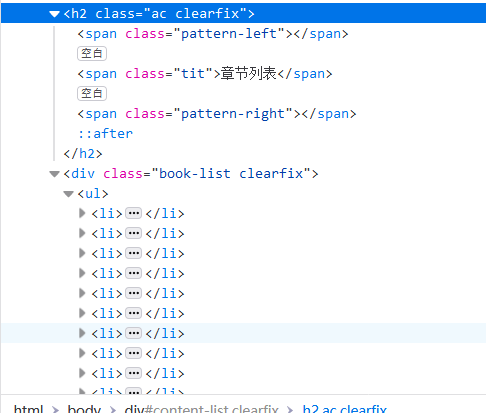
爬取网络小说标题及内容
标题存在一个a标签


import requests
from bs4 import BeautifulSoup
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36'}
url = 'https://www.luoxia.com/shapolang/'
page_text = requests.get(url,headers = headers).text
soup = BeautifulSoup(page_text,'lxml')
li_list = soup.select('.book-list > ul > li')
fp = open('./shapolang.txt','w',encoding = 'UTF-8')
for li in li_list:
title = li.a.string
detail_url = li.a['href']
detail_page_text = requests.get(url = detail_url,headers = headers).text
detail_soup = BeautifulSoup(detail_page_text,'lxml')
div_tag = detail_soup.find('div',id = 'nr1')
content = div_tag.text
fp.write(title + ':' + content + '
')
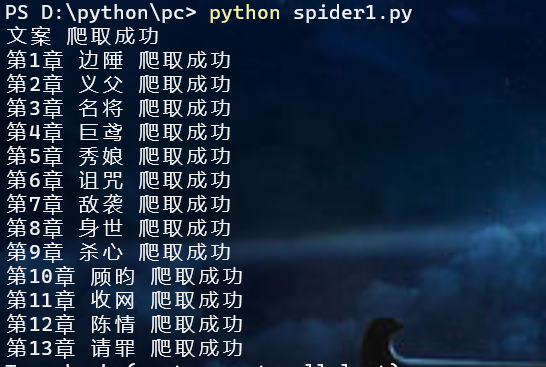
print(title,'爬取成功')
到第14章的时候出错了,因为
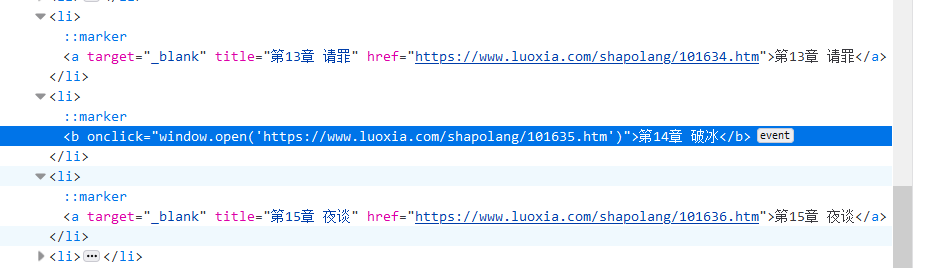
它这个构造和别的不一样