kmeans介绍学习博客:https://blog.csdn.net/sinat_30353259/article/details/80887779
kmeans代码摘自:https://www.cnblogs.com/fengfenggirl/p/k-means.html
具体的学习介绍可以参考以上两个博主博客
本文实现代码也只是对以上博主博客的一个引用实现:
题目:读数据库,对文本进行聚类分析
代码分析:(完整代码在下方)
①确定k值

运行结果:
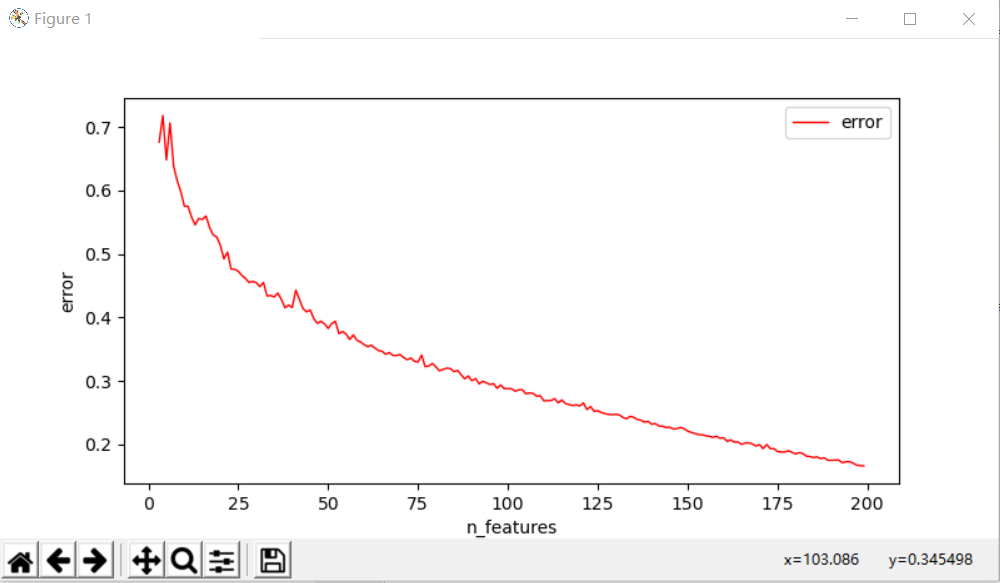
②由上图可以确定一个k值,修改
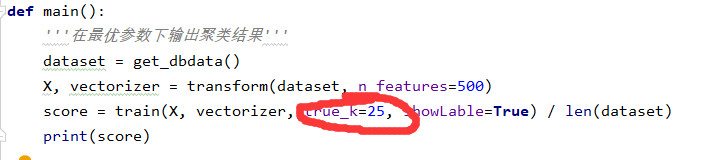

运行结果:

说明:数据库不便透露,数据格式如下txt文件:



