爬虫学习


小案例
简单网页采集器
首先明确,查询一个内容
https://www.baidu.com/s?wd=serendipity&rsv_spt=1&rsv_iqid=0x8cf6b44a0002b0ad&issp=1&f=8&rsv_bp=1&rsv_idx=2&ie=utf-8&tn=92564395_hao_pg&rsv_enter=1&rsv_dl=tb&rsv_sug3=13&rsv_sug1=9&rsv_sug7=100&rsv_sug2=0&rsv_btype=i&prefixsug=serendipity&rsp=5&inputT=6139&rsv_sug4=8508
只有这些https://www.baidu.com/s?wd=serendipity是有用的
源码:
import requests
url = 'https://www.sogou.com/web'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:76.0) Gecko/20100101 Firefox/76.0'}
kw = input('enter a word : ')
param = {
'query':kw
}
res = requests.get(url,params = param,headers=headers)
text = res.text
filename = kw + '.html'
with open(filename,'w',encoding = 'UTF-8') as fp:
fp.write(text)
print(filename,'保存成功')
破解百度翻译
爬取的是局部的数据(这局部数据是单独更新的)
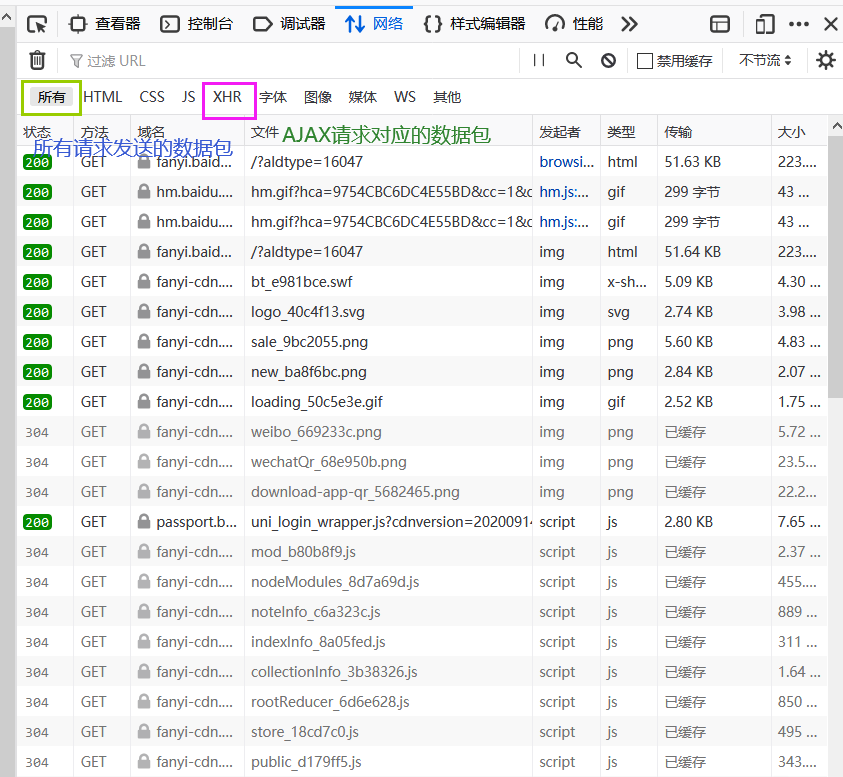
(这个用火狐看到的结果不是很理想)
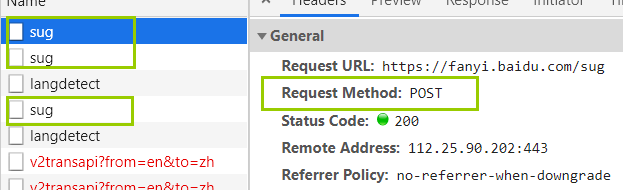
POST传参
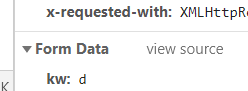
据观察,每输入一个字母就发送一个AJAX请求
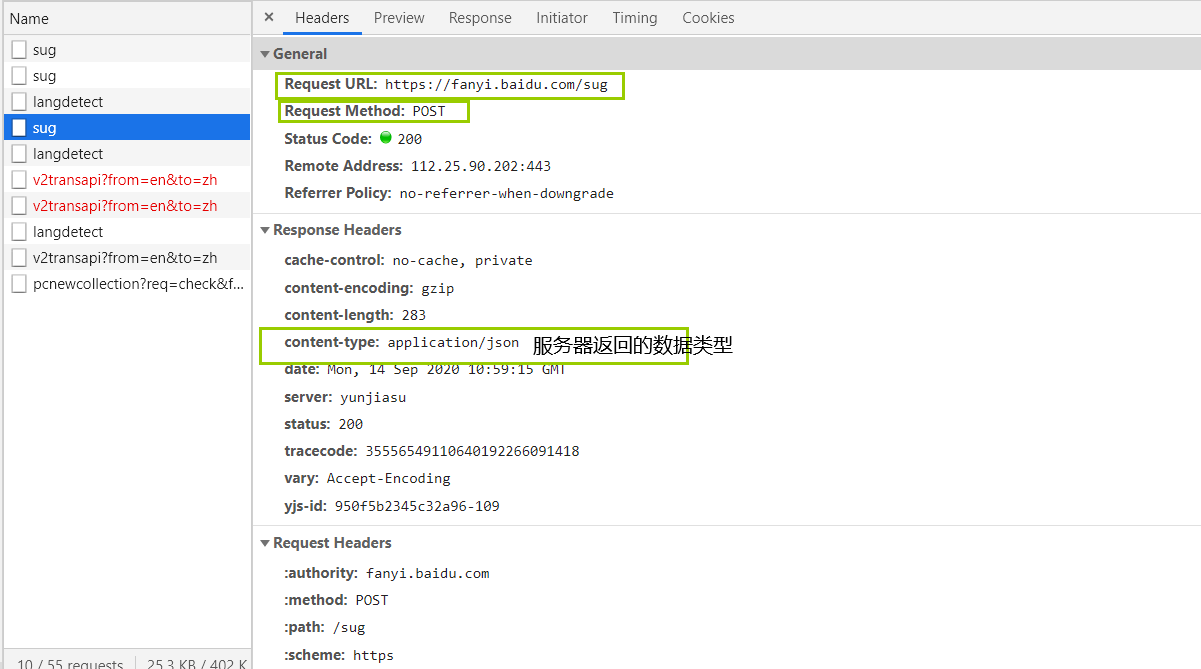
源码:
import requests
import json
url = 'https://fanyi.baidu.com/sug'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36'}
word = input('enter a word: ')
data = {
'kw':word
}
res = requests.post(url,data = data,headers=headers)
# json()方法返回的是一个对象
obj = res.json()
print(obj)
file_name = word+'.json'
fp = open(file_name,'w',encoding='UTF-8')
json.dump(obj,fp = fp,ensure_ascii = False)
抓取豆瓣电影排行榜信息:
页面拖动到底部url没变,但是页面更新了,所以发送了AJAX请求


源码:
import requests
import json
url = 'https://movie.douban.com/j/chart/top_list'
# 携带参数,最好封装一下
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36'}
param = {
'type': '24',
'interval_id': '100:90',
'action':'' ,
'start': '0',
'limit': '20'
}
res = requests.get(url,params = param,headers=headers)
# json()方法返回的是一个对象
obj = res.json()
# file_name = word+'.json'
fp = open('./douban.json','w',encoding='UTF-8')
json.dump(obj,fp = fp,ensure_ascii = False)