mysql分库分表也就是分片(sharding):分为垂直分片和水平分片
市面上常见的的分库分表中间件有:
client模式:
当当 sharding-jdbc(现在是社区了)
蘑菇街TSharding
proxy模式:
sharding
TDDL Smart Client的方式(淘宝)
Atlas (Qihoo 360)
alibaba.cobar(是阿里巴巴(B2B)部门开发)
MyCAT(基于阿里开源的Cobar产品而研发)
Oceanus(58同城数据库中间件)
OneProxy(支付宝首席架构师楼方鑫开发)
vitess(谷歌开发的数据库中间件)
drds是阿里云最近推出的商业产品
从中选三款有代表的产品做个介绍:
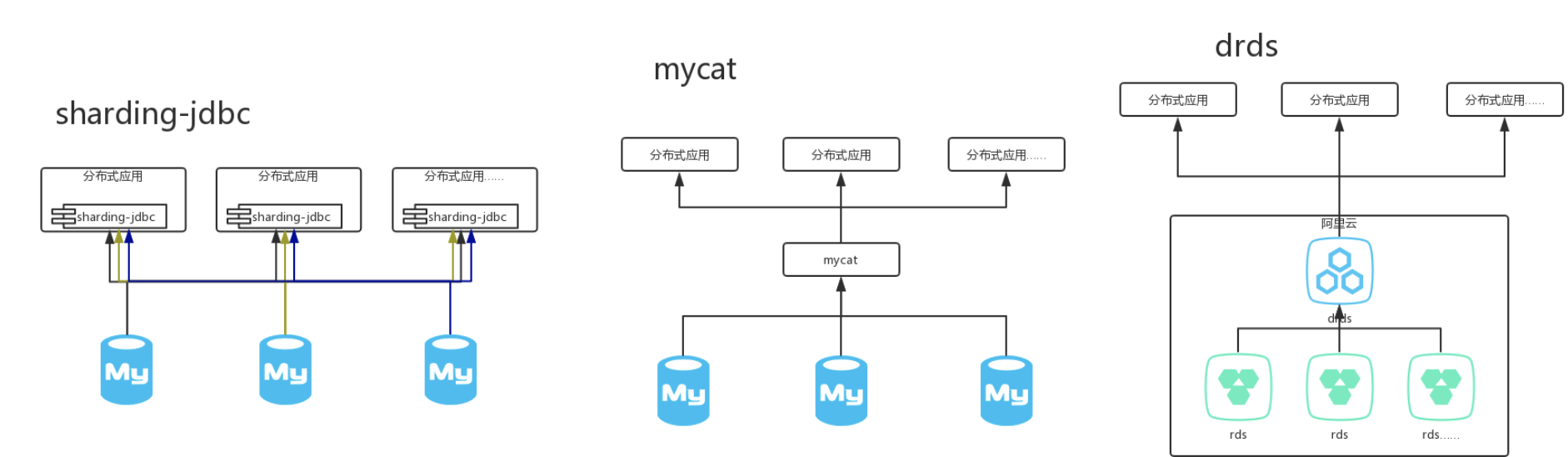
可以看出sharding-jdbc作为一个组件集成在应用内,而mycat则作为一个独立的应用需要单独部署,drds则是阿里云的一个独立产品,不过需要结合rds一起使用。

上面几款产品总结来说不外乎两种模式,client模式,proxy模式,核心的步骤是一样的:SQL解析,重写,路由,执行,结果归并。
client模式,它架构简单,性能损耗也比较小,运维成本低。
mycat的单机模式无法保证可靠性,一旦宕机则服务就变得不可用,你又不得不引入HAProxy来实现它的高可用集群部署方案, 为了解决HAProxy的高可用问题,又需要采用Keepalived来实现。
1、client模式是应用层依赖类中间件
这类分库分表中间件的特点就是和应用强耦合,需要应用显示依赖相应的jar包(以Java为例),比如知名的TDDL、当当开源的sharding-jdbc、蘑菇街的TSharding、携程开源的Ctrip-DAL、支付宝开源但比较低调的zdal等,易宝支付自已研发的DAL组件;
在基本不改变业务代码的情况下透明地实现分库分表的能力。中间件给上层应用提供熟悉的JDBC API,内部通过sql解析、sql重写、sql路由等一系列的准备工作获取真正可执行的sql,然后底层再按照传统的方法(比如数据库连接池)获取物理连接来执行sql,最后把数据结果合并处理成ResultSet返回给应用层。
此类中间件的优点很明显,就是无需额外部署,只要和应用绑定一起发布即可,但是缺点也很明显,就是不能跨语言,比如Java写的sharding-jdbc显然不能用在C#项目中,所以携程的dal也要重新写一套C#的客户端。
2、proxy模式中间件
这类分库分表中间件的核心原理是在应用和数据库的连接之间搭起一个代理层,上层应用以标准的MySQL协议来连接代理层,然后代理层负责转发请求到底层的MySQL物理实例,这种方式对应用只有一个要求,就是只要用MySQL协议来通信即可,所以用MySQL Workbench这种纯的客户端都可以直接连接你的分布式数据库,自然也天然支持所有的编程语言。比较有代表性的产品有开创性质的Amoeba、阿里开源的Cobar、社区发展比较好的Mycat 等。
在技术实现上除了和应用层依赖类中间件基本相似外,代理类的分库分表产品必须实现标准的MySQL协议,某种意义上讲数据库代理层转发的就是MySQL协议请求,就像Nginx转发的是Http协议请求。
