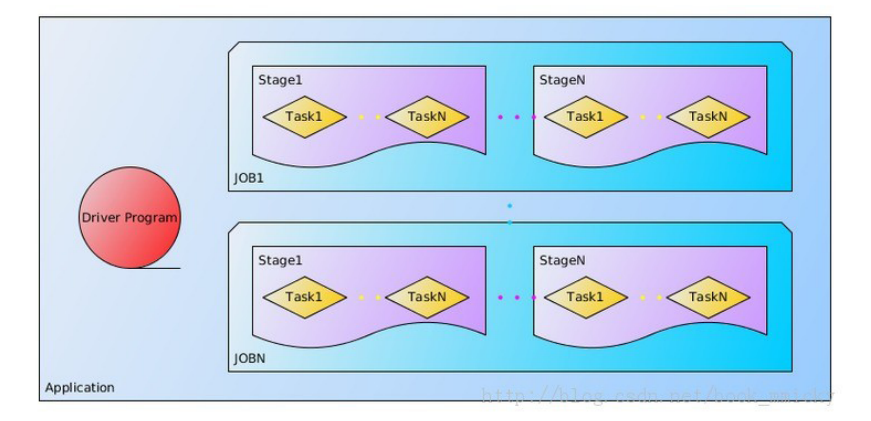
1、关于Application
用户程序,一个Application由一个在Driver运行的功能代码和多个Executor上运行的代码组成(工作在不同的节点上)。
又分成多个Job,每个Job由多个RDD和一些Action操作组成、job本分多个task组,每个task组称为:stage。
每个task又被分到多个节点,由Executor执行:
在程序中RDD转化其实还未真正运行,真正运行的是操作的时候。
2、程序执行过程
1)构建Spark Application的运行环境,就是启动SparkContext,启动后,向资源管理器
(standalone--spark自己的Master管理资源、Mesos或Yarn)注册且申请运行Executor资源。
2)资源管理器分配Executor资源,并且在各个节点上启动StandaloneExecutorBackend(对Standalone来说),Executor将运行情况随着心跳发送到资源管理器上。
3)SparkContext根据用户程序,构建DAG图,将DAG分解成Stage,划分原则是宽依赖时候划分,把Stage(TaskSet)发送给TaskScheduler。Stage
根据RDD的Partition数量来决定Task的数量;Executor向SparkContext申请Task。Task Scheduler将Task发送给Executor运行,且同时把代码发送给Executor(好像是Master开启HTTP服务,Executor去取代码)。
4)Task在Executor【此程序专属】上运行,多线程运行,线程数看可以运行的核数。
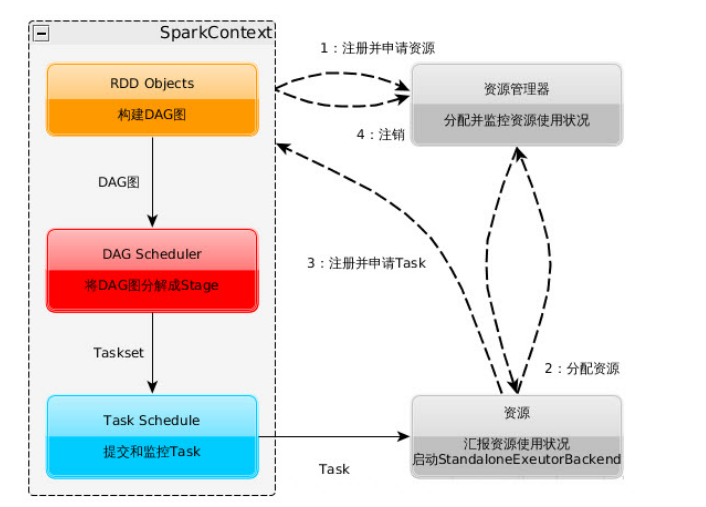
5)Spark Context运行地点和Worker不要分隔太远,中间过程有数据交换。
3、DAG Scheduler
1)根据RDD的依赖关系来划分Stage,简单来说,如果一个子RDD只依赖一个父RDD,则在一个Stage中,否则在多个Stage中,只依赖一个父RDD称为窄依赖,依赖多个父RDD为宽依赖,
发生宽依赖称为Shuffle。
2)当Shuffle数据处理失败的时候,它重新处理之前的数据。
3)它根据RDD构建DAG(有向无环图),然后再进一步找出开销最小的调度方法。将Stage发送给Task Scheduler。
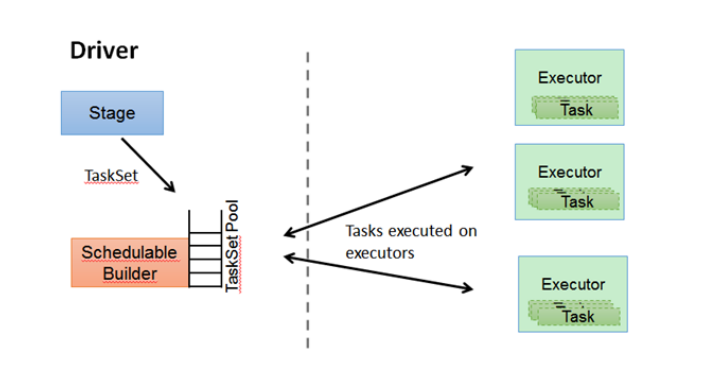
4、Task Scheduler
1)保存维护所有的TaskSet。
2)当Executor向Driver发送心跳的时候,TaskScheduler会根据其资源使用情况分配相应Task,如果允许失败,重试失败的Task。
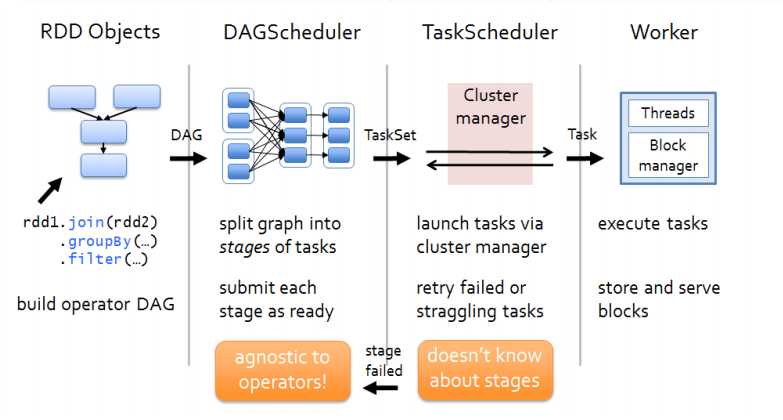
5、RDD的运行原理
1)根据Spark内部对象或者Hadoop等外部对象创建RDD。
2)构建DAG。
3)划分为Task,分别在多个节点上执行后汇总。
举例:第一个字母排序:
sc.textFile("hdfs://names")
.map(name => (name.charAt(0),name))
.groupByKey()
.mapValues(names =>names.toSet.size)
.collect()
假设文件内容为按行的姓名:
Ah (A,Ah) (A,(Ah,Anlly) [ (A,2),
PPT ---> map----> (P,PPT) ----->groupByKey--->(P,(PPT))-------->mapValues---> (P,1)]
Anlly (A,Anlly)
1)创建RDD、最后的collect为动作不会创建RDD,其他的操作都会创建新的RDD。
2)创建DAG,groupBy()会进行依赖多条上一个RDD的数据,所以多划分为一个阶段。
如图:

