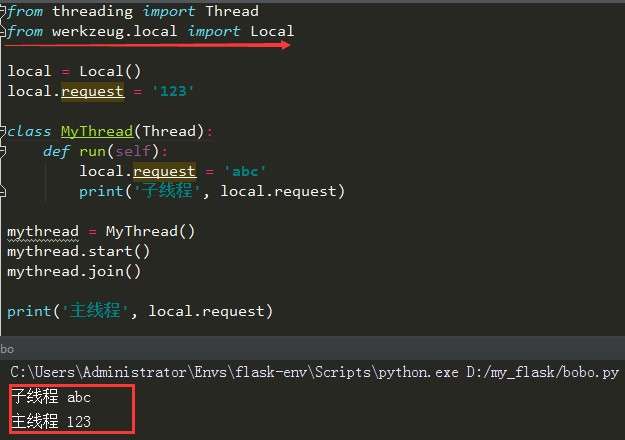
Local线程隔离对象
我们知道通过request可以获取表单中的数据。如果是多个用户同时在用网站,而全局request就只有一个,那么Flask是如何分辨哪用户对应哪个请求呢?
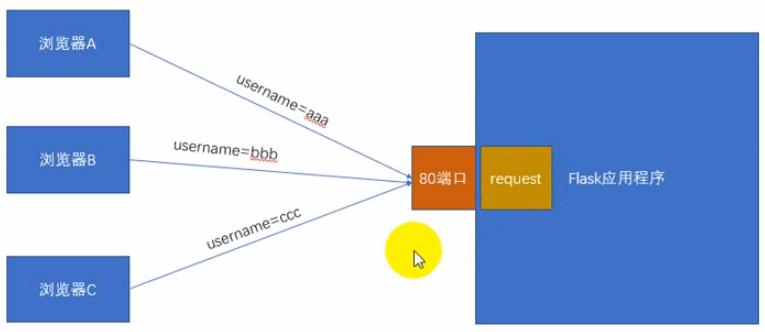
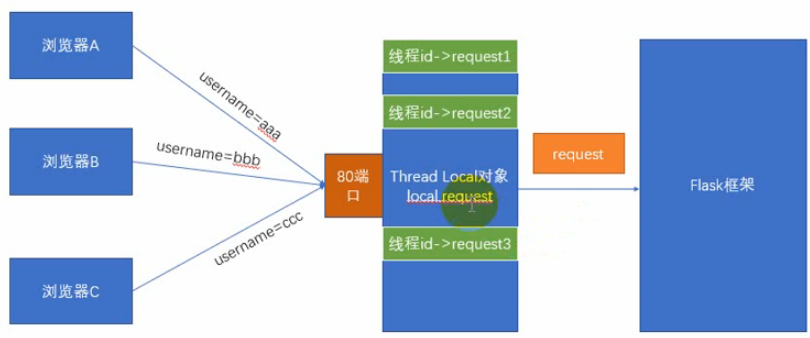
这种情况下,就会用到Local对象,只要绑定在Local对象上的属性,在每个线程中都是隔离的
我们看看,使用多线程修改值,不用local对象时,因为request是全局共享的,只要修改了它的值,就会影响到其它线程!
