准备:
1. 规划3个集群节点:
hosts主机都已经配置好映射,映射主机名分别为master,slave1,slave2,
且已经进行ssh免密配置,确保端口互通,防火墙关闭
2. 先安装好scala(参考:https://www.cnblogs.com/sea520/p/13518158.html)
一. 下载
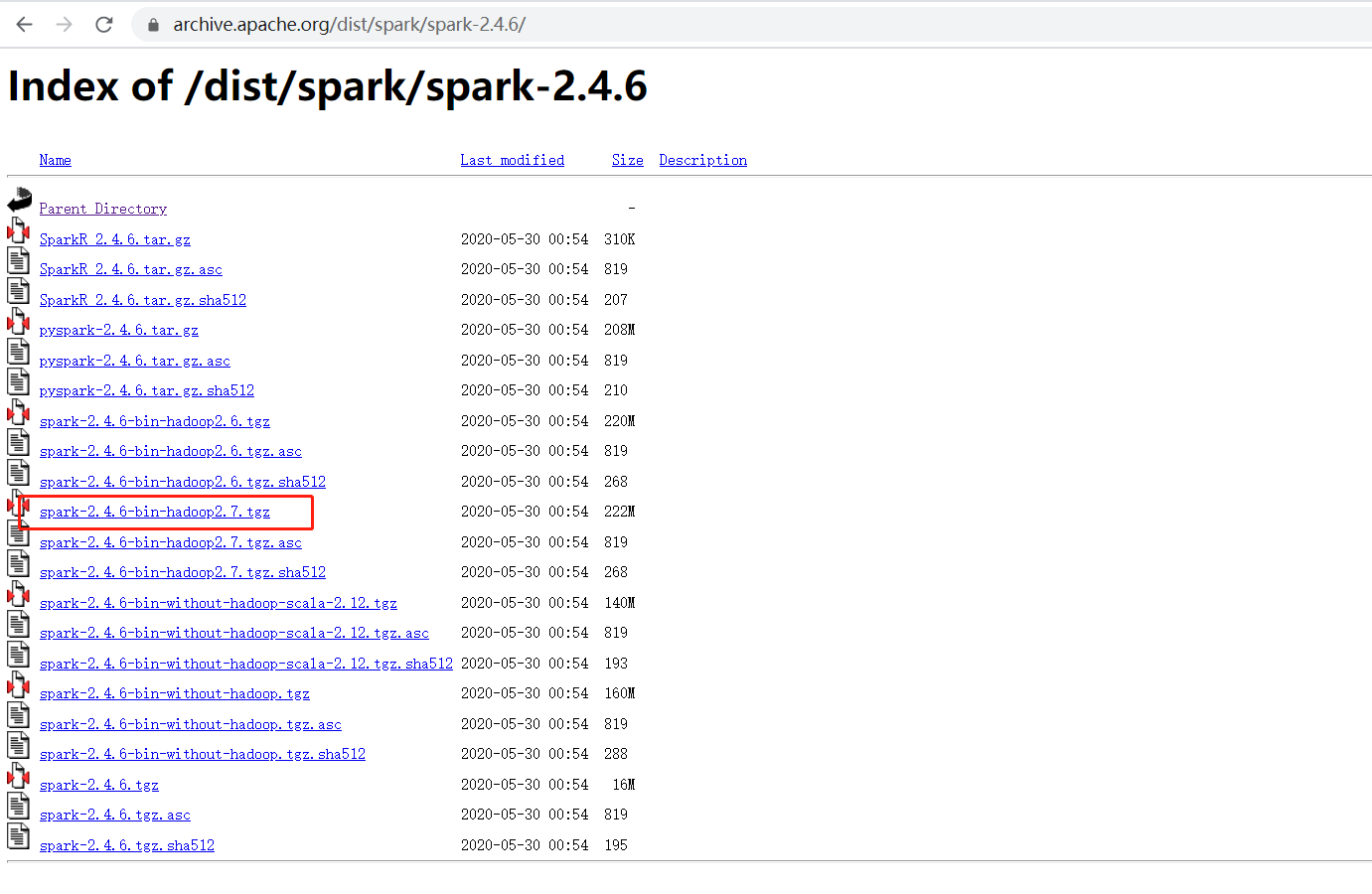
spark安装包下载地址:https://archive.apache.org/dist/spark/spark-2.4.6/
将下载的spark-2.4.6-bin-hadoop2.7.tgz上传到master机器目录
(参考:
开发源码与编译下载 https://github.com/apache/spark/tree/branch-2.4
官方的下载地址已经无法选择版本下载:http://spark.apache.org/downloads.html)
二. 安装
1.解压 (解压后主目录:/opt/soft/spark-2.4.6-bin-hadoop2.7)
tar -zxvf /opt/soft/download_jars/spark-2.4.6-bin-hadoop2.7.tgz -C /opt/soft/
2. 配置环境变量
3. 配置环境变量
3.1 打开 vim /etc/profile添加以下配置
# spark home
export SPARK_HOME=/opt/soft/spark-2.4.6-bin-hadoop2.7
export PATH=$SPARK_HOME/bin:$PATH
3.2 让环境变量立即生效
source /etc/profile
4. 修改Spark配置文件
spark配置文件模版在: cd ${SPARK_HOME}/conf/
主要修改两个配置文件:spark-env.sh和slaves
4.1 spark-env.sh修改:
# 复制模版
cp spark-env.sh.template spark-env.sh
# 添加配置 (请修改成你自己的各种目录环境,注意最后一个 HADOOP_CONF_DIR=你的hadoop主目录/etc/hadoop ,/etc/hadoop要保留哦)
vim spark-env.sh
export SCALA_HOME=/opt/soft/scala-2.13.3
export JAVA_HOME=/opt/soft/jdk1.8.0_261
export SPARK_MASTER_IP=master
export SPARK_WORKER_MEMORY=1g
export HADOOP_CONF_DIR=/opt/soft/hadoop-3.1.2/etc/hadoop
4.2 slaves修改
cp slaves.template slaves
vim slaves
# localhost
slave1
slave2
5. node节点分发(如果在内网,用内网IP比主机名快很多,主机名是映射的公网太慢)
scp -r /opt/soft/spark-2.4.6-bin-hadoop2.7 hadoop@172.17.0.5:/opt/soft/
scp -r /opt/soft/spark-2.4.6-bin-hadoop2.7 hadoop@172.17.0.13:/opt/soft/
6. 其他各node节点(slave1,slave2)分别配置环境变量与刷新环境变量(执行3.1,3.2两个步骤),
刷新profile文件使配置生效,验证安装是否OK
7.启动Spark集群
7.1启动前确定Hadoop集群已经启动。
7.2启动命令:
/opt/soft/spark-2.4.6-bin-hadoop2.7/sbin/start-all.sh
master节点进程:

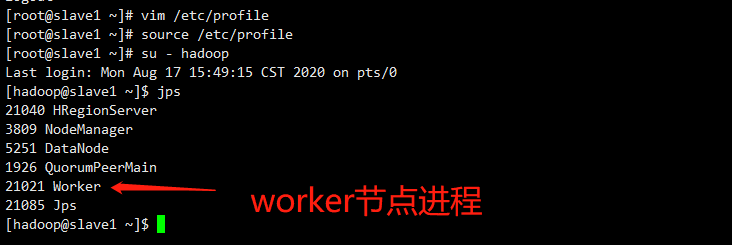
worker节点进程: