数据看的是趋势,这是可以忍受的)
4)每个订阅对实时数据有qps限制,对历史数据无qps限制(从监控上得到的)
再交代一下股票分时K线数据的情况:
1)股票数目为8500+(美股相关)
2)每只股票1个交易日的分时线包含391条数据(9:30-16:00, America/New_York),每条数据包含这一分钟的最高价、最低价、均价、昨收价、涨幅、交易量、VWAP等,数据量在150k左右
3)每天存储的分时数据在120w条左右
4)股票分时线如果某一分钟没有点,使用上一分钟的点代替,但无交易量
接下来重点说一下这里的设计:(以AAPL为例)
1)由于分时数据有延迟,无法确定每一分钟的最后一条数据什么时候会来到。因此开市期间并不去保存分时数据。实时的分时数据存储在redis中,计算K线时从redis中取
2)redis中分时数据的存储格式为hash结构,每只股票一个key,为了防止当前交易日使用上个交易日的数据,因此分时数据缓存时是包含日期的,比如:TMT_AAPL0105, key为美东时间,格式:HHmm, value为简单计算后的分时数据。上一个交易日的分时数据通过定时任务在指定时间清理。(这里没有对分时数据做过期设置,是因为刚开市时数据推送量及redis操作量很大,而使用hashes这个结构,是不支持直接传入expire time的,同时即使某天系统出什么问题,也只是多占些硬盘的问题,不会对其他造成影响,对这个操作添加监控及报警就可以了)
3)结构有了,如果第三方数据提供商每次都推送数据过来时,都去操作redis更新,那样redis很可能会吃不消,谁都无法晓得第三方是否会出什么问题疯狂推送一下(事实证明,第三方数据提供商也确实这样有过,可能因网络故障等补偿推送历史数据)。接下来是缓存的的重点:在内存中通过guava cache缓存了最近几分钟的所有symbol的最新数据,key: 股票+HHmm(美东时间), value:一条分时数据,每次推送分时数据过来时,根据股票及分时数据时间进行cache,过期数据(很久以前或非最新数据)或脏数据(相关数据为NaN)直接抛弃,然后通过ScheduledExecutorService维护一个1分钟1执行的job去将最近几分钟的分时数据更新到redis中。这样既解决了分时数据有延迟的问题,又保证了每分钟的redis更新数据量。
4)数据存储结束后,就是处理分时K线的数据了。当请求AAPL时,会先查看是否已经有cache了,比如C_TT_AAPL, 如果有取出cache中数据处理后返回,没有开始计算。计算会先取出上面存储的数据,即TMT_AAPL0105,然后计算当前k线的时间点(开市过程中从1个点慢慢增长到391个点),遍历HHmm去TMT_AAPL0105中取分时数据,如果有直接取出即可,如果没有使用上一个点生成(第一个记得特殊处理一下,没有需要拿上个交易日最后一个点补),计算完后转成json放到redis中,key为计算前查询的key: C_TT_AAPL,然后将结果返回。开市过程中缓存到下一分钟开始,闭市了缓存到下个交易日开始。由于这里缓存的是string,因此直接带上过期时间,之后就不用care了。如此,最核心的分时K线数据绝大部分都是在操作redis,每只股票每分钟只需要计算一次即可,当然这是基于分时K线主要看的是趋势。
5)上面说了,分时数据可以拿历史数据。这里我单独写了一个job,可以在给定开始时间后,取出期望的历史数据,然后更新历史分时数据。当实时推送出问题时,这个job可以用来在秒级获取历史数据来修复redis中的分时数据。实际上,这个job在故障中的表现远远超出预期,之前因为对实时那里做优化,几次都有点问题导致开市后实时数据获取或处理有问题,这时候启动这个拿历史分时的job,几秒内就可以保证redis中的数据变成最新,保证核心的分时图数据一直ok。
6)说到这里,分时数据还没保存。这里借助上面拿历史数据的job,在闭市后(北京时间凌晨5点以后)自动执行,更新redis中数据后开始插入数据库。由于插入量特别大,通过guava的RateLimiter控制写入速度在合理的qps值,慢慢更新就好啦
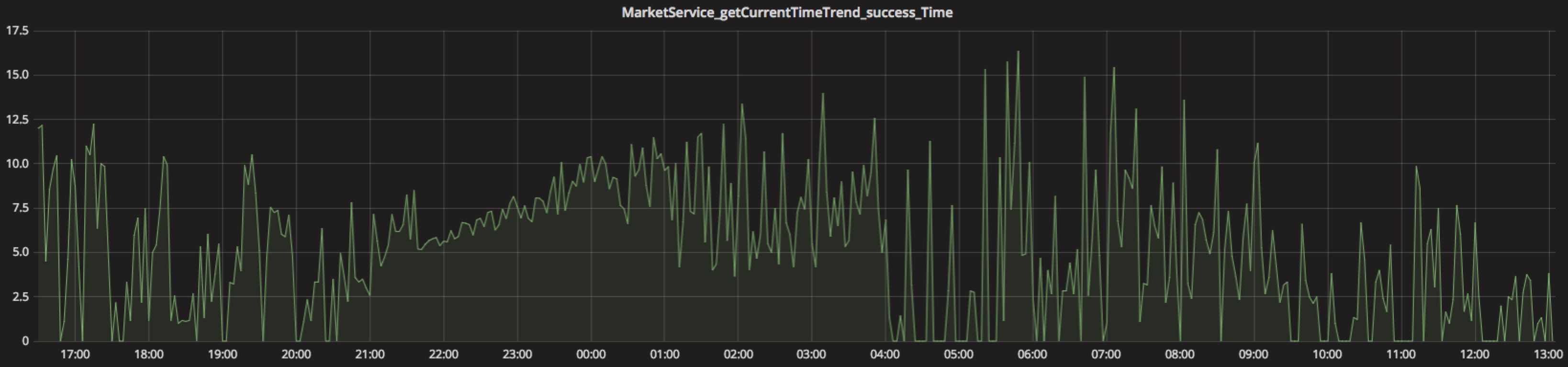
当然这不是全部,还有些细节,比如动态增加股票,就不多说了。此外,我单独补了许多核心监控,比如定时任务是否正常执行、读取及更新redis时间、开市期间推送的qps、计算分时K线平均时间、平均每分钟推送不同股票数目等等,目前达到的结果是:docker上部署的2个4g的服务来处理所有K线图,分时K线图数据可以在平均10ms左右返回,大量的分时数据在低峰时间端插入,服务器在开市闭市都没什么压力。