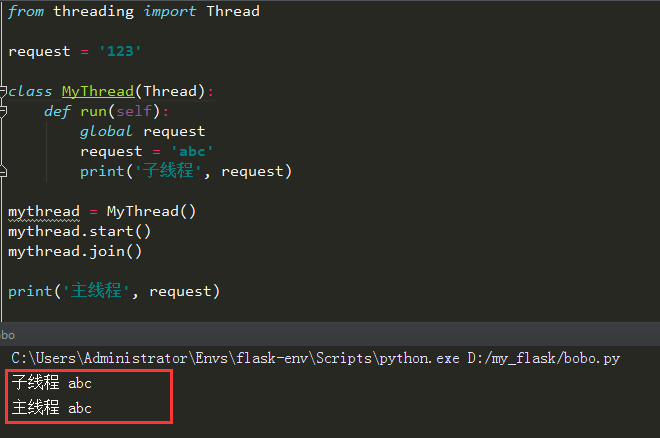
当我们使用Local对象绑定时,因为在每个线程中都是隔离的,所以不会影响到其它线程
总结:
1、在Flask中,类似于request的对象(还有session等),其实是绑定到了一个werkzeug.local.Local对象上。这样,即使是同一个对象,那么多个线程中都是隔离的。
2、只要满足绑定到这个对象上的属性,在每个线程中都是隔离的,那么它就叫做Thread Local对象
app上下文
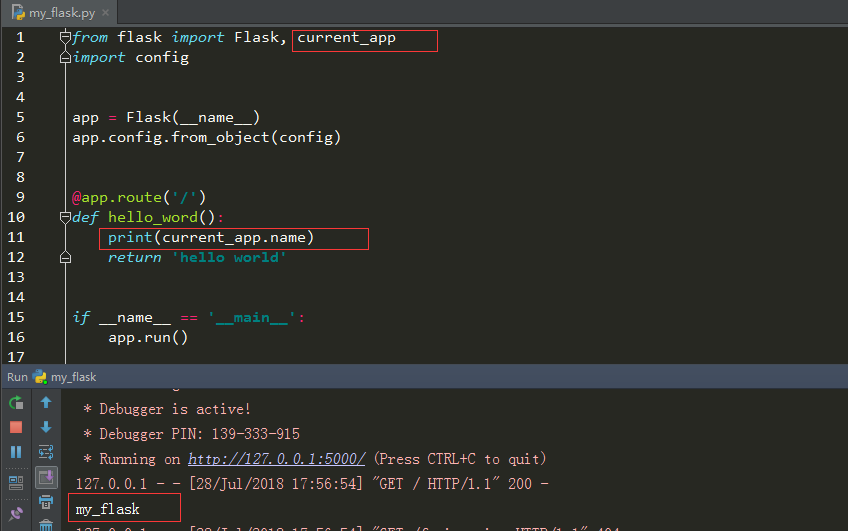
app上下文存放在一个LocalStack的栈中,和app应用相关的操作就必须要应用上下文,比如通过current_app获取当前这个app的名字
