1、读写csv文件
import csv
import sys
input_file = sys.argv[1]
output_file = sys.argv[2]
with open(input_file, 'r') as csv_in_file:
with open(output_file, 'w') as csv_out_file:
filereader = csv.reader(csv_in_file, delimiter=',')
filewriter = csv.writer(csv_out_file, delimiter=',')
for row_list in filereader:
print(row_list)
filewriter.writerow(row_list)
2、筛选特定行
2.1 行中的值满足某个条件
基础python版:
import csv import sys input_file = sys.argv[1] output_file = sys.argv[2] with open(input_file, 'rU') as csv_in_file: with open(output_file, 'w') as csv_out_file: filereader = csv.reader(csv_in_file) filewriter = csv.writer(csv_out_file) header = next(filereader) #print header filewriter.writerow(header) for row_list in filereader: print row_list supplier = str(row_list[0]).strip() cost = str(row_list[3]).strip("$").replace(',', '') if supplier == 'Supplier X' or float(cost)>600.0: filewriter.writerow(row_list)
pandas版(主要用到了loc()函数)
import pandas as pd import sys input_file = sys.argv[1] output_file = sys.argv[2] data_frame = pd.read_csv(input_file) data_frame['Cost'] = data_frame['Cost'].str.strip('$').astype(float) data_frame_value_meets_condition = data_frame.loc[(data_frame['Supplier Name'].str.contains('X')) & (data_frame['Cost']>600.0), :] data_frame_value_meets_condition.to_csv(output_file, index=False)
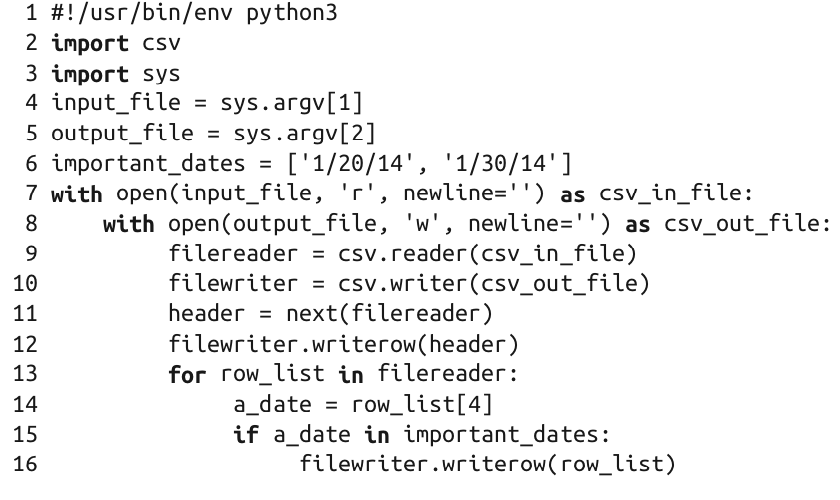
2.2 行中的值属于某个集合
基础python版:
pandas版:

2.3 行中的值匹配于某个正则表达式/模式
基础python版:
import csv import sys import re input_file = sys.argv[1] output_file = sys.argv[2] pattern = re.compile(r'(?P<my_pattern_group>^001-.*)', re.I) with open(input_file, 'rU') as csv_in_file: with open(output_file, 'w') as csv_out_file: filereader = csv.reader(csv_in_file) filewriter = csv.writer(csv_out_file) header = next(filereader) filewriter.writerow(header) for row_list in filereader: invoice_number = row_list[1] if pattern.search(invoice_number): filewriter.writerow(row_list)
pandas版:
import pandas as pd import sys input_file = sys.argv[1] output_file = sys.argv[2] data_frame = pd.read_csv(input_file) data_frame_value_matches_pattern = data_frame.loc[data_frame['Invoice Number'].str.startswith("001-"), :] data_frame_value_matches_pattern.to_csv(output_file, index=False)
3、筛选特定的列
3.1 列索引值
基础python版
import csv import sys input_file = sys.argv[1] output_file = sys.argv[2] my_columns = [0,3] with open(input_file, 'rU') as csv_in_file: with open(output_file, 'w') as csv_out_file: filereader = csv.reader(csv_in_file) filewriter = csv.writer(csv_out_file) for row_list in filereader: row_list_ouput = [] for index_value in my_columns: row_list_ouput.append(row_list[index_value]) filewriter.writerow(row_list_ouput)
pandas版
import sys import pandas as pd input_file = sys.argv[1] output_file = sys.argv[2] data_frame = pd.read_csv(input_file) data_frame_column_by_index = data_frame.iloc[:,[0,3]] data_frame_column_by_index.to_csv(output_file, index=False)
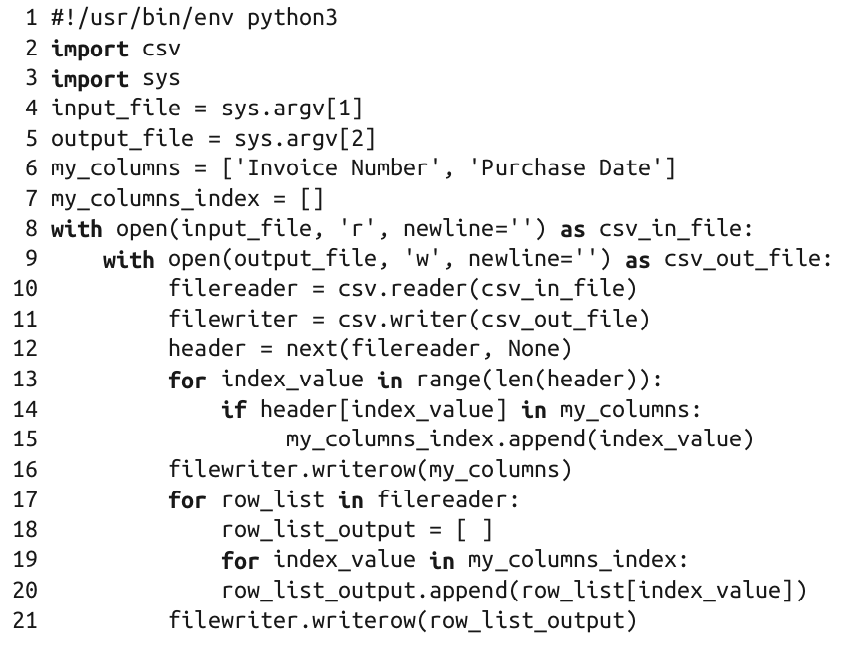
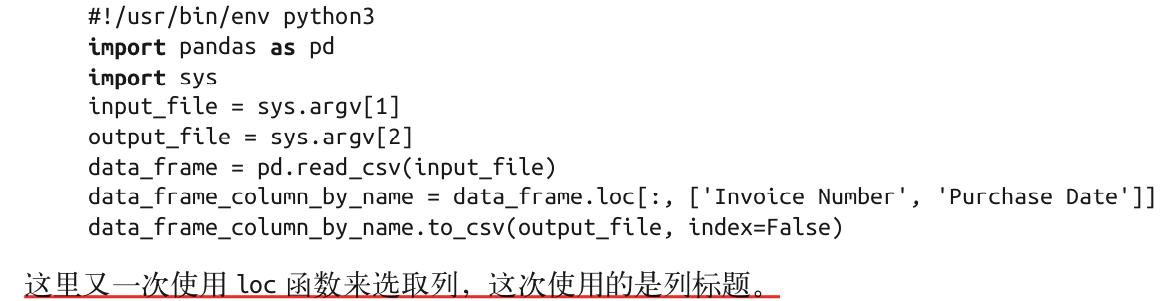
3.2 列标题
基础python版
pandas版
4、选定特定的行