StreamSets是一个大数据采集工具,数据源支持包括结构化和半/非结构化,目标源支持HDFS,HBase,Hive,Kudu,Cloudera Search, ElasticSearch等。它包括一个拖拽式的可视化数据流程设计界面,定时任务调度等功能。举例,它可以将数据源从Kafka+Spark Streaming连接到你的Hadoop集群,而不需要写一行代码。
StreamSets并没有集成在cdh中,因此需要我们自己去官方下载软件包
下载地址: https://archives.streamsets.com/index.html
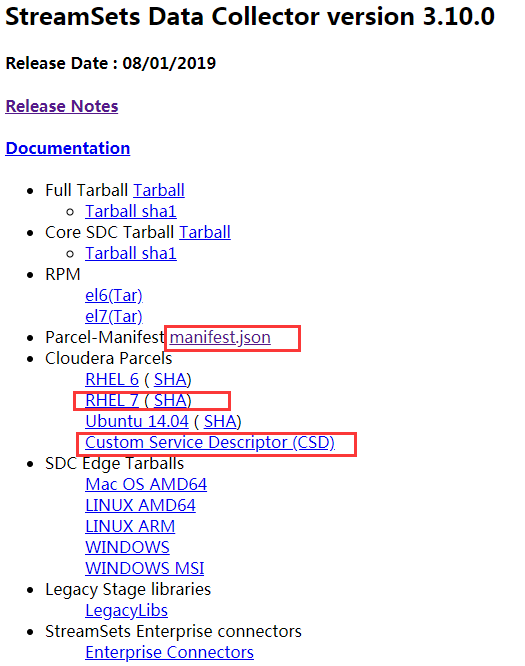
下载下来的文件如下,软件包有4.6G左右,需要点耐心

配置本地yum源
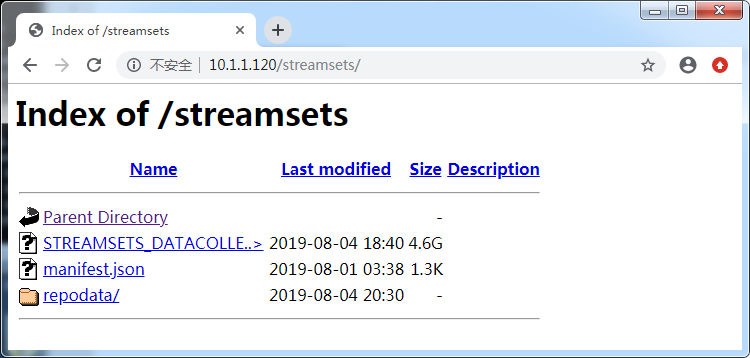
新建一个目录,把STREAMSETS_DATACOLLECTOR-3.10.0-el7.parcel, manifest.json放目录里
mkdir /var/www/html/streamsets mv STREAMSETS_DATACOLLECTOR-3.10.0-el7.parcel /var/www/html/streamsets mv manifest.json /var/www/html/streamsets cd /var/www/html/streamsets createrepo .
配置yum


[root@cm ~]# cat /etc/yum.repos.d/ss.repo [ssrepo] name = ss_repo baseurl = http://10.1.1.120/streamsets enable = true gpgcheck = false
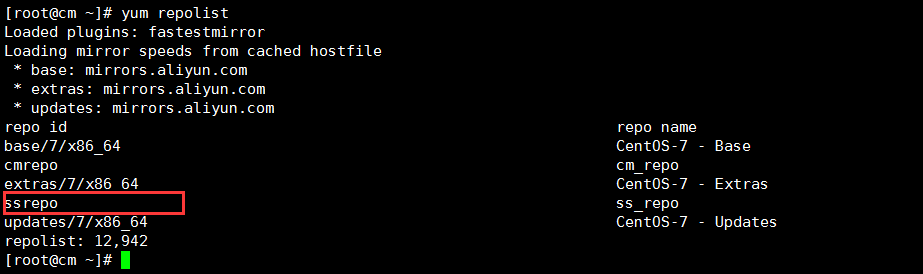
把ss.repo拷贝到集群其他节点,然后执行 yum. repolist,可以看到配置的yum 源
下载分发激活Parcel包
主机---Parcel---配置
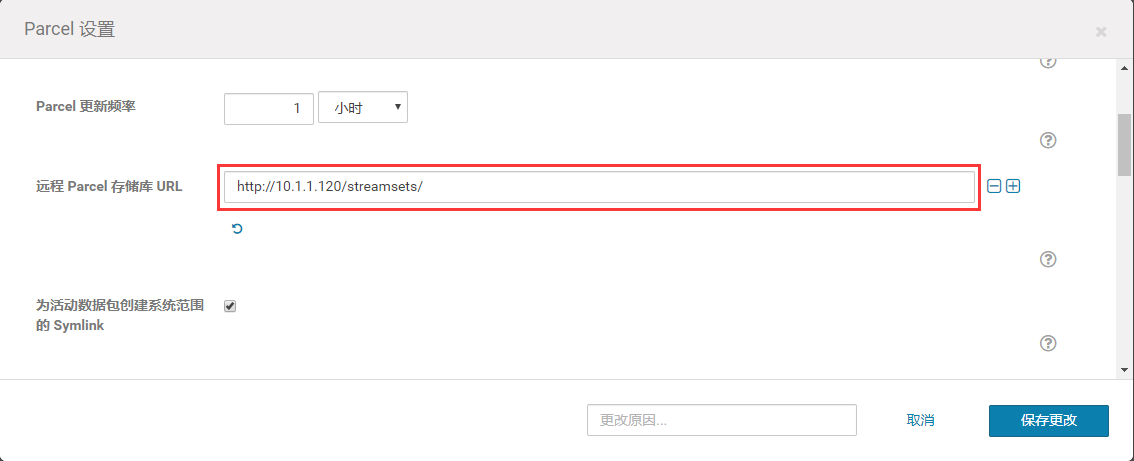
点击下载--分配--激活,因为包比较大,时间可能会稍微有点长

#######小坑##########
就是分配过程中cloudera server那台机一直卡在那里,其他节点没问题,进行了回滚操作
#curl -u user:password -X POST http://cm.bigdata-heboan.com:7180/api/v18/clusters/cdh-heboan/parcels/products/{product}/versions/{version}/commands/deactivate curl -u admin:admin -X POST http://cm.bigdata-heboan.com:7180/api/v18/clusters/cdh-heboan/parcels/products/STREAMSETS_DATACOLLECTOR/versions/3.10.0/commands/deactivate
后面发现,是clouder server这台机器的/etc/cloudera-scm-agent/config.ini 中的server_host是localhost,后面改为如下问题解决
...
# Hostname of the CM server.
server_host=cm.bigdata-heboan.com
中途遇到一次提示STREAMSETS_DATACOLLECTOR-3.10.0-el7.parcel哈希验证失败,解决办法是去到cm机器上的/opt/cloudera/parcel-repo目录
执行 sha1sum /opt/cloudera/parcel-repo, 把得出的哈希值替换STREAMSETS_DATACOLLECTOR-3.10.0-el7.parcel.sha里面的内容
添加服务
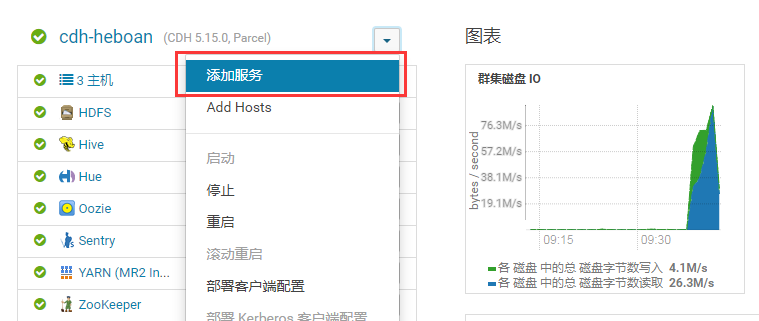
选择StreamSets

分配角色

数据目录
启动成功后
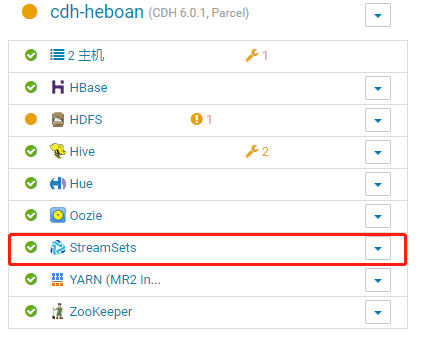
点击Data Collector Web UI

默认账号: admin/admin