启动访问浏览器首页
如果我们把print(current_app.name)放到视图函数外面,就会报错
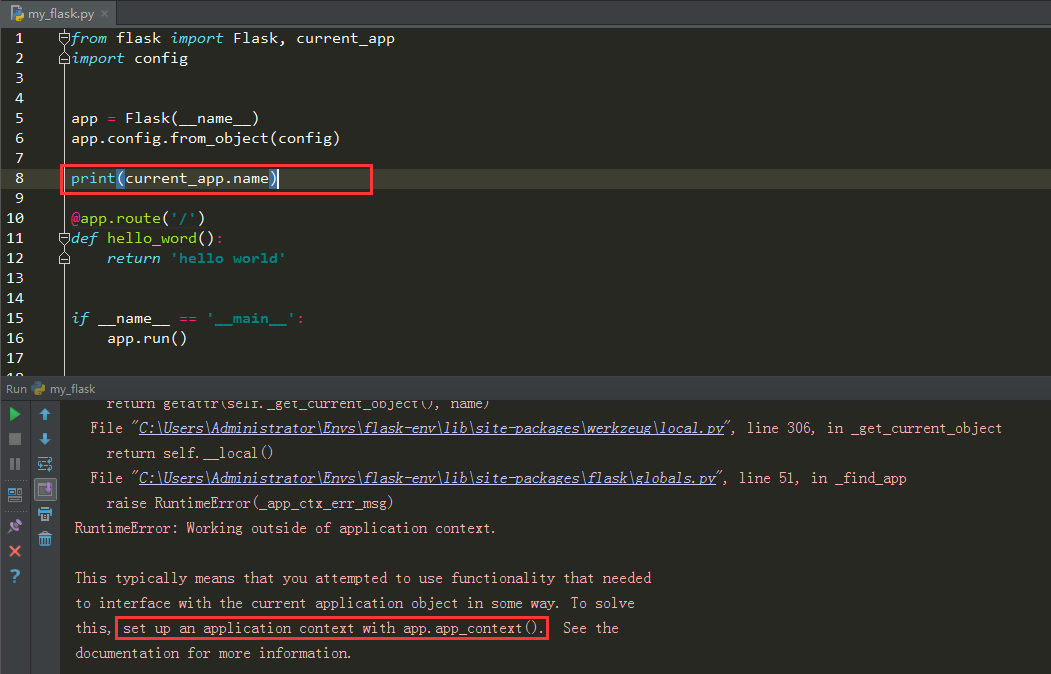
在视图函数中,不用担心上下文的问题,因为视图函数要执行,肯定是通过url的方式执行的,这种情况下,Flask底层就已经自动的帮我们把应用上下文推入到相应的栈中。如果要在视图函数外面执行相关的操作,就必须手动推入上下文。
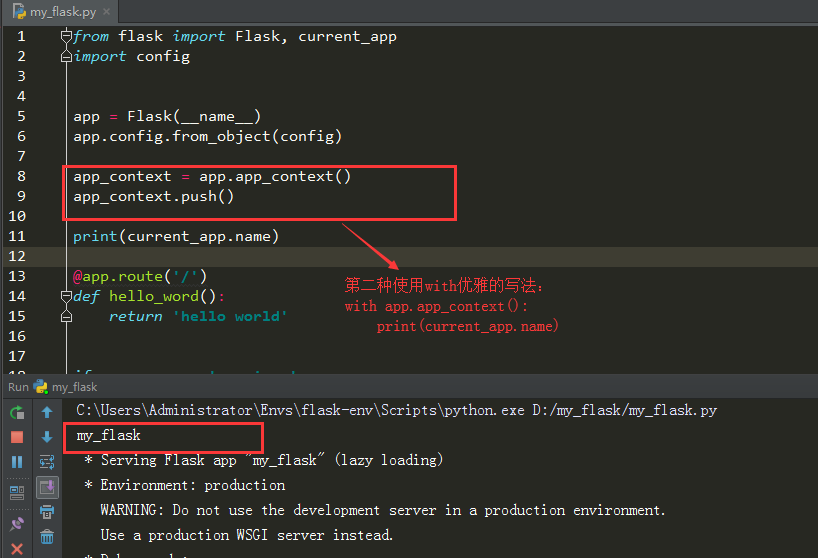
请求上下文
请求上下文也是存放在一个LocalStack栈中,请求的相关的操作就必须用到请求的上下文,比如url_for反转视图函数
因为在视图函数图,会自动推入上下文,所以正常执行
