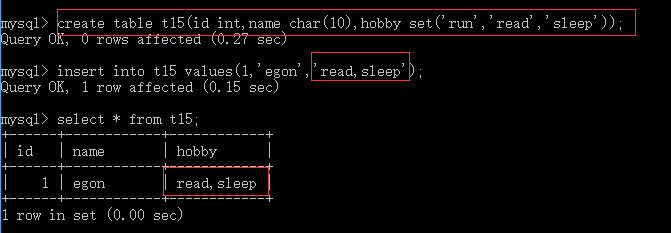
一、配置文件
服务端和客户端的字符编码不一样时,可能会导致乱码显示等情况,为了统一两端的字符编码,可以通过配置文件进行实现,当然譬如登录账户等信息也可以进行配置,在启动mysql服务端时会自动读取配置文件中的内容。配置文件(my.ini)必须建在解压的mysql文件下,具体配置文件的格式如下:
#1. 在执行mysqld命令时,下列配置会生效,即mysql服务启动时生效 [mysqld] skip-grant-tables #跳过授权表命令 port=3306 character_set_server=utf8 #设置字符编码命令 default-storage-engine=innodb #设置存储引擎命令 innodb_file_per_table=1 #2. 针对客户端命令的全局配置,当mysql客户端命令执行时,下列配置生效 [client] port=3306 default-character-set=utf8 user=root password=123 #3. 只针对mysql这个客户端的配置,2中的是全局配置,而此处的则是只针对mysql这个命令的局部配置 [mysql] ;port=3306 ;default-character-set=utf8 user=egon password=4573 #!!!如果没有[mysql],则用户在执行mysql命令时的配置以[client]为准
二、存储引擎
存储引擎说白了就是如何存储数据、如何为存储的数据建立索引和如何更新、查询数据等技术的实现方法。因为在关系数据库中数据的存储是以表的形式存储的,所以存储引擎也可以称为表类型(即存储和操作此表的类型)。在Oracle 和SQL Server等数据库中只有一种存储引擎,所有数据存储管理机制都是一样的。而MySql数据库提供了多种存储引擎。用户可以根据不同的需求为数据表选择不同的存储引擎,用户也可以根据自己的需要编写自己的存储引擎。
1、mysql支持的存储引擎
查看mysql支持的存储引擎的命令:show enginesG,查看正在使用的存储引擎命令:show variables like 'storage_engine%';。mysql默认使用的是InnoDB存储引擎。
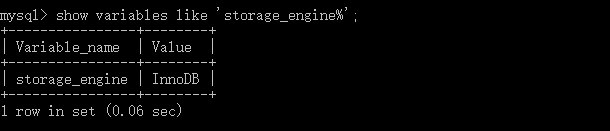
mysql支持的存储引擎分别介绍如下:
#InnoDB 存储引擎 支持事务,其设计目标主要面向联机事务处理(OLTP)的应用。其 特点是行锁设计、支持外键,并支持类似 Oracle 的非锁定读,即默认读取操作不会产生锁。 从 MySQL 5.5.8 版本开始是默认的存储引擎。 InnoDB 存储引擎将数据放在一个逻辑的表空间中,这个表空间就像黑盒一样由 InnoDB 存储引擎自身来管理。从 MySQL 4.1(包括 4.1)版本开始,可以将每个 InnoDB 存储引擎的 表单独存放到一个独立的 ibd 文件中。此外,InnoDB 存储引擎支持将裸设备(row disk)用 于建立其表空间。 InnoDB 通过使用多版本并发控制(MVCC)来获得高并发性,并且实现了 SQL 标准 的 4 种隔离级别,默认为 REPEATABLE 级别,同时使用一种称为 netx-key locking 的策略来 避免幻读(phantom)现象的产生。