HBase 和 Hive 的差别是什么,各自适用在什么场景中?
结论:Hbase和Hive在大数据架构中处在不同位置,Hbase主要解决实时数据查询问题,Hive主要解决数据处理和计算问题,一般是配合使用。
一、区别:
- Hbase: Hadoop database 的简称,也就是基于Hadoop数据库,是一种NoSQL数据库,主要适用于海量明细数据(十亿、百亿)的随机实时查询,如日志明细、交易清单、轨迹行为等。
- Hive:Hive是Hadoop数据仓库,严格来说,不是数据库,主要是让开发人员能够通过SQL来计算和处理HDFS上的结构化数据,适用于离线的批量数据计算。
- 通过元数据来描述Hdfs上的结构化文本数据,通俗点来说,就是定义一张表来描述HDFS上的结构化文本,包括各列数据名称,数据类型是什么等,方便我们处理数据,当前很多SQL ON Hadoop的计算引擎均用的是hive的元数据,如Spark SQL、Impala等;
- 基于第一点,通过SQL来处理和计算HDFS的数据,Hive会将SQL翻译为Mapreduce来处理数据;
二、关系
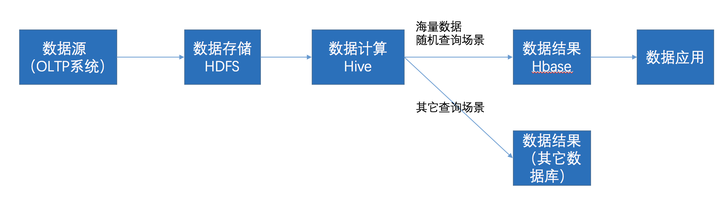
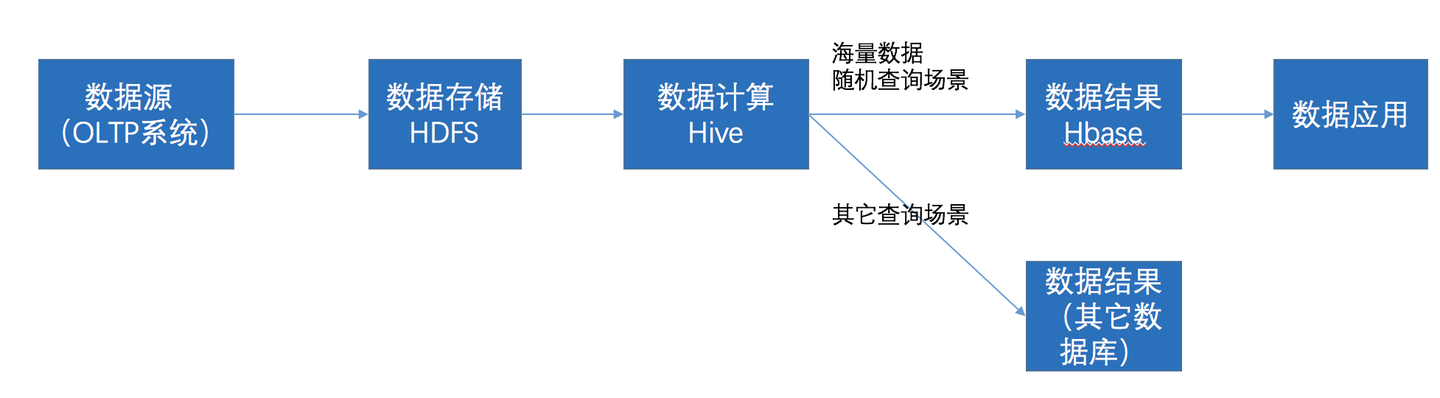
在大数据架构中,Hive和HBase是协作关系,数据流一般如下图:
- 通过ETL工具将数据源抽取到HDFS存储;
- 通过Hive清洗、处理和计算原始数据;
- Hive清洗处理后的结果,如果是面向海量数据随机查询场景的可存入Hbase
- 数据应用从HBase查询数据;
Spark SQL能做什么
根据ETL(数据的抽取、转换、加载)的三个过程来讲解一下Spark SQL的作用。
(1)抽取(Extract):Spark SQL可以从多种文件系统(HDFS、S3. 本地文件系统等)、关系型数据库(MySQL、Oracle、PostgreSQL等)或NoSQL数据库(Cassandra、HBase、Druid等)中获取数据,Spark SQL支持的文件类型可以是CSV、JSON、XML、Parquet、ORC、Avro等。得益于Spark SQL对多种数据源的支持,Spark SQL能从多种渠道抽取人们想要的数据到Spark中。
(2)转换(Transform):我们常说的数据清洗,比如空值处理、拆分数据、规范化数据格式、数据替换等操作。Spark SQL能高效地完成这类转换操作。
(3)加载(Load):在数据处理完成之后,Spark SQL还可以将数据存储到各种数据源(前文提到的数据源)中。
如果你以为Spark SQL只能做上面这些事情,那你就错了。Spark SQL还可以作为一个分布式SQL查询引擎通过JDBC或ODBC或者命令行的方式对数据库进行分布式查询。Spark SQL中还有一个自带的Thrift JDBC/ODBC服务,可以用Spark根目录下的sbin文件夹中的start-thriftserver.sh脚本启动这个服务。Spark中还自带了一个Beeline的命令行客户端,读者可以通过这个客户端连接启动的Thrift JDBC/ODBC,然后提交SQL。
如果你以为Spark SQL能做的只有这些,那你就错了。Spark SQL还可以和Spark的其他模块搭配使用,完成各种各样复杂的工作。比如和Streaming搭配处理实时的数据流,和MLlib搭配完成一些机器学习的应用。