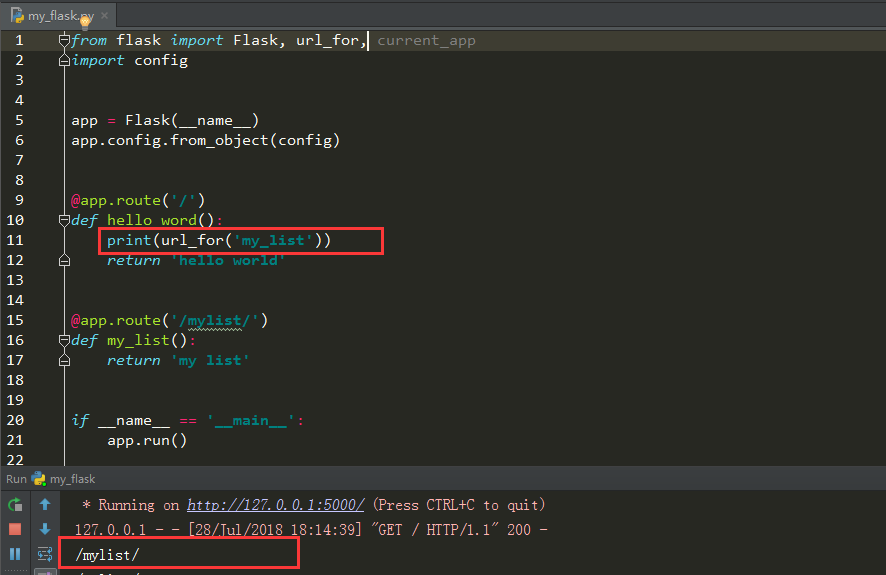
当在视图函数外面执行,没有请求上下文的关系则会报错
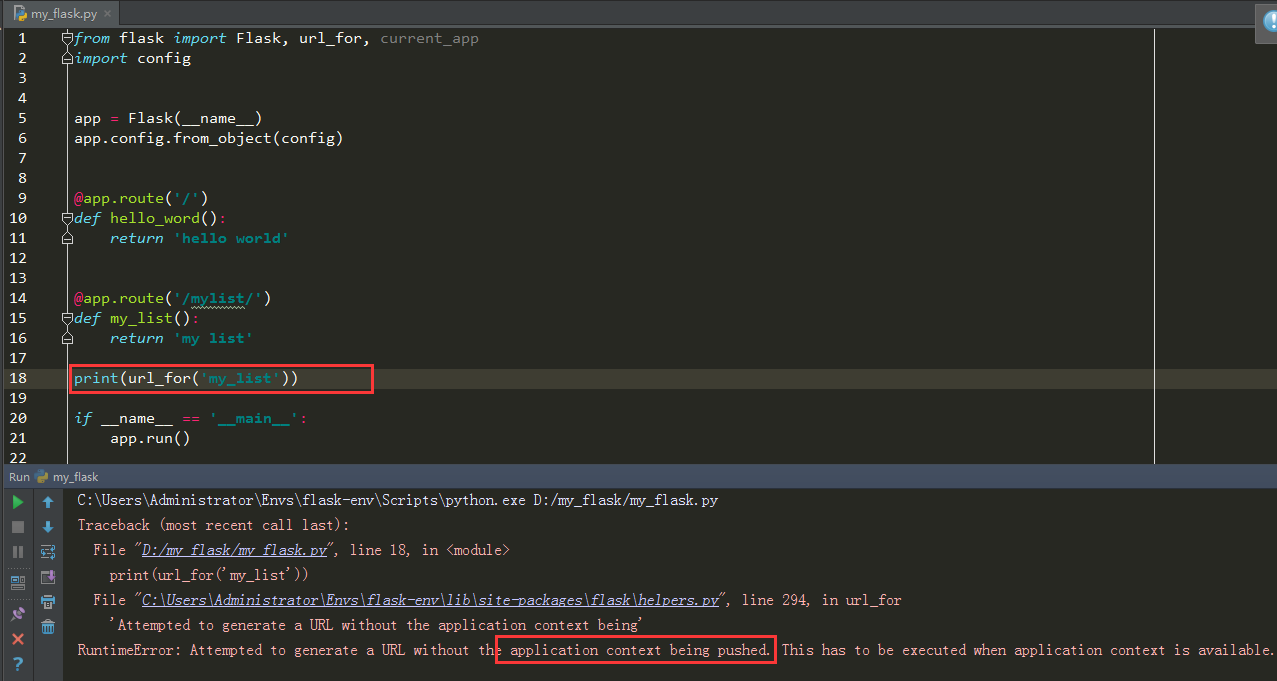
错误提示是没有app上下文推入,那么我们就使用前面的方法推入app上下文
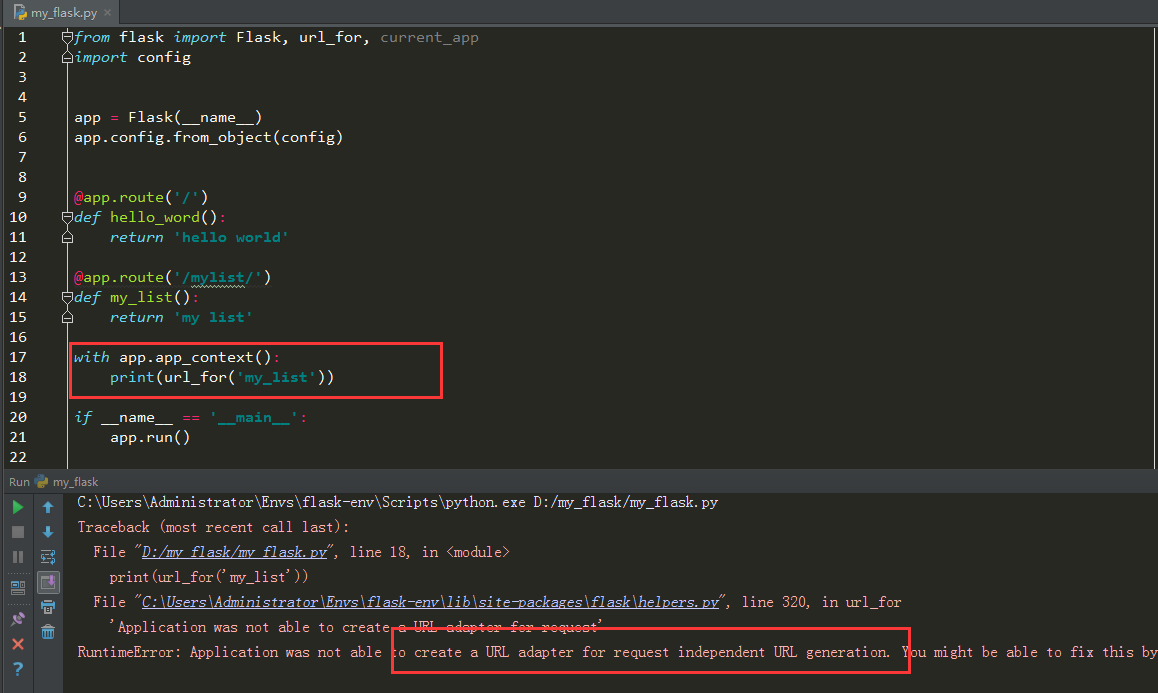
推入app上下文后,又出错,没有请求上下文
因此,手动推入请求上下文:推入请求上下文到栈中,会首先判断有没有应用上下文,如果没有那么就会先推入应用上下文到栈中,然后再推入请求上下文到栈中
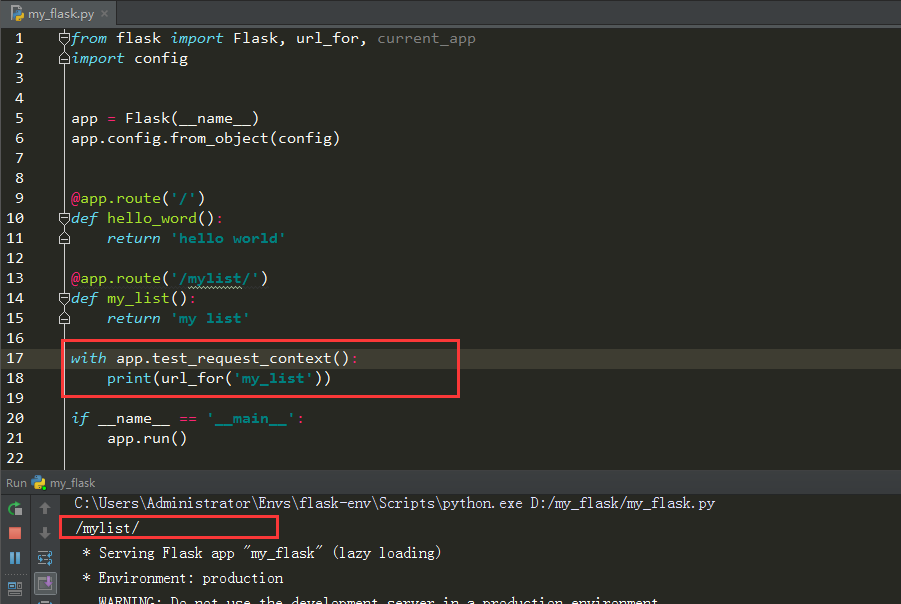
为什么上下文需要放在栈中