除此之外,InnoDB 存储引擎还提供了插入缓冲(insert buffer)、二次写(double write)、自适应哈希索引(adaptive hash index)、预读(read ahead) 等高性能和高可用的功能。 对于表中数据的存储,InnoDB 存储引擎采用了聚集(clustered)的方式,每张表都是按 主键的顺序进行存储的,如果没有显式地在表定义时指定主键,InnoDB 存储引擎会为每一 行生成一个 6 字节的 ROWID,并以此作为主键。 InnoDB 存储引擎是 MySQL 数据库最为常用的一种引擎,Facebook、Google、Yahoo 等 公司的成功应用已经证明了 InnoDB 存储引擎具备高可用性、高性能以及高可扩展性。对其 底层实现的掌握和理解也需要时间和技术的积累。如果想深入了解 InnoDB 存储引擎的工作 原理、实现和应用,可以参考《MySQL 技术内幕:InnoDB 存储引擎》一书。 #MyISAM 存储引擎 不支持事务、表锁设计、支持全文索引,主要面向一些 OLAP 数 据库应用,在 MySQL 5.5.8 版本之前是默认的存储引擎(除 Windows 版本外)。数据库系统 与文件系统一个很大的不同在于对事务的支持,MyISAM 存储引擎是不支持事务的。究其根 本,这也并不难理解。用户在所有的应用中是否都需要事务呢?在数据仓库中,如果没有 ETL 这些操作,只是简单地通过报表查询还需要事务的支持吗?此外,MyISAM 存储引擎的 另一个与众不同的地方是,它的缓冲池只缓存(cache)索引文件,而不缓存数据文件,这与 大多数的数据库都不相同。 #NDB 存储引擎 年,MySQL AB 公司从 Sony Ericsson 公司收购了 NDB 存储引擎。 NDB 存储引擎是一个集群存储引擎,类似于 Oracle 的 RAC 集群,不过与 Oracle RAC 的 share everything 结构不同的是,其结构是 share nothing 的集群架构,因此能提供更高级别的 高可用性。NDB 存储引擎的特点是数据全部放在内存中(从 5.1 版本开始,可以将非索引数 据放在磁盘上),因此主键查找(primary key lookups)的速度极快,并且能够在线添加 NDB 数据存储节点(data node)以便线性地提高数据库性能。由此可见,NDB 存储引擎是高可用、 高性能、高可扩展性的数据库集群系统,其面向的也是 OLTP 的数据库应用类型。 #Memory 存储引擎 正如其名,Memory 存储引擎中的数据都存放在内存中,数据库重 启或发生崩溃,表中的数据都将消失。它非常适合于存储 OLTP 数据库应用中临时数据的临时表,也可以作为 OLAP 数据库应用中数据仓库的维度表。Memory 存储引擎默认使用哈希 索引,而不是通常熟悉的 B+ 树索引。 #Infobright 存储引擎 第三方的存储引擎。其特点是存储是按照列而非行的,因此非常 适合 OLAP 的数据库应用。其官方网站是 http://www.infobright.org/,上面有不少成功的数据 仓库案例可供分析。 #NTSE 存储引擎 网易公司开发的面向其内部使用的存储引擎。目前的版本不支持事务, 但提供压缩、行级缓存等特性,不久的将来会实现面向内存的事务支持。 #BLACKHOLE 黑洞存储引擎,可以应用于主备复制中的分发主库。 MySQL 数据库还有很多其他存储引擎,上述只是列举了最为常用的一些引擎。如果 你喜欢,完全可以编写专属于自己的引擎,这就是开源赋予我们的能力,也是开源的魅 力所在。
2、存储引擎的使用
方式一:在建表的时候指定