上述无论哪种类型的产品,除了实现分库分表这一主要功能外,都会额外实现一些其他很有实用价值的功能,比如读写分离、负载均衡等。
判断一款数据库中间件的优劣,一方面有一些通用的指标,另一方面还是要结合业务特点,包括业务的读写 qps , 涉及的库表结构和SQL语句,来进行综合的判断。
应该包括这几个方面:
1. 基本的功能是否完善。数据库中间件的两个主要功能是分库分表和读写分离,一般的数据库中间件,都满足。但是再进一步剖析,分库分表和读写分离,还是有不少细节需要去研究的。
比如,
分库分表功能是能够做到一级划分(只根据一个字段来做分区),还是能够做到二级划分(能够根据两个字段来做分区),划分的形式是否多样(常见有 range、list、hash 方式),划分字段的类型是否能支持多种(比如是只支持根据数值类型字段做划分,还是可以根据数值、字符串、日期类型做划分)。能否提供避免数据倾斜的分区方式等。
对于读写分离功能,细分来看,也包括两种,一种是透明的读写分离,这种功能能够100%兼容 Mysql 或其他数据库的 SQL 语法,同时对于事务也能够正确处理(事务的 SQL 能够路由到主节点,而不是分散到主节点和只读节点); 另一种是简单的读写分离,对 SQL 的支持范围,只限于数据库中间件内置的 SQL 解释器,有些复杂 SQL 是支持不了的,同时对于事务,也做不到很好的支持。
同时,对读请求的分流策略,也是读写分离功能一个考量点。简单的读写分离功能只是把写发往主节点,读都发往从节点; 而读写分离功能做得细致的话,数据库中间件会能够提供对分流策略的自定义。比如设置为:把30%的读流量,分流到主节点,70%的读流量分流到只读节点。
2. 产品的成熟度、用户的使用情况和社区(商业公司)支持程度。 数据库中间件虽然本身不做存储,但是每条数据都是要从中经过的,一旦出错,可能对业务造成灾难性的影响,所以软件的正确性和稳定性非常重要。为此,中间件的成熟度、已经使用的客户的使用情况、数量、用户的口碑,以及开源社区或者商业公司对该产品的支持程度,就非常重要。一般来说,发布时间越长而且在持续迭代、用户使用数量众多,且有大规模业务使用,社区(包括 QQ 群)比较活跃,文档完善,bug 解决及时的产品,更值得信赖。
3. 产品的易用性,是否配置方便,部署容易,系统管理不会有太大负担。有些中间件模块众多,配置复杂,虽然表面上看起来功能丰富,但业务用到的可能还是最基本的几个功能。选择这样的中间件,即显得不够划算,不仅加重运维负担,同时后续系统的扩展,新业务的支持,也不够敏捷。
4. 是否满足自身业务目前的需求,和潜在的需求。 除了上述两个通用的指标,更重要的是必须根据自己业务的库表结构,分库分表/读写分离需求,业务的SQL语句,读写qps,来判断中间件产品的优劣。
比如,绝大部分中间件,目前都不能支持分布式事务和多表join,但是除了对这两种sql不支持,不少中间件,其实在一些基本的sql,比如带系统函数的sql、聚合类sql上,也支持不够好。为此,在选择中间件时,就需要根据业务的库表结构,sql语句,以及业务特点,去检查中间件是否对业务的目前sql和潜在sql,能够做到比较好的支持。
另外,选择中间件时,一定要自己做性能测试和压力测试,实事求是地自身业务特点来测定中间件的性能和稳定性情况,不要轻信官方或者第三方发布的一些性能数据。