2、Flask底层是基于werkzeug,werkzeug是可以包含多个app的,所以这时候用一个栈来保存,如果你在使用app1,那么app1应该是要在栈的顶部,如果用完了app1那么app应该从栈中删除,方便其他代码使用下面的app。
2、如果在写测试代码,或者离线脚本的时候,我们有时候可能需要创建多个请求上下文,这时候就需要存放到一个栈中了。使用哪个请求上下文的时候,就把对应的请求上下文放到栈的顶部,用完了就要把这个请求上下文从栈中移除掉。
线程隔离的g对象
g对象是在整个Flask应用运行期间都是可以使用的,并且它也是跟request一样是线程隔离的。这个对象是专门用来存储开发者自定义的一些数据,方便在整个Flask程序中都可以使用。一般使用就是,将一些经常会用到的数据绑定到上面,以后就直接从g上面取就可以了,而不是通过传参的形式,这样更加方便。
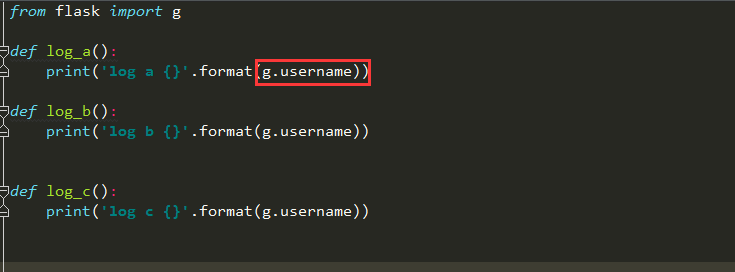
比如当我们访问首页的时候会调用一些函数打印日志,并且这个这个会打印出用户名
新建一个utils.py专门用来存储这些工具函数,如下
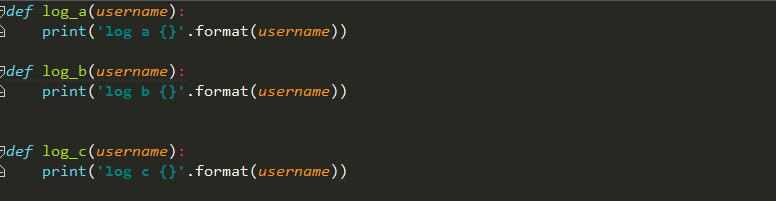
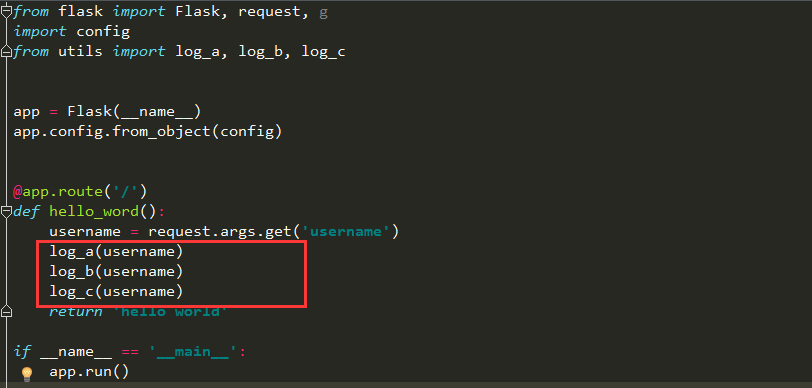
这样做虽然可以实现需求,但是每条调用都必须传入username参数才可以,如果使用g就方便多了
把username存入到g.username中
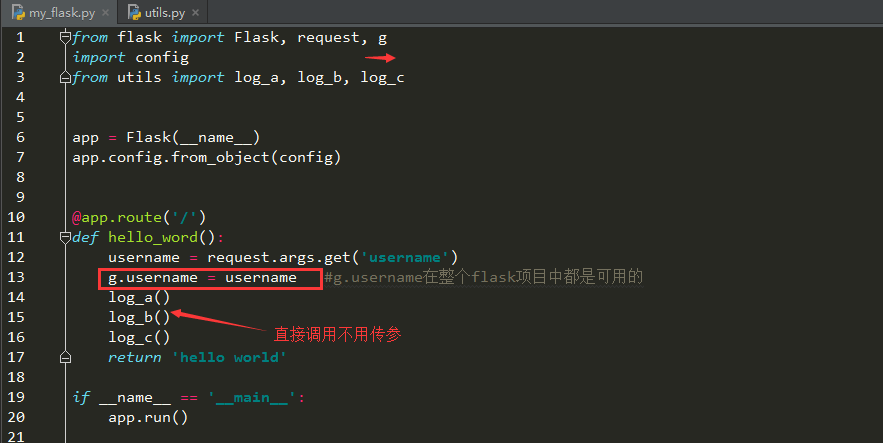
函数那边直接调用g.username就可以了