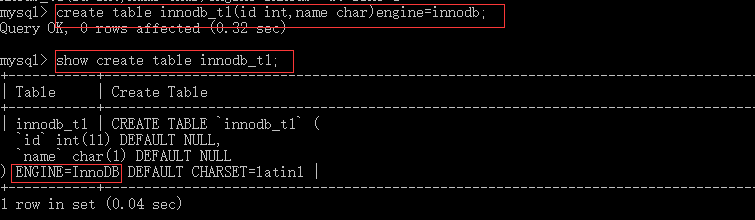
方式二:在配置文件进行配置
[mysqld] default-storage-engine=INNODB innodb_file_per_table=1
三、表数据类型
存储引擎决定了表的类型,而表内存放的数据也要有不同的类型,每种数据类型都有自己的宽度,但宽度是可选的。mysql中常见的数据类型包括数字、字符串、时间类型、枚举类型及集合类型,分别介绍如下:
1、数字类型
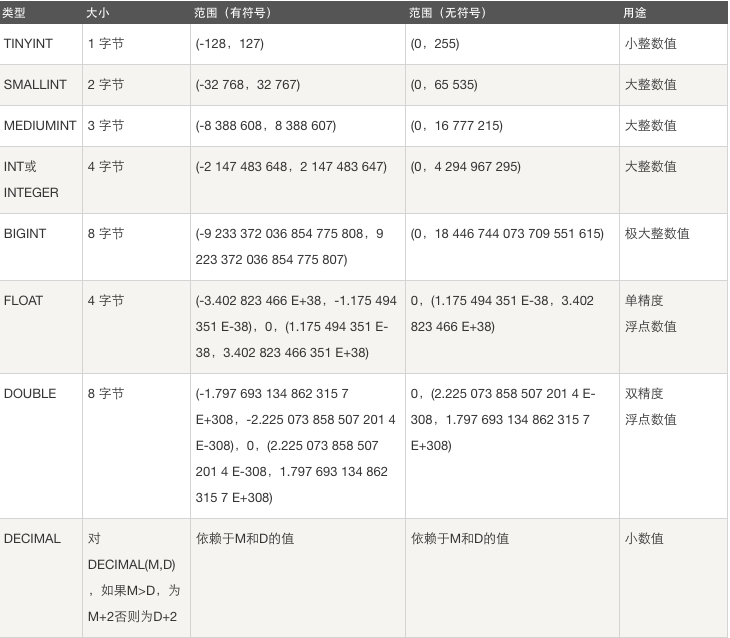 (1)整数类型
(1)整数类型
整数类型包括:TINYINT SMALLINT MEDIUMINT INT BIGINT,作用主要是存储年龄、id及各种号码,需要强调的是整数类型设置的数字为显示的宽度。如下例:

可以看出设置宽度意义不大,能否正确存储数字是由数字是否超过整数类型所能接收的范围,通过设置zorefill可以看出显示宽度的意义,如下:
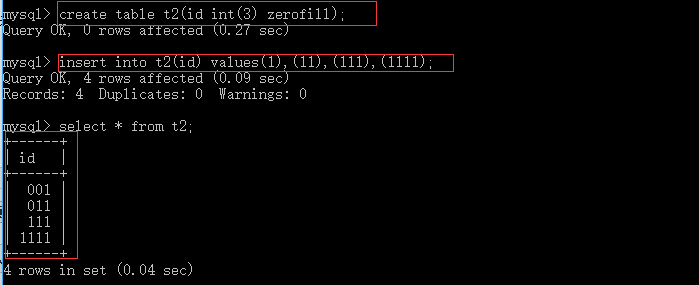
默认为带符号的,如下图,当输入数字超过有符号int类型所能接收的最大值时,存储有符号范围的最大值,如下例:
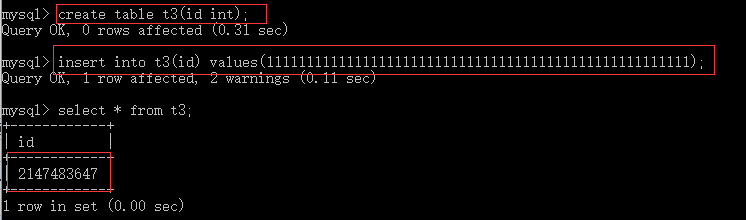
通过unsigned可以将int设置成不带符号的形式,当输入数字超过不带符号int类型所能接受的最大值,则将数字储存成不带符号范围的最大值,如下例。注意的是,如果设置为不带符号的情况,输入负数时,储存为零。
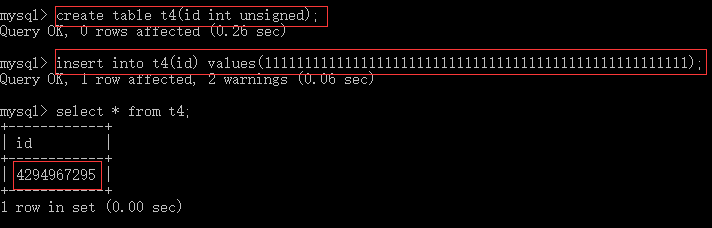 (2)小数类型
(2)小数类型
小数类型包括float、double和decimal三种类型,float类型支持的数字总个数最大为255,小数点后支持最大位数为30,随着小数的增多,精度变得不准确;double类型支持的数字总个数最大为255,小数点后支持最大位数为30,随着小数的增多,精度比float要高,但也会变得不准确;decimal类型支持的数字总个数最大为65,小数点后支持最大位数为30,随着小数的增多,精度始终准确,因为其内部是按照字符串进行存储的,对于精确数值计算需要用到。
create table t6(weight float(256,30); create table t7(weight double(256,30); create table t8(weight decimal(65,30); insert into t6 values(1.1111111111111111111111111111111111111111111111111111111111111111); insert into t7 values(1.1111111111111111111111111111111111111111111111111111111111111111); insert into t8 values(1.1111111111111111111111111111111111111111111111111111111111111111);
通过结果可以看到三者精度的差距如下:

2、日期类型
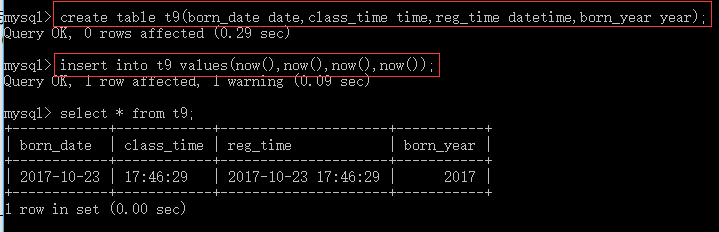
主要用于存储用户注册时间,文章发布时间,员工入职时间,出生时间,过期时间等,包括如下几种日期类型:
DATE: 年月日,如2017-11-11 TIME: 时分秒,如10:14:11 DATETIME: 如2017-11-11 10:14:11,其中年的范围为:1001-9999,存储时间与时区无关,使用8字节的存储空间,默认值为null
TIMESTAMP: 如2017-11-11 10:14:11,其中年的范围为:1970-2038,存储时间与时区有关,使用4字节的存储空间,默认值为当前时间
YEAR : 表示年,支持的范围为1901-2155
3、字符类型
字符类型包含char和varchar,具体不同如下:
#注意:char和varchar括号内的参数指的都是字符的长度 #char类型:定长,简单粗暴,浪费空间,存取速度快 字符长度范围:0-255(一个中文是一个字符,是utf8编码的3个字节) 存储: 存储char类型的值时,会往右填充空格来满足长度 例如:指定长度为10,存>10个字符则报错,存<10个字符则用空格填充直到凑够10个字符存储 检索: 在检索或者说查询时,查出的结果会自动删除尾部的空格,除非我们打开pad_char_to_full_length SQL模式(SET sql_mode = 'PAD_CHAR_TO_FULL_LENGTH';) #varchar类型:变长,精准,节省空间,存取速度慢 字符长度范围:0-65535,mysql行最大限制为65535字节,字符编码为utf-8 存储: varchar类型存储数据的真实内容,不会用空格填充,如果'ab ',尾部的空格也会被存起来 强调:varchar类型会在真实数据前加1-2Bytes的前缀,该前缀用来表示真实数据的bytes字节数(1-2Bytes最大表示65535个数字,正好符合mysql对row的最大字节限制,即已经足够使用) 如果真实的数据<255bytes则需要1Bytes的前缀(1Bytes=8bit 2**8最大表示的数字为255) 如果真实的数据>255bytes则需要2Bytes的前缀(2Bytes=16bit 2**16最大表示的数字为65535) 检索: 尾部有空格会保存下来,在检索或者说查询时,也会正常显示包含空格在内的内容
(1)宽度限制的区别
当二者输入的数据长度大于设置的长度,则均只从左到右保存设置长度数据部分:
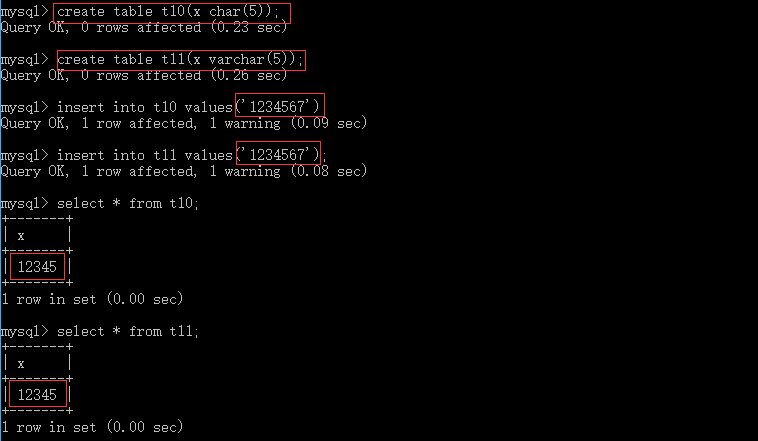
当二者输入数据的长度均小于设置的长度,则char按照设置的长度进行存储,不够位数用空格填充,varchar则储存实际数据的长度,如按照如下创建完数据后,结果显示为:
create table t16(name char(5)); create table t17(name varchar(5)); insert into t16 values('a'); insert into t17 values('a'); SET sql_mode = 'PAD_CHAR_TO_FULL_LENGTH'; select char_length(name) from t16; select char_length(name) from t17;

(2)存储机制的区别
如下表char存入数据是按照设定长度进行存储的,不够用空格站位,查询时按照固定长度查询,快速高效,但是占内存,varchar则是按实际字符长度进行存储,但是为了方便查询数据,需要在数据前加1-2个字节的前缀,该前缀表示真实数据的字节数,方便数据查询。

4、枚举和集合类型
枚举:unum,字段的值只能在给定范围中选一个,如性别:

集合:set,字段的值只能在给定范围中选择一个或多个,如爱好: