1.树
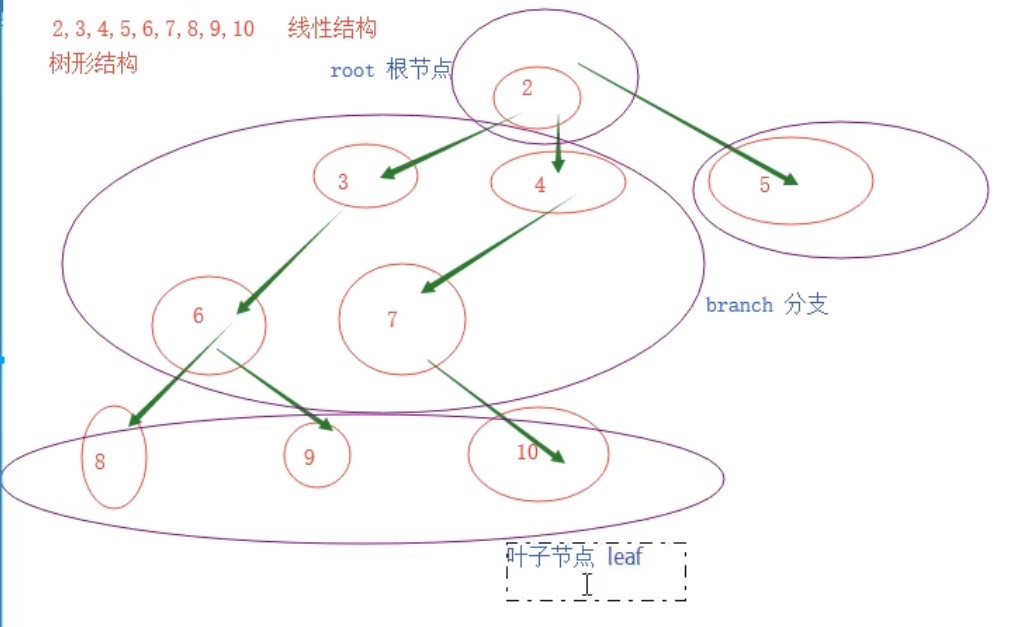
根结点 : 2 root
父节点 : 2是3,4,5的父节点
分支: 3,4,6,7 branch
叶子节点:8,9,10是叶子节点 leaf
树的深度/树的高度:高度为3
1.二叉树
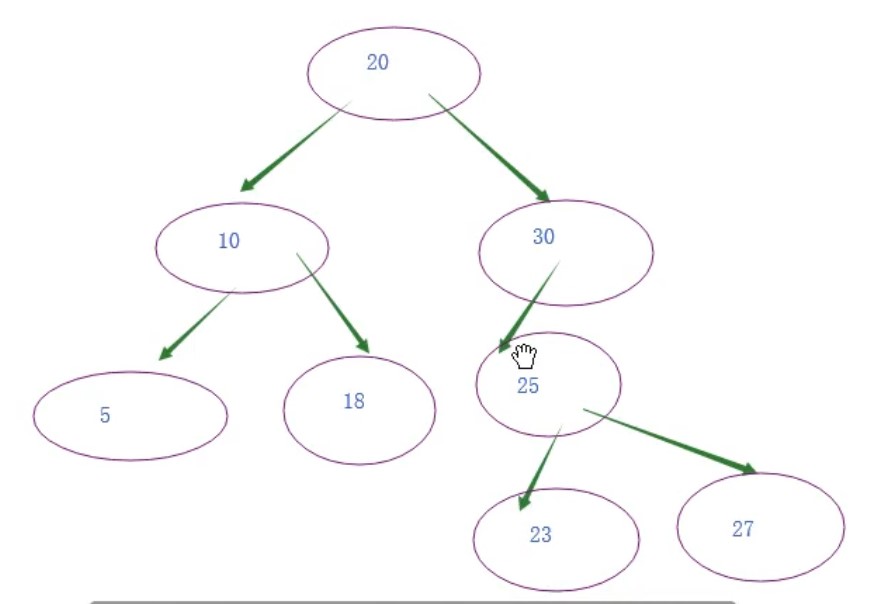
2.平衡树
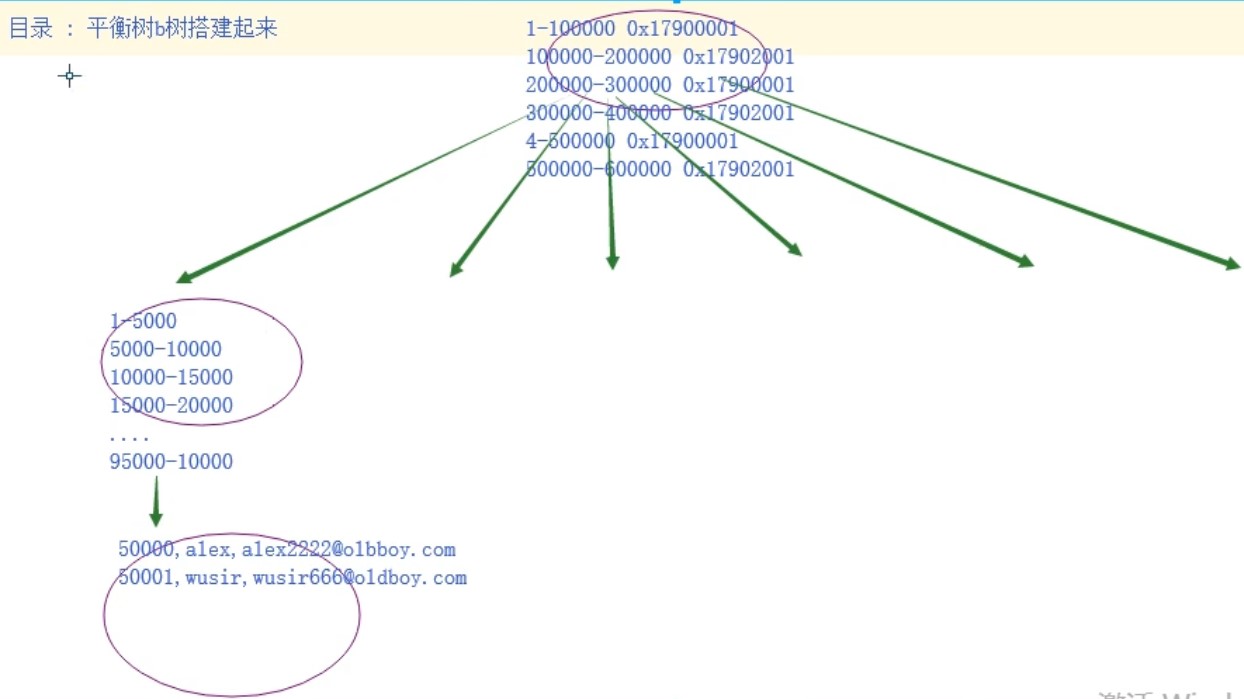
能够让查找每一个数据经历的I/O次数尽量平衡
balance tree:简称b树
平衡树不一定是二叉树
为什么不用二叉树 :因为二叉树存储的数据太少了
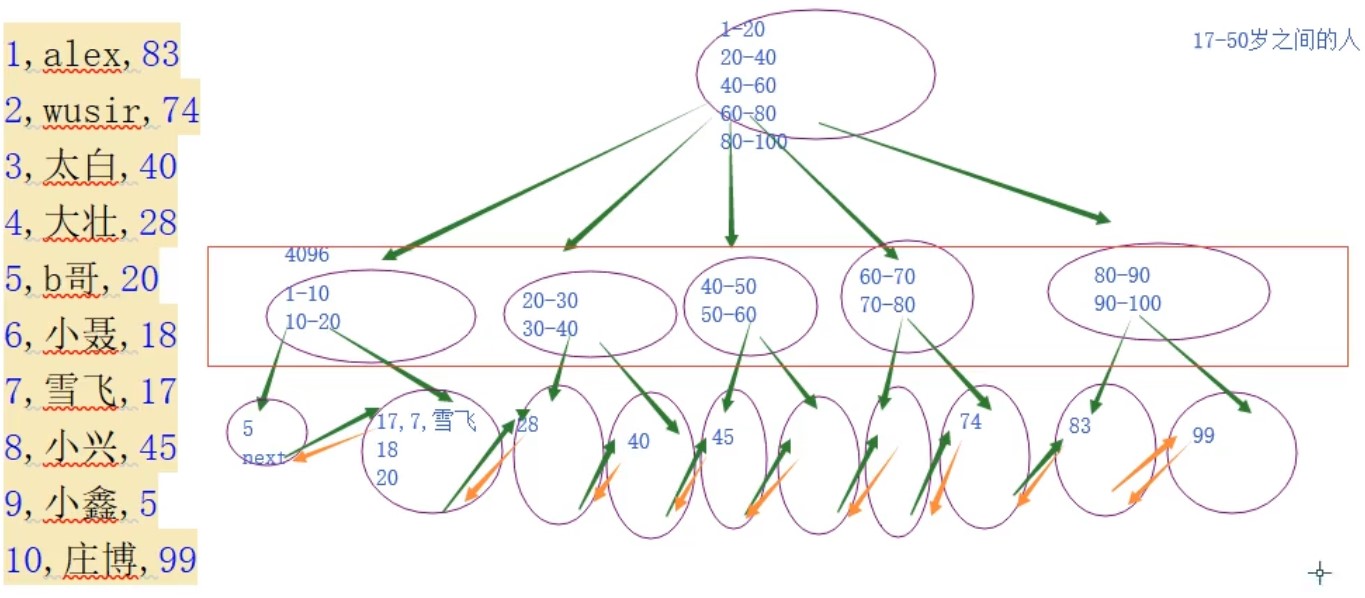
3.b+树
1.能够让查找每一个数据经历的I/O次数尽量平衡;
2.分支节点不存储数据—让树的高度尽量矮,让查找一个数据的效率尽量的稳定;
3.在所有叶子节点之间加入了双向的地址链接—查找范围非常快;
2.聚集索引&非聚集索引
1.两种索引的差别
聚集索引,聚簇索引:全表数据都存储在叶子节点上
innodb必有且仅有一个:主键
innodb存储引擎中的主键默认就会创建一个聚集索引,如果没有创建主键,innodb自动隐藏式的给数据添加主键;
将主键组织到一棵B+树中,而行数据就储存在叶子节点上,若使用"where id = 14"这样的条件查找主键,则按照B+树的检索算法即可查找到对应的叶节点,之后获得行数据。若对Name列进行条件搜索,则需要两个步骤:第一步在辅助索引B+树中检索Name,到达其叶子节点获取对应的主键。第二步使用主键在主索引B+树种再执行一次B+树检索操作,最终到达叶子节点即可获取整行数据。
非聚集(簇)索引,辅助索引:叶子节点不存放具体的整行数据,而是存储的这一行的主键的值:
MyISM使用的是非聚簇索引,非聚簇索引的两棵B+树看上去没什么不同,节点的结构完全一致只是存储的内容不同而已,主键索引B+树的节点存储了主键,辅助键索引B+树存储了辅助键。表数据存储在独立的地方,这两颗B+树的叶子节点都使用一个地址指向真正的表数据,对于表数据来说,这两个键没有任何差别。由于索引树是独立的,通过辅助键检索无需访问主键的索引树。
2.索引的创建与删除
创建主键: primary key 聚集索引 + 非空 +唯一
创建唯一约束: unique 辅助索引 + 唯一
添加一个普通索引
创建索引: create index 索引名 on 表(字段)
create index 索引名 on 表(字段1,字段2)
删除索引: drop index 索引名 on 表名字;
3.正确的使用索引
1.从库的角度
a.搭建集群
b.读写分离
c.分库
2.从表的角度
a.合理安排表与表之间的关系:该拆的拆,该合的合
b.把固定长度的字段放在前面
c.尽量使用char而不是varchar
3.从操作数据的角度
a.尽量在where字段就约束数值到一个比较小的范围:分页 where a between value1 and value2
b.尽量使用连表查询代替子查询
c.删除数据和修改数据的时候条件尽量使用主键
4.合理的创建和使用索引
a.创建索引
选择区分度比较大的列
尽量选择短的字段创建索引
不要创建不必要的索引,及时删除不用的索引
b.使用索引
①查询的字段不是索引字段
②在条件中使用范围,结果的范围越大速度越慢,范围小的快
③like’a%’命中索引,like’%a’不命中索引
④条件列不能参与计算不能使用函数
⑤and/or
and条件相连 有一列有索引都会命中
or条件相连 所有列都有索引才能命中
⑥联合索引
遵循最左前缀原则, 必须带着最左边的列做条件,且从出现范围开始索引失效

⑦条件中的数据类型和实际字段的类型必须一致
⑧select字段中应该包含order by中的字段
select age from 表 order by age ; 快
select name from 表 order by age ; 慢