3)执行任务,每个阶段必须等上一个阶段执行完成。每个Stage又分成不同的Task执行,每个Task都包含代码+数据。
假设例子中的names下面有四个文件块,那么HadoopRDD中的Partitions自动划分为四个分区对应这四块数据。
就会创建四个Task执行相关任务。
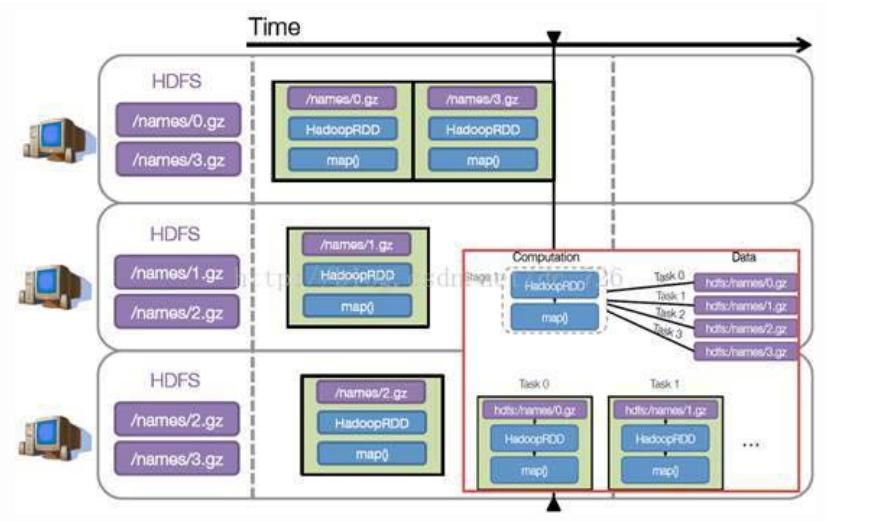
每个Task操作一块数据再执行,以上例子的简单模拟:
import org.apache.spark.{SparkConf, SparkContext}
object NameCountCh {
def main(args: Array[String]) {
if (args.length < 1) {
System.err.println("Usage:<File>")
System.exit(1)
}
val conf = new SparkConf().setAppName("NameCountCh")
val sc = new SparkContext(conf)
sc.textFile(args(0))
.map(name => (name.charAt(0), name))
.groupByKey()
.mapValues(names => names.toSet.size)
.collect().foreach(println)
}
}
实际执行过程截图:
执行命令: ./spark-submit --master spark://xxxx:7077 --class NameCountCh --executor-memory 512m --total-executor-cores 2 /data/spark/miaohq/scalaTestApp/scalatest4.jar hdfs://spark29:9000/home/miaohq/testName.txt
1、启动一个HTTP端口:

2、按照提交的文件将文件放到这个Web服务器上

3、创建程序生成两个Executor

4、DAG调度


完成第一stage:

调度第二stage:

完成第二个stage输出结果:
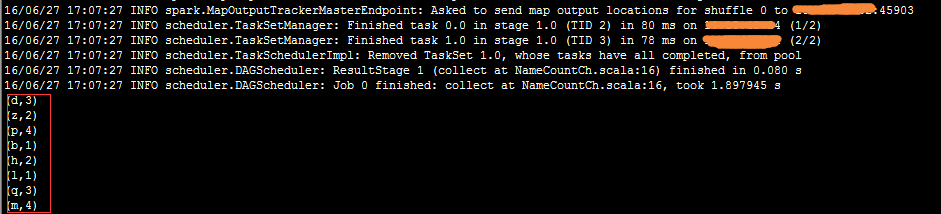
疑惑:
1、小文件看不出来文件分区的过程,另外设置了几个执行核,就会有几个Executor,如果超过总数可能要多线程了??
2、为什么一个stage是两个task,按照原理应该是文件分为几个partition就几个task,目前测试文件很小,只能分1个partition,也不是和Executor相关的,
设置了3个执行核心仍然只是两个task?
3、为什么从mapValues划分第二个stage不应该是 groupByKey()???
6、Standalone架构下Spark的执行
1、standalone是Spark实现的资源调度框架,有:Client节点、Master节点、Worker节点。
2、Driver即可运行在Master节点,也可以运行在本地的Client端。
用spark-shell交互工具提交Spark的job的时候,运行在Master节点;
用spark-submit 提交或者用sparkConf.setManager("Spark://master:7077")是运行在Client端。
3、运行在Client端的执行过程如下:

说明:
1)sparkContext连接到Master,注册并申请资源(cpu 和内存)
2)Master根据申请信息和Worker心跳报告决定在哪个主机上分配资源,然后获取资源,启动StandaloneExecutorBackend。
3)StandaloneExecutorBackend向sparkContext注册。
4)sparkContext发送代码给StandaloneExecutorBackend且根据代码,构建DAG。
遇到Action动作会生成一个Job,然后根据Job内部根据RDD依赖关系生成多个Stage,Stage提交给TaskScheduler,
5)StandaloneExecutorBackend在汇报状态时候获取Task信息调用Executor多线程执行task,且向sparkContext汇报,
直到任务完成。
6)所有Task完成后,SparkContext向Master注销,释放资源。
说明:
文章中图片和内容来自:http://www.cnblogs.com/shishanyuan