农业 三农 农机 农资
生物医药中间体 生产工艺 低聚硒酸软骨素
草皮
神经病理性疼痛 健康 养生
超声心动图 运动 心肌 健康
软件
沥青混凝土
残余应力 无缝管
果醋饮料 酿造工艺 饮料
艾滋病 梅毒感染 梅毒 传染病
养生 健康
复合材料
三农 农业 时政
火焰温度 锅炉
万向轴
电源
时政
焦炉煤气 净化公司
魔芋 时政
污水
铝合金 激光
科学 科普
防雷
畜牧业
棉花
时政
奶牛 三农 畜牧业
时政 于桥水库
级配碎石
三农 畜牧业 池塘
草皮 土壤结构 三农 农业 种植业
环境污染
硫化工艺 乳胶
吸收系数
多糖
秸秆
环境污染 时政
葡萄
真空机组 真空系统
白灵菇 杏鲍菇
豆乳
时政
变压器油
预应力 波纹管
地下空间
时政
钻井液
钻井液 环境保护
钻井液
时政
钻井液
时政
沥青混凝土
丹参 中药 三倍体
沼气 水污染
三农 农业
健康
纳米粒子 科学 科普
蔬菜
蔬菜
能源
蔬菜
蔬菜 潜叶蝇
蔬菜 三农
应用推广 抽油机
聚丙烯酰胺 水污染 污水
三农 时政
营养学 营养餐
畜牧业
三农 畜牧业 海参 养殖技术
组态
时政
应用推广
时政
羊肉营养 三农 肉羊 畜牧业
超滤膜 中空纤维超滤膜 微孔滤膜
通信 谐波 gprs
风机变频器 关系逻辑
真空断路器
畜牧业
煤气 高炉炼铁 高炉 煤炭
水污染 时政
造纸原料 环境保护 环境污染 时政 造纸术
酒精 发酵工艺 燃料
时政
蝴蝶兰
三农 硅肥 畜牧业 饲料
蔬菜
肉牛
时政
肺癌 喉癌
葡萄 三农 时政
地质
施工工法 顶管 smw工法
钻井液
韭菜
天然气投资 能源 球罐
砂岩
时政 施工工艺
菜花 三农
完整代码:
#!/usr/bin/env python # -*- coding: utf-8 -*- # @File : kmeans.py # @Author: 田智凯 # @Date : 2020/3/19 # @Desc :机器学习kmeans算法,对科技成果项目进行聚类分析 from __future__ import print_function import time from sklearn.feature_extraction.text import TfidfVectorizer import matplotlib.pyplot as plt from sklearn.cluster import KMeans, MiniBatchKMeans import pymssql #读取sqlserver数据库 def get_dbdata(): conn_read = pymssql.connect("127.0.0.1", "sa", "###", "test", charset="GBK") dataset = [] sql = "select guanjianci from julei_test" cursor = conn_read.cursor() cursor.execute(sql) data_count = 0 for line in cursor: data_count +=1 dataset.append(line[0]) cursor.close() conn_read.close() print(dataset) return dataset def transform(dataset, n_features=1000): vectorizer = TfidfVectorizer(max_df=0.5, max_features=n_features, min_df=2, use_idf=True) X = vectorizer.fit_transform(dataset) return X, vectorizer def train(X, vectorizer, true_k=10, minibatch=False, showLable=False): # 使用采样数据还是原始数据训练k-means, if minibatch: km = MiniBatchKMeans(n_clusters=true_k, init='k-means++', n_init=1, init_size=1000, batch_size=1000, verbose=False) else: km = KMeans(n_clusters=true_k, init='k-means++', max_iter=300, n_init=1, verbose=False) km.fit(X) if showLable: print("Top terms per cluster:") order_centroids = km.cluster_centers_.argsort()[:, ::-1] terms = vectorizer.get_feature_names() print(vectorizer.get_stop_words()) for i in range(true_k): print("Cluster %d:" % i, end='') for ind in order_centroids[i, :10]: print(' %s' % terms[ind], end='') print() result = list(km.predict(X)) print('Cluster distribution:') print(dict([(i, result.count(i)) for i in result])) return -km.score(X) #指定簇的个数k def k_determin(): '''测试选择最优参数''' dataset = get_dbdata() print("%d documents" % len(dataset)) X, vectorizer = transform(dataset, n_features=500) true_ks = [] scores = [] #中心点的个数从3到200(根据自己的数据量改写) for i in range(3, 200, 1): score = train(X, vectorizer, true_k=i) / len(dataset) print(i, score) true_ks.append(i) scores.append(score) plt.figure(figsize=(8, 4)) plt.plot(true_ks, scores, label="error", color="red", linewidth=1) plt.xlabel("n_features") plt.ylabel("error") plt.legend() plt.show() def main(): '''在最优参数下输出聚类结果''' dataset = get_dbdata() X, vectorizer = transform(dataset, n_features=500) score = train(X, vectorizer, true_k=25, showLable=True) / len(dataset) print(score) if __name__ == '__main__': start=time.time() #k_determin()#先确定k值 main() end=time.time() print('程序运行